







在/mmsegmentation-master/mmseg/datasets路径下新建一个mydataset.py文件
# Copyright (c) OpenMMLab. All rights reserved.
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class MyDataset(CustomDataset):
"""My Dataset.
"""
CLASSES = ('background', 'alpha') # 需要修改的地方
PALETTE = [[0, 0, 0], [255, 255, 255]] # 需要修改的地方
def __init__(self, **kwargs):
super(MyDatasetDataset, self).__init__(
img_suffix='.png', # 需要修改的地方
seg_map_suffix='.png', #需要修改的地方
reduce_zero_label=False,
**kwargs)
assert self.file_client.exists(self.img_dir)
同时在/mmsegmentation-master/mmseg/datasets中的____init____.py添加刚刚新建的数据集
# Copyright (c) OpenMMLab. All rights reserved.
from .ade import ADE20KDataset
from .builder import DATASETS, PIPELINES, build_dataloader, build_dataset
from .chase_db1 import ChaseDB1Dataset
from .cityscapes import CityscapesDataset
from .coco_stuff import COCOStuffDataset
from .custom import CustomDataset
from .dark_zurich import DarkZurichDataset
from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
RepeatDataset)
from .drive import DRIVEDataset
from .hrf import HRFDataset
from .isaid import iSAIDDataset
from .isprs import ISPRSDataset
from .loveda import LoveDADataset
from .night_driving import NightDrivingDataset
from .pascal_context import PascalContextDataset, PascalContextDataset59
from .potsdam import PotsdamDataset
from .stare import STAREDataset
from .voc import PascalVOCDataset
from .mydataset import MyDataset # 需要修改的地方
__all__ = [
'CustomDataset', 'build_dataloader', 'ConcatDataset', 'RepeatDataset',
'DATASETS', 'build_dataset', 'PIPELINES', 'CityscapesDataset',
'PascalVOCDataset', 'ADE20KDataset', 'PascalContextDataset',
'PascalContextDataset59', 'ChaseDB1Dataset', 'DRIVEDataset', 'HRFDataset',
'STAREDataset', 'DarkZurichDataset', 'NightDrivingDataset',
'COCOStuffDataset', 'LoveDADataset', 'MultiImageMixDataset',
'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset', 'MyDataset', # 需要修改的地方
]
在/mmsegmentation-master/mmseg/core/evaluation下的class_names.py文件也需要进行更改:
def mydataset_classes():
return ['background', 'alpha'] # 需要添加
def mydataset_palette():
return [[0, 0, 0], [255, 255, 255]] # 需要添加
数据集更改完成,还需要更改config文件下的模型文件,可以在______base__/models目录下修改对应的模型文件,以deeplabv3_unet_s5-d16.py为例
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained=None,
backbone=dict(
type='UNet',
in_channels=3,
base_channels=64,
num_stages=5,
strides=(1, 1, 1, 1, 1),
enc_num_convs=(2, 2, 2, 2, 2),
dec_num_convs=(2, 2, 2, 2),
downsamples=(True, True, True, True),
enc_dilations=(1, 1, 1, 1, 1),
dec_dilations=(1, 1, 1, 1),
with_cp=False,
conv_cfg=None,
norm_cfg=norm_cfg,
act_cfg=dict(type='ReLU'),
upsample_cfg=dict(type='InterpConv'),
norm_eval=False),
decode_head=dict(
type='ASPPHead',
in_channels=64,
in_index=4,
channels=16,
dilations=(1, 12, 24, 36),
dropout_ratio=0.1,
num_classes=2, # 可能需要修改
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)), # 可能需要修改
auxiliary_head=dict(
type='FCNHead',
in_channels=128,
in_index=3,
channels=64,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=2, # 可能需要修改
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)), # 可能需要修改
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='slide', crop_size=256, stride=170))
修改batch和train/val/test路径,在______base__/datasets目录下新建mydataset.py
# dataset settings
dataset_type = 'MyDataset' # 需要修改,对应mmseg/datasets中的____init____.py导入数据集
data_root = 'data/mydataset' # 需要修改,存放的数据集路径
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
img_scale = (2336, 3504) # 需要修改,指定图像的尺寸
crop_size = (256, 256) # 需要修改,裁剪图像的尺寸
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=img_scale,
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type='RepeatDataset',
times=40000,
dataset=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/training',
ann_dir='annotations/training',
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=test_pipeline))
在configs/unet目录下新建一个deeplabv3_unet_s5_d16_256x256_40k_mydataset.py写配置文件
_base_ = [
'../_base_/models/deeplabv3_unet_s5-d16.py', '../_base_/datasets/mydataset.py',
'../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
]
model = dict(test_cfg=dict(crop_size=(256, 256), stride=(170, 170)))
evaluation = dict(metric='mDice')
然后进行训练
python3 ./tools/train.py ./configs/unet/deeplabv3_unet_s5_d16_256x256_40k_mydataset.py
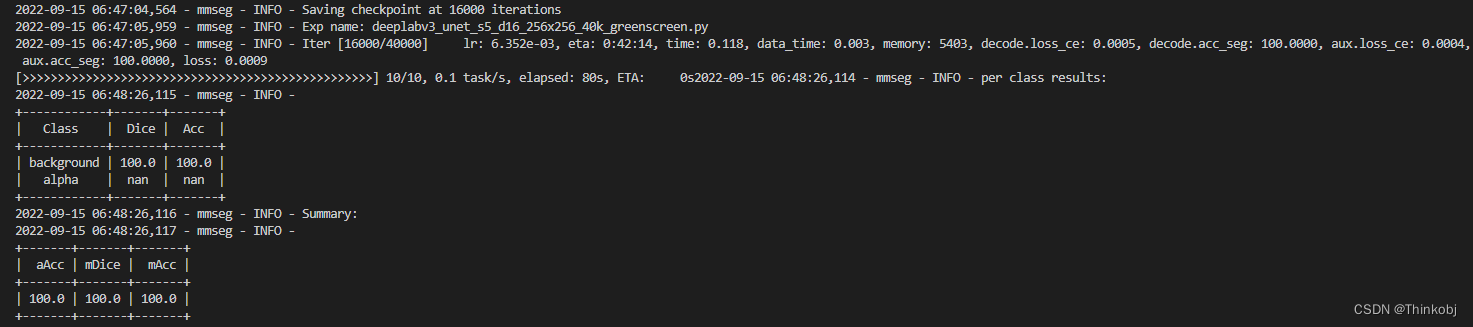
进行测试
python3 ./tools/test.py ./configs/unet/deeplabv3_unet_s5_d16_256x256_40k_mydataset.py ./work_dirs/deeplabv3_unet_s5_d16_256x256_40k_mydataset/epoch_1.pth --show-dir=./work_dirs/gs_results --with_depth=True
得到测试图片的效果


















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









