







一、 nvidia-docker安装
- 卸载nvidia-docker及其它GPU容器
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
- 添加仓库包
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
如果找不到nvidia.github.io,则去https://githubusercontent.com.ipaddress.com/ 查找相应的ip,然后修改/etc/hosts 进行修复,下文中raw.githubusercontent.com一样
3. 安装nvidia-docker2
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
- 测试安装nvidia-docker成功(注意选择自己的cuda版本)
docker run --runtime=nvidia --rm nvidia/cuda:10.1-base nvidia-smi
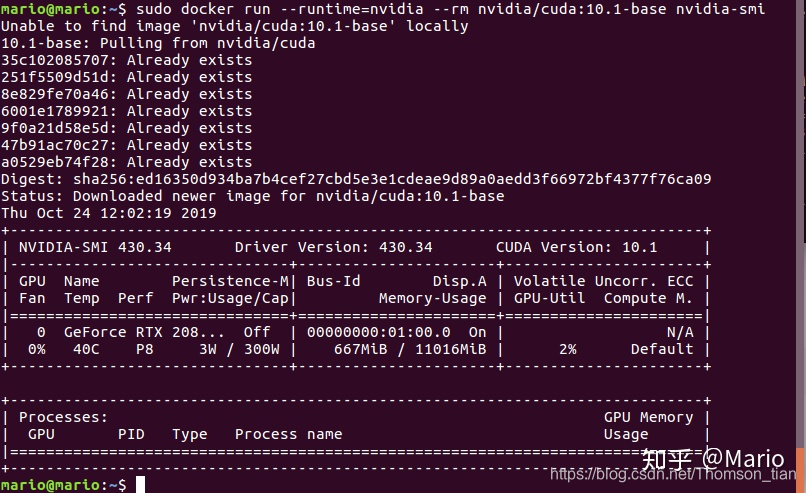
若出现如下图所示则表示安装成功啦。
二、k8s加载信息
修改Docker默认的runtime
编辑/etc/docker/daemon.json文件,增加"default-runtime": "nvidia"键值对,此时该文件的内容应该如下所示(registry-mirrors是之前添加的国内镜像下载地址):
{
"registry-mirrors": ["https://registry.docker-cn.com"],
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
systemctl daemon-reload
systemctl restart docker
安装
在Master节点上执行
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.10/nvidia-device-plugin.yml
稍等一会后,使用kubectl describe nodes查看节点信息,可以看到具有GPU的Node节点中可获取的资源已包括GPU
安装前
Capacity:
cpu: 8
ephemeral-storage: 51474024Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 41036940Ki
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 47438460440
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 40934540Ki
pods: 110
安装后
Capacity:
cpu: 8
ephemeral-storage: 51474024Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 41036940Ki
nvidia.com/gpu: 2
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 47438460440
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 40934540Ki
nvidia.com/gpu: 2
pods: 110
测试
在Master节点上创建~/tf-pod.yaml文件,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: tf-pod
spec:
containers:
- name: tf-container
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPUs
执行kubectl apply -f ~/tf-pod.yaml创建Pod。使用kubectl get pod可以看到该Pod已经启动成功

执行kubectl exec tf-pod -it – bash进入Pod内部。测试显卡信息以及TensorFlow的GPU调用,可以看到成功运行。这也说明k8s完成了对GPU资源的调用
参考链接:(1) https://blog.csdn.net/weixin_41383736/article/details/86252342?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-8.baidujs&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-8.baidujs
(2) https://zhuanlan.zhihu.com/p/88351963?from_voters_page=true
(3) https://www.dazhuanlan.com/2019/11/19/5dd2f6ddd6164/














 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









