







“物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异。聚类和分类的区别:分类是已知类别的,聚类未知类别
目录
2,WCSS(Within-Cluster Sum of Squares) 簇内平方和评估
一、K-means
1,算法流程
K-means聚类的算法流程:

图解过一遍:

1)计算各点与各重心间的距离
2)将最近的重心所在簇作为该点所属的簇

(3) 计算每个簇的平均值,作为其重心

(4) 重复步骤2和步骤3
2,WCSS(Within-Cluster Sum of Squares) 簇内平方和评估
WCSS 随着簇的增加而变小,所以可以用于相同数量的簇的情况下的比较。WCSS 指的是对所有簇计算其所属的数据点与簇的重心之间距离的平方和,并将它们相加得到的值。这个值越小,说明聚类效果越好。
随着簇的增加,WCSS 会变小,但有时 WCSS 的变小幅度会从簇的数量为某个值时开始放缓。通过使用 Elbow 方法,可以确定合理的簇的数量。
def WCSS_(X, M, P):
# X:numpy二维数组,形状是(n,k),表示n个样本属性。
# M:numpy二维数组,形状是(m,k),表示m个聚类中心。
# P:numpy一维数组,形状是(n,),表示聚类类别,每个值的取值范围是[0,m-1]的整数。
m = M.shape[0]
WCSS = 0
for i in range(m):
WCSS += ((X[P==i] - M[i])**2).sum()
return WCSS3,题目复习
1,EG1

B注意是负的WCSS
2,EG2

有n条数据,代表要计算n条数据,n条数据的k个特征与m重心间的距离
选D
3,EG3

这要通过每个数据到每个中心的距离进行比较,距离小的归属哪个中心,这样就有n个点距离和m个中心进行比较,需要进行n*m次
4,EG4
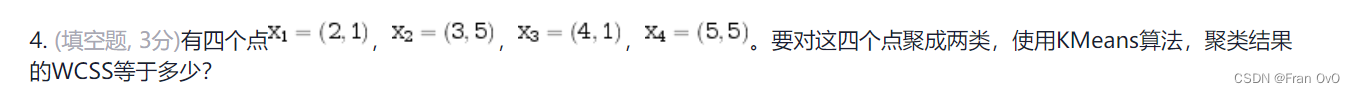
这题就没必要初始化中心点去搞了,画个图很直观看得出两个类的中心点(4,5)和(3,1)吧
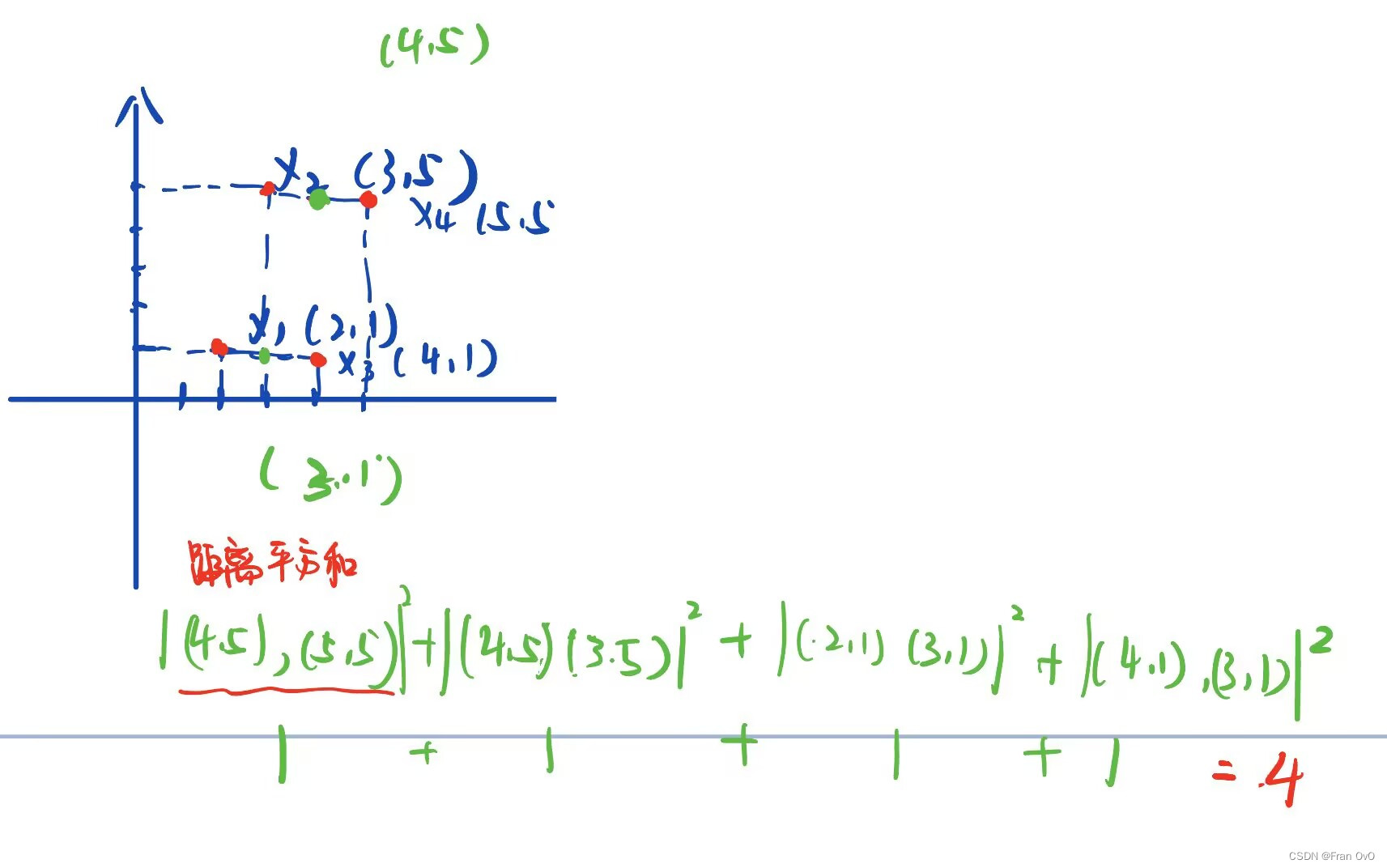
5,EG5
时间复杂度太大

二、K-means使用
1.sklearn库对鸢尾花(iris)数据集的聚类
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
iris = load_iris()
n_clusters = 3 # 将簇的数量设置为3
model = KMeans(n_clusters=n_clusters)
model.fit(iris.data)
print(model.labels_) # 各数据点所属的簇
print(model.cluster_centers_) # 通过fit()计算得到的重心
print("score:", -model.score(iris.data))2.手肘法ELBOW
手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。
并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
iris = load_iris()
n_list = [i for i in range(2,11)]
scores = []
for n_clusters in n_list:
model = KMeans(n_clusters=n_clusters)
model.fit(iris.data)
scores.append(-model.score(iris.data))
scores = np.array(scores)
plt.plot(n_list, scores) 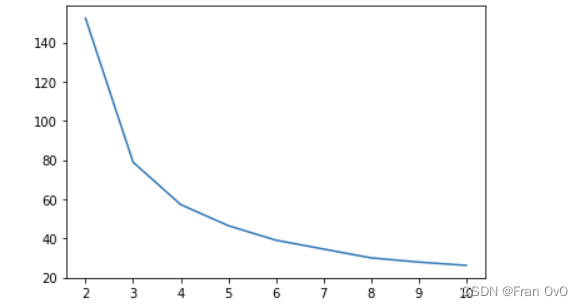
3,应用——图像压缩
from PIL import Image
# 导入图片
origin_img = np.array(Image.open('/data/bigfiles/tree.jpg'), dtype=float)/255
# 查看原始图片
plt.imshow(origin_img)
plt.axis('off')
![]()
from sklearn.utils import shuffle
from sklearn.cluster import KMeans
# 变成 二维矩阵,第一维是所有像素点,第二维是3种颜色通道
img_flattened = origin_img.reshape(height*width, 3)
image_array_sample = shuffle(img_flattened)[:1000] # 随机取1000个点。
model = KMeans(n_clusters=64)
model.fit(image_array_sample) # 通过聚类分析,得到64个点
# 将64个聚类点记录起来,命名为 “调色板” (palette)
palette = model.cluster_centers_
print(palette.shape) # 64种颜色
# 计算所有颜色最接近的颜色号
cluster_assignments = model.predict(img_flattened)
print(cluster_assignments)
# 根据颜色号取出相应颜色作为像素点的颜色
compressed_image = np.array([palette[i] for i in cluster_assignments], dtype=float)
# 将像素列表回复成图像
compressed_image = compressed_image.reshape(height, width, depth)
# 查看压缩后的图片
plt.imshow(compressed_image)
plt.axis('off') 
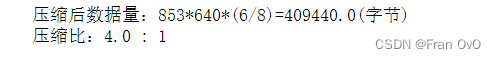















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









