










文章目录
混淆矩阵(Confusion Matrix)是分类模型性能评估的常用工具,它以矩阵的形式展示了模型在预测时的结果,特别是它在哪些类别上做得好,在哪些类别上做得不好。混淆矩阵能够清晰地显示模型分类错误的类型,有助于分析和改进模型。
一、混淆矩阵的基本构成
对于一个二分类问题,混淆矩阵通常是一个 2x2 的矩阵,包含以下四个部分:
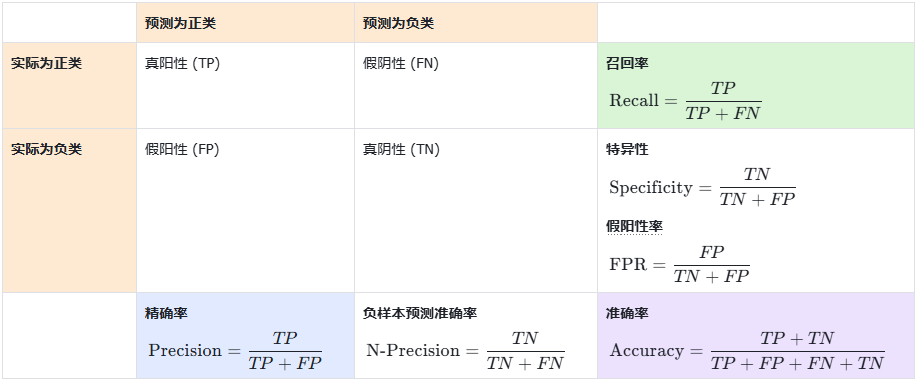
- 真阳性(True Positive, TP):模型将实际为正类的样本正确预测为正类。
- 假阴性(False Negative, FN):模型将实际为正类的样本错误预测为负类。
- 假阳性(False Positive, FP):模型将实际为负类的样本错误预测为正类。
- 真阴性(True Negative, TN):模型将实际为负类的样本正确预测为负类。
二、多分类混淆矩阵
对于多分类问题,混淆矩阵的维度是 N × N N \times N N×N,其中 N N N 是类别的数量。矩阵的行表示实际类别,列表示预测类别,矩阵中的每个元素表示模型在对应类别上的预测结果。
例如,考虑一个有三个类别(A, B, C)的多分类问题,混淆矩阵的形状为 3x3,如下:
| 预测为 A | 预测为 B | 预测为 C | |
|---|---|---|---|
| 实际为 A | 50 | 5 | 3 |
| 实际为 B | 10 | 60 | 2 |
| 实际为 C | 3 | 4 | 70 |
在这个矩阵中:
- 第一个行表示实际为 A 类的样本,第二个行表示实际为 B 类的样本,第三个行表示实际为 C 类的样本。
- 预测为 A 类的样本数目在第 1 列,预测为 B 类的样本数目在第 2 列,预测为 C 类的样本数目在第 3 列。
- 每个元素表示模型在该类别上的预测结果。例如,矩阵中的元素
50表示实际为 A 类的样本中有 50 个被正确地预测为 A 类。
三、混淆矩阵相关指标
混淆矩阵可以用于计算多种分类性能指标,如下所示:
1. 准确率(Accuracy)
准确率是最常用的分类性能评估指标之一,它衡量模型在所有样本中正确预测的比例:
Accuracy
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
\text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN}
Accuracy=TP+TN+FP+FNTP+TN
2. 精确率(Precision)
精确率是指在所有被模型预测为正类的样本中,实际为正类的比例。它表示了模型预测为正类时的“可信度”:
Precision
=
T
P
T
P
+
F
P
\text{Precision} = \frac{TP}{TP + FP}
Precision=TP+FPTP
3. 召回率(Recall)
召回率是指在所有实际为正类的样本中,模型预测为正类的比例。它表示了模型对正类样本的识别能力:
Recall
=
T
P
T
P
+
F
N
\text{Recall} = \frac{TP}{TP + FN}
Recall=TP+FNTP
4. F1-Score
F1 分数是精确率和召回率的调和平均值,是综合考虑精确率和召回率的指标,适用于数据不均衡的情况:
F1-Score
=
2
×
Precision
×
Recall
Precision
+
Recall
\text{F1-Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}
F1-Score=2×Precision+RecallPrecision×Recall
5. 特异性(Specificity)
特异性是指在所有实际为负类的样本中,模型预测为负类的比例。它反映了模型对负类的识别能力:
Specificity
=
T
N
T
N
+
F
P
\text{Specificity} = \frac{TN}{TN + FP}
Specificity=TN+FPTN
6. 假阳性率(False Positive Rate, FPR)
假阳性率是指在所有实际为负类的样本中,模型错误地预测为正类的比例:
FPR
=
F
P
F
P
+
T
N
\text{FPR} = \frac{FP}{FP + TN}
FPR=FP+TNFP
7. 负样本预测准确率
负样本预测准确率是指在所有预测为负类的样本中,模型正确地预测为负类的比例:
N-Precision
=
T
N
T
N
+
F
N
\text{N-Precision} = \frac{TN}{TN + FN}
N-Precision=TN+FNTN
四、混淆矩阵的用途
- 模型性能诊断:混淆矩阵能清晰地展示模型在哪些类别上表现较好,在哪些类别上容易出现错误。
- 不平衡数据集:在类别不平衡的情况下,单纯的准确率可能并不能很好地反映模型的性能。混淆矩阵提供的其他指标(如精确率、召回率、F1 分数)可以更好地帮助判断模型的表现。
- 调优模型:混淆矩阵的分析有助于发现模型的缺陷,并为下一步优化方向提供依据。例如,如果假阳性较多,可能需要调整模型的决策阈值。
五、示例分析
假设一个二分类问题,混淆矩阵如下:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | 80 | 20 |
| 实际为负类 | 10 | 90 |
从这个矩阵可以得到:
- 准确率: 80 + 90 80 + 90 + 10 + 20 = 0.85 \frac{80 + 90}{80 + 90 + 10 + 20} = 0.85 80+90+10+2080+90=0.85
- 精确率: 80 80 + 10 = 0.888 \frac{80}{80 + 10} = 0.888 80+1080=0.888
- 召回率: 80 80 + 20 = 0.8 \frac{80}{80 + 20} = 0.8 80+2080=0.8
- F1-Score: 2 × 0.888 × 0.8 0.888 + 0.8 = 0.842 \frac{2 \times 0.888 \times 0.8}{0.888 + 0.8} = 0.842 0.888+0.82×0.888×0.8=0.842
从结果可以看出,虽然准确率为 85%,但是模型对负类的召回率较高,可能对正类的识别存在一定的欠缺(20 个正类被错误分类为负类)。这种情况可以通过调整模型的决策阈值或使用不同的分类方法来改进。
六、总结
混淆矩阵是评估分类模型性能的重要工具,尤其是在多分类问题和不平衡数据集上。通过分析混淆矩阵中的各个元素和相关指标,能够更全面地理解模型的优缺点,并为进一步的调优提供依据。


















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











