






Boosting Robustness of Image Matting with Context Assembling and Strong Data Augmentation
中文题目 利用上下文组合和强数据增强的增强鲁棒图像抠图
paper:https://openaccess.thecvf.com/content/CVPR2022/papers/Dai_Boosting_Robustness_of_Image_Matting_With_Context_Assembling_and_Strong_CVPR_2022_paper.pdf
code:Null
摘要
深度图像抠图方法在很多数据集上已经得到了较好的结果。但是鲁棒性仍缺乏探究,包括trimaps和从不同域中生成图像的鲁棒性。尽管一些工作建议通过额外的数据增强来改进trimap或使算法适应真实世界的图像,但没是有人同时考虑到这两点。而且在使用这些数据增强时,基准测试的性能显著下降。为了填补这一空白,我们提出了一种具有更高鲁棒性的图像抠图方法(RMat)通过多级上下文组合和强数据增强目标抠图。具体来说,我们首先通过在编码器中使用Transformer块建模大量的全局信息来构建一个强大的matting框架,并结合卷积层以及解码器中的浅层特征集成到注意块来关注细节。然后,基于这个强基线,我们分析了当前的数据增强,并探索了简单而有效的强数据增强来增强基线模型,并贡献了一种更通用的抠图方法。使用上下文组合和强数据增强基准提高图像抠图的鲁棒性(在SAD上提高11%,在Grad上提高27%),模型尺寸更小,但在其他基准上也显示出更多健壮的泛化结果。在真实世界的图像上,我们也在不同的粗到细的trimap上进行了大量的实验
动机
为了探究是否有可能用更简单有效的方法来增强抠图算法的上下文建模能力(鲁棒性)和具有较好的领域泛化能力的模型,本文提出了一种鲁棒性更强的抠图方法(RMat),该方法对不同trimap精度具有更高的鲁棒性,对不同领域具有更好的泛化能力。具体设计分为两个步骤。第一步是使用多级上下文组合构建一个强大的基线模型。它通过将Transformer块与卷积层结合来实现,其中全局上下文通过自注意模块学习,局部上下文由卷积层强调。考虑到抠图需要局部上下文信息和原始测试分辨率来捕获细节的唯一性,我们探索了针对该任务的设计和实现的有效的模型。此外,在这个强基线模型的基础上,我们研究了抠图的强数据增强。我们分析了当前增强背后的问题,并提出了专门用于抠图的强增强策略。最后,为了验证模型的鲁棒性,进行了一系列的实验和可视化,并与最先进的方法进行了比较。
创新点
(1)多层级上下文组合的强抠图框架
(2)应用于抠图的强数据增强策略
(3)实验和可视化设计验证抠图模型的泛化能力
(4)最先进的基准测试结果(w/和w/o拟合训练集),对不同trimap精度有更高鲁棒性,以及对真实世界图像有更好的泛化能力。
方法论
Encoder Design
编码器包含两个分支,一个Transformer分支模拟全局上下文信息,一个卷积分支补充浅层的细节信息。
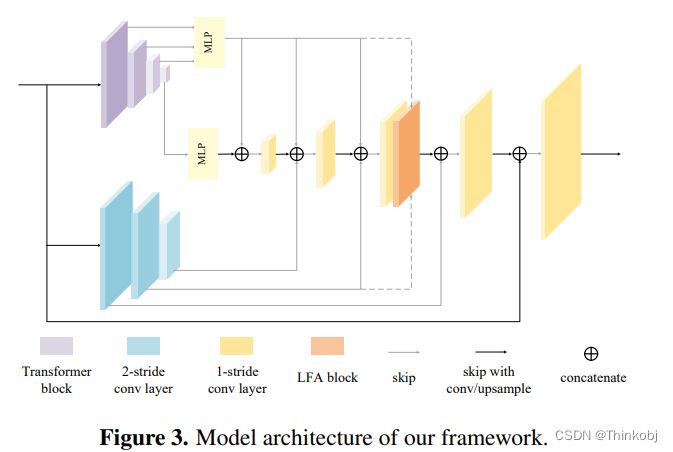
Decoder Design
由于编码器中的Transformer分支具有较大的能力和全局接收域,并且为了减少计算量,我们只考虑在基本解码器中使用MLP层和卷积层。它们还可以很好地组合多层上下文信息
Feature Skip Design
(1)Transformer分支(Tskip)的跳连接,这些特征图在恢复分辨率的同时传输了丰富的全局信息。
(2)卷积分支(LSkip),补充原本像素的细节信息。
Low-Level Feature Assembling Attention Block (LFA) Design
浅层特征能力精细化解码器特征,本文使用Transformer块有效的组合浅层特征。将原本的 A t t n ( Q , K , V ) Attn(Q,K,V) Attn(Q,K,V)替换为 A t t n ( f l o w , f l o w , f d ) Attn(f_{low},f_{low},f_d) Attn(flow,flow,fd),其中 f l o w f_{low} flow表示从编码器跳过来的特征, f d f_d fd表示解码器将要细化的特征。只在1/4像素的解码器层增加LFA块。
Domain Generalization and Data Augmentation for Image Matting 图像抠图中的域泛化和数据增强
因为训练的图像是合成的,所以跟真实世界存在域泛化的问题。而Transformer模型很容易导致过拟合,特别是在数据集很小的情况下。为了解决这个问题,本文研究强数据增强(strong augmentation, SA)来增强泛化能力。有些数据增强方法在让baseline的效果下降,主要是由于增强后的图像会损失一些结构,使得跟GT不能完全匹配。
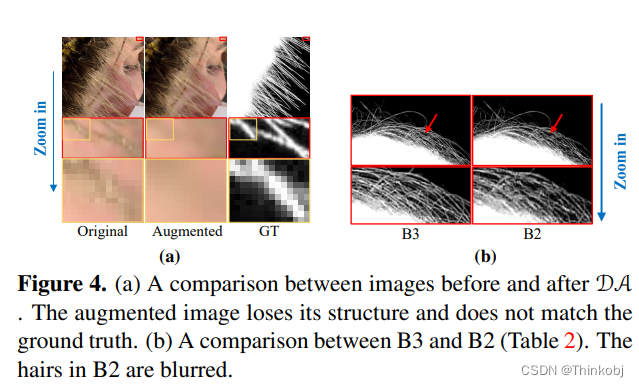
修改对应的GT,让其与数据增强后的图像匹配,本文做了一个消融实验。从Table 1可以看出,修改后的结果有一定的提升。
真实的图像与合成图像的差异主要体现在:
1)真实的图像背景比较复杂
2)真实图像中前景与背景同域,合成图像不同域
3)真实图像存在未聚焦边界、模糊区域,由于图像压缩而出现的马赛克
在本文中,依靠网络通过组合多层上下文信息来处理上下文域差距。对于剩余的特征级差距,我们研究了简单但有效的强增强策略,以更好地将算法推广到现实世界的图像。
Strong Data Augmentation for Matting
- Linear Pixel-Wise Augmentation线性像素级增强
线性数据增强可以表示为:
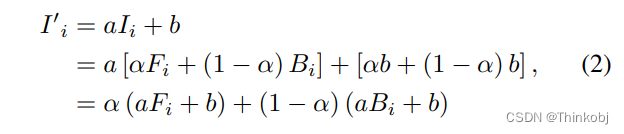
而在一张图像上的增强可以表示为在对应的前景和背景上单独处理:
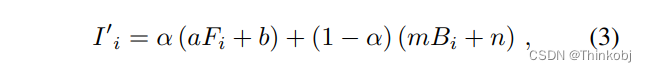
线性对比度(linear contrast),亮度调节(brightness adjustment),噪音(noise)等。
- Nonlinear Pixel-Wise Augmentation
非线性增强:如伽马校正(gamma correction),色相(hue)/饱和度调整(saturation adjustment)等。违背抠图公式
- Region-Wise Augmentation
区域级增强,如模糊(blur)、jpeg压缩(jpeg compression)等。违背抠图公式
基于以上分类,本文提出了强数据增强策略。
1)只增强前景(AF)
只对前景做random jitter。无论采用哪种增强,基本真理都不需要修改,因为它发生在合成之前。
2)单独增强前景和背景(AFB)
3)增强合成图像(AC)
若使用线性数据增强,则满足抠图公式
若使用其它策略,需要获取新的GT。本文的策略是通过旋转或通道变换输入来预测伪标签,从而生成一个新的训练样本。
Loss function
L1 alpha prediction loss 和 composition loss。本文定义了一个新的梯度损失
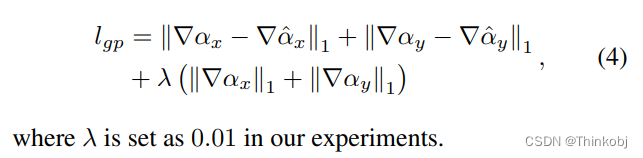
结果
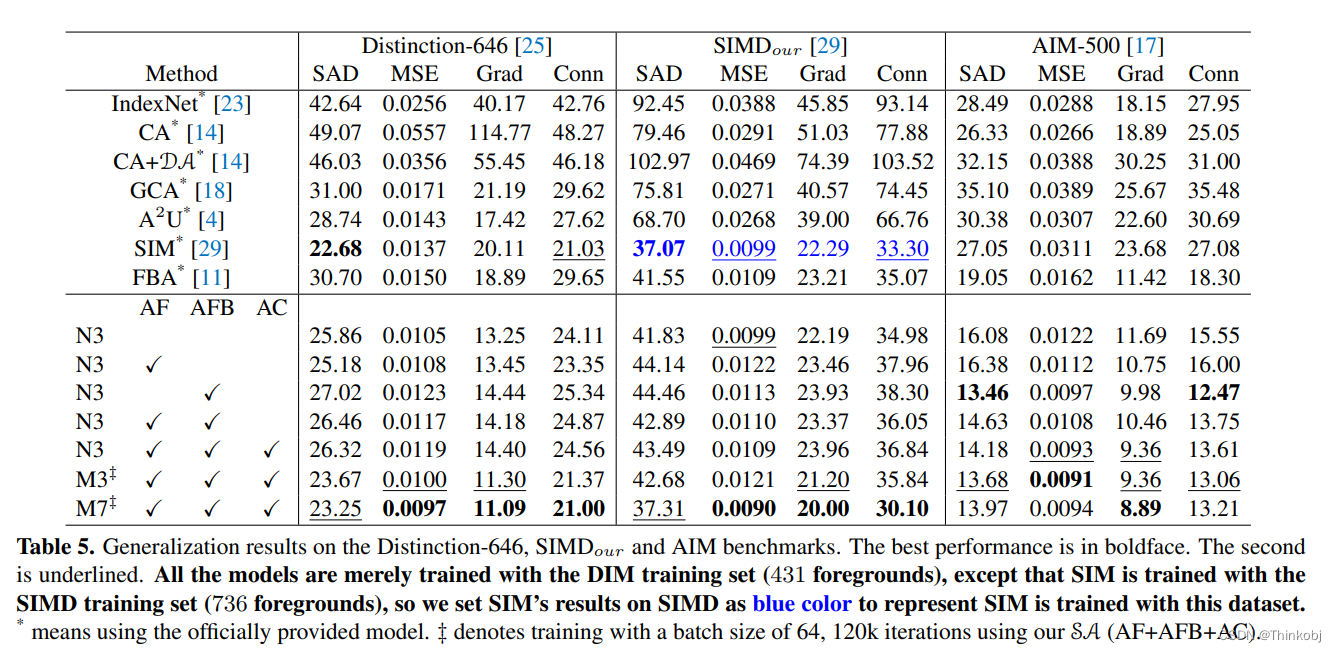
在不同的数据集上都得到了比较好的结果。
总结
本文提出了一种对不同trimap精度和不同域图像具有更高鲁棒性的抠图方法。该方法包括一个新的抠图框架和专门为抠图设计的强数据增强策略。首先通过组合多层上下文信息来构建强基线,然后分析当前数据增强背后的问题并设计强增强策略。该方法的结果超过了目前的SOTA方法。这篇论文就是实验做得比较充分,消融实验做得比较多,对于强数据增强策略角度还可以。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









