







实验目的
使用k-means聚类算法对矩阵元素进行分类
实验内容
编写程序,使用k-means聚类方法对已知数据进行聚类,然后对未知样本进行分类。数据自己进行模拟生成,要求为整数,样本个数至少为 100个,类别作为输入参数。
k-means 算法的基本思想:以空间k个点为中心进行聚类,对靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。最终的k各聚类具有以下特点:各聚类本身尽可能紧凑,而各聚类之间尽可能分开。
假设把样本集分为k个类别,算法描述如下:
- 适当选择k个类的初始中心。
- 在k次迭代中,对任意一个样本,求其到k个中心的聚类,将该样本归到距离最近的中心所在的类。
- 利用均值或其他算法更新该类的中心值。
- 对于所有的k个聚类中心,如果利用步骤2,3迭代更新后,值保持不变,则迭代结束,否则继续迭代。
该算法的最大优势在于简洁和快速,算法的关键在于预期分类数量的确定以及初始中心和距离公式的选择。
实验源代码
# 引入数据集,sklearn包含众多数据集
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# 引入iris鸢尾花数据,iris数据包含4个特征变量
iris = datasets.load_iris()
iris_X = iris.data # 特征变量
iris_y = iris.target # 目标值
# 将数据集划分为20%测试集和80%训练集
X_train, X_test, Y_train, Y_test = train_test_split(iris_X, iris_y,
test_size=0.2)
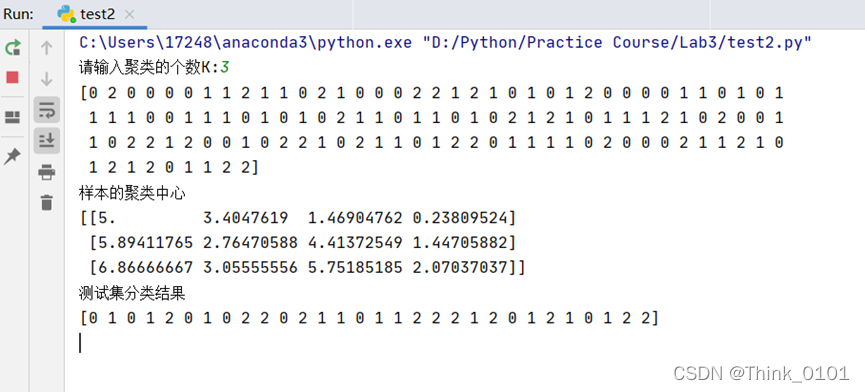
num = int(input("请输入聚类的个数K:"))
kmeans = KMeans(n_clusters=num, random_state=None).fit(X_train)
print(kmeans.labels_)
print("样本的聚类中心")
print(kmeans.cluster_centers_)
print("测试集分类结果")
print(kmeans.predict(X_test))
# 通过PCA算法进行数据降维,可以2维显示
reduced_data = PCA(n_components=2).fit_transform(iris_X)
kmeans = KMeans(init="k-means++", n_clusters=num)
kmeans.fit(reduced_data)
# Step size of the mesh. Decrease to increase the quality of the VQ.
h = .02 # point in the mesh [x_min, x_max]x[y_min, y_max].
# Plot the decision boundary. For that, we will assign a color to each
x_min, x_max = reduced_data[:, 0].min() - 1, reduced_data[:, 0].max() + 1
y_min, y_max = reduced_data[:, 1].min() - 1, reduced_data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Obtain labels for each point in mesh. Use last trained model.
Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(Z, interpolation="nearest",
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.Paired, aspect="auto", origin="lower")
plt.plot(reduced_data[:, 0], reduced_data[:, 1], 'k.', markersize=2)
# Plot the centroids as a white X
centroids = kmeans.cluster_centers_
plt.scatter(centroids[:, 0], centroids[:, 1], marker="x", s=169, linewidths=3,
color="w", zorder=10)
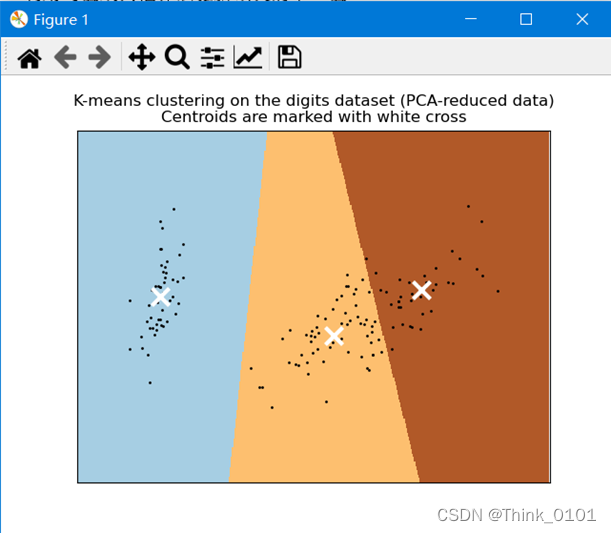
plt.title("K-means clustering on the digits dataset (PCA-reduced data)\n"
"Centroids are marked with white cross")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
结果截图
小结
通过调用python的sklearn库中的K均值函数,通过查看其官方文档,了解一些常用的函数和参数设置,通过文档中的参考用例,编写了用sklearn库中自带的数据集Iris,来聚类。但是奇怪的是,并没有发现函数参数中有距离公式的选择,后面查资料,好像是,k-means默认使用欧氏距离,这是算法设计之初的度量基础。原因是算法涉及平均值的计算。其中的n_cluster维聚类的个数,默认为8,init参数为可调用初始化方法,当init=’k-means++’时,模型以智能的方式选择初始化聚类中心加速收敛。后面通过主成分分析方法对数据进行降维,也参考了文档中的例子,将聚类结果图形化展示在2维坐标中。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









