







TransMatting: Enhancing Transparent Objects Matting with Transformers
TransMatting: 使用Transformers增强透明物体抠图
paper: https://arxiv.org/pdf/2208.03007v3.pdf
code: https://github.com/AceCHQ/TransMatting
摘要
图像抠图是指从自然图像中预测未知前景区域的alpha值。先前的方法集中于将alpha值从已知区域传播到未知区域。然而,并不是所有的自然图像都有一个特定的已知前景。透明物体(如玻璃 ,烟,网格等)的图片很少或没有已知的前景。在本文中,作者提出了基于Transformer的网络,TransMatting。它使用一个大感受野建模透明物体。具体来说,我们将trimap重新设计为tri-tokens,以便将高级语义特征引入到自注意机制中。本文提出了一种小型卷积网络,利用全局特征和非背景掩码来引导多尺度特征从编码器到解码器的传播,以保持透明对象的上下文。另外,作者采集了一个小型已知前景透明物体的抠图数据集。实验表明本文所提出的方法在几个抠图的基线上都优于当前的SOTA方法。
动机
抠图的标准公式 I = α F + ( 1 − α ) B , B ∈ [ 0 , 1 ] I=αF+(1-α)B,B∈[0,1] I=αF+(1−α)B,B∈[0,1],其中I是已知的,而F,B和alpha都是未知的,所以这是一个病态的公式。因此很多现有的方法使用trimap作为辅助输入。大多数传统方法(包括基于采样的方法和基于传播的方法)高度依赖于已知的前景区域。最近,基于学习的方法利用神经网路直接预测alpha图。但是,有文献指出由于神经网络的感受野有限,超过50%像素的未知区域不能与已知区域相关联。玻璃,篝火和塑料袋等的图片虽然有显著的前景,但是它们是透明的或有细致的内部结构。而网格、烟和水滴等的图像没有显著前景。所以这种类型的图像的trimap将有很少甚至没有前景区域。大部分区域将被分为未知区域。但是(1)用极少的已知信息建模大尺度的特征非常有挑战(2)现有模型的感受野不能随着输入图像分辨率的增加而增加
为了解决上述两个问题,本文首次引入ViT。为了进一步帮助模型整合低层外观特征(如纹理)和高级语义特征(如形状),提出了一个多尺度全局引导融合(MGF)模块。MGF以三个相邻的特征尺度作为输入,利用非背景掩码对底层特征进行引导,利用高层特征对信息集成进行引导。有了这个新的MGF模块,只有前景特征可以传输到解码器,减少了背景噪声的影响。
然而trimap中的大多数区域都具有相同的值,使得小kernels的卷积神经网络不能有效的提取特征。因此本文引入了tri-token map。三个科学系的token表示前景,背景和位置区域。有了这些高级位置信息,Transformer模块可以识别哪些特征来自已知区域,哪些来自未知区域。
创新点
(1)提出了一个TGTB模块,引入Vision Transformer提取具有大感受野的全局语义特征。我们还将trimmap重新设计为一个tri-token图,以直接将位置信息带到自注意机制。
(2)提出了一种集成多尺度特征的MGF模块,它能够将全局信息与浅层Transformer特征进行整合。
(3)建立了一个460张透明和非显著前景的数据集。
(4)在三个抠图数据集上的表现性能优于其它的SOTA方法。
方法论
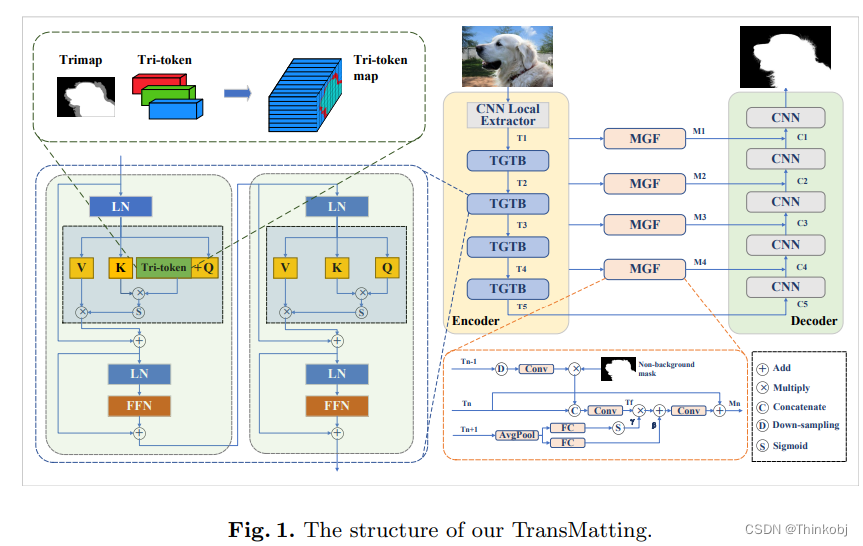
(1)基本结构
为了提取局部和全局特征,我们将CNN和Transformer模型结合起来作为编码器。具体地说,第一部分如与ResNet34-UNet的前两个阶段(在中称为CNN Local Extractor)相同。第二部分由我们提出的基于Swin Transformer中的Tri-token Guided Transformer Block 堆叠而成。解码器采用原本的ResNet34-UNet
(2)Tri-token
对于一个给定的 T r i m a p ∈ R H × W Trimap∈R^{H×W} Trimap∈RH×W,我们生成三个可学习的tri-tokens,其中每一个tri-token表示一个1D的向量,也就是说 T o k e n i ∈ R C Token_i∈R^C Tokeni∈RC,每个tri-token图的生成公式为:
T r i m a p [ T r i m a p = = i ] = T o k e n i , i = { 0 , 1 , 2 } Trimap[Trimap==i]=Token_i,i=\left \{0,1,2 \right \} Trimap[Trimap==i]=Tokeni,i={0,1,2}
(3) Tri-token Guided Transformer Block
将原本的Attention公式进行了改进,增加了Tri-token进去
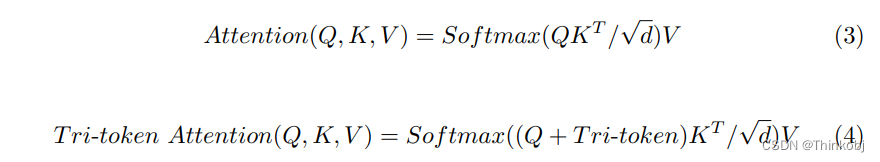
(4) Multi-scale Global-guided Fusion Module
在多尺度特征金字塔结构中,深度特征包含更多的全局信息,而浅层特征包含丰富的局部信息。单纯的使用sum操作能够实现特征融合,但是浅层特征中的细节可能会削弱高级语义的影响,导致一些微妙的区域缺失。因此设计了Multi-scale Global-guided Fusion Module(MGF)
细节部分从图1可知,就是设计了一个模块融合三个不同尺度的信息,其实感觉跟设计Attention那些差不多。而使用sum也可以得到相同的结果,后面也没有实验设置,有待考究。
(5) Loss Function
使用的损失函数很常规,不赘述
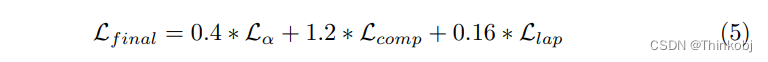
结果
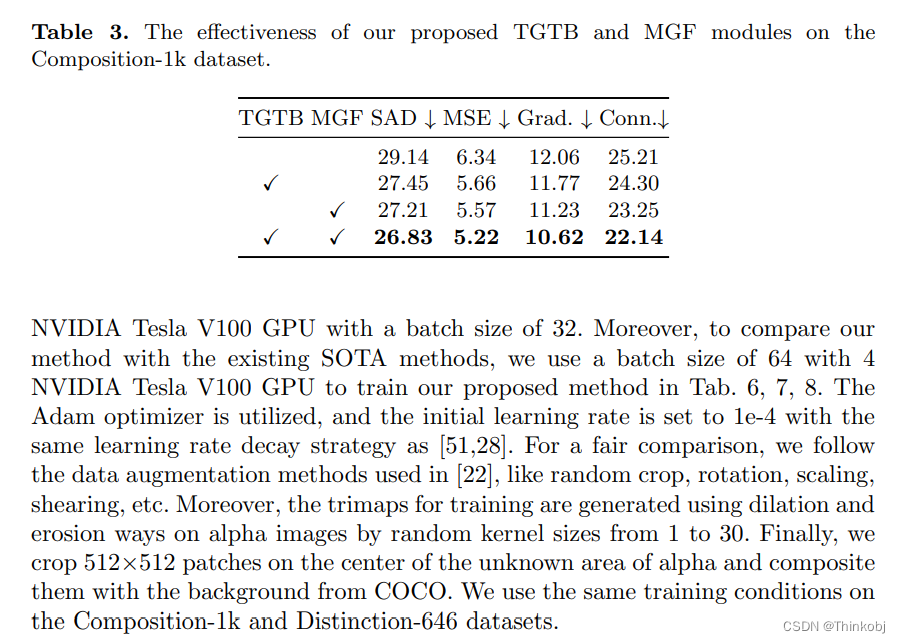
实验结果表明,本文的方法得到的结果要优于其它SOTA方法
总结
在Transformer中加入Tri-token的这个想法还是蛮有趣的,其它的比如MGF感觉有点像Attention类似的堆砌,其真实的有效性还需要进一步的考究。而新增一个透明物体的数据集,算是对社区一个比较大的贡献,不过并未完全开源,作者给了要数据的链接,看看能不能要到玩一玩。而目前的代码还没有开源,敬候佳音吧。














 2324
2324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









