






一、什么是深度学习框架
深度学习采用“端到端”的学习模式。随着神经网络的发展,模型的复杂度也不断提升。即使是在一个最简单的卷积网络神经中也会包含卷积层、池化层、激活层、Flatten层、全连接层等。
1、意义
屏蔽底层的细节,使研究者可以专注于模型结构。
2、功能
1、神经网络的定义和配置:框架提供了一组API,允许用户方便地定义神经网络的结构,如层数、激活函数类型、优化器选择等参数的配置。
2、训练和优化:内置的计算引擎支持前向传播和反向传播算法,自动进行梯度计算和参数更新,帮助用户完成模型的训练过程。
3、数据管理和预处理:提供数据加载、处理的工具,支持数据增强、批量处理等功能,以提高模型的鲁棒性和泛化能力。(深度学习的鲁棒性指的是模型在面对输入数据中的噪声、异常点或对抗攻击时,仍能保持正确和稳定输出的能力。)
4、硬件加速和分布式计算:支持多GPU或分布式系统上的并行计算,加快模型训练的速度,并提高计算效率。
5、模型的部署和推理:使训练好的模型能够在不同的硬件平台上运行,并进行实际的预测和推理任务。
二、Caffe
1、什么是Caffe
卷积神经网络框架是一种常用的深度学习框架,主要应用在视频、图像处理等方面。
Caffe是一个清晰、可读性高、快速的深度学习框架。
Caffe是一个主流的工业级深度学习工具,精于图像处理。(它不够灵活,且对递归网络和语言建模的支持很差。对于基于层的网络结构,Caffe扩展性不好;用户如果想增加层,则需要自己实现前向传播、反向传播以及参数更新。)
2、特点
1、Caffe的基本工作流程是设计建立在神经网络的一个简单假设,所有的计算都是以层的形式表示的。
如:
网络层所做的就是接收输入数据,然后输出计算结果。
卷积层就是输入一幅图像,然后和这一层的参数(filter)进行卷积,最终输出卷积结果。
2、每层需要两个函数计算,一个是forward,从输入计算到输出;另一个的backward,从上层给的gradient来计算相对于输入层gradient。
3、这两个函数实现之后,我们就可以把许多层连接成一个网络,这个网络输入数据(图像、语音或其他原始数据),然后计算需要的输出(比如识别的标签)。
4、训练的时候可以可以根据已有的标签计算loss和gradient,然后用gradient来更新网络中的参数。
5、Caffe是一个清晰而高效的深度学习框架。基于纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口,可以在CPU和GPU之间直接无缝切换。
6、模型与优化都通过配置文件来设置,无须代码。
7、允许对数据格式、网络层和损失函数进行扩展。
8、Caffe模型的定义是用Protocol Buffer(协议缓冲区)语言以任意有向无环图的形式写进配置文件的。
9、Caffe会根据网络需要正确占用内存,通过一个函数调用实现CPU和GPU之间的切换。
10、Caffe中的每一个单一的模块都对应一个测试,使得测试的覆盖非常方便,同时提供python和MATLAB接口,用这两种语言进行调节都是可行的。
3、Caffe概述
1、Caffe的相应优化都是以文本形式而非代码形式给出。Caffe中的网络都是有向无环图的集合,可以直接定义。 Caffe网络的定义如下:
name:"dummy-net"
layers{name:"data" ···}
layers{name:"conv" ···}
layers{name:"pool" ···}
layers{name:"loss" ···}
2、数据及其导数以blob的形式在层间流动,Caffe层的定义由两部分组成:层属性与层参数,
如下所示:
name:"conv1"
type:CONVOLUTION
bottom:"data"
top:"conv1"
convolution_param{
num_output:20
kernel_size:5
stride:1
weight_filler{
type:"xavier"
}
}
前4行是层属性,定义了层名称、层类型以及层连接结构;
后半部分是各种层参数。
blob是存储数据的4维数组,例如:
数据表示为Number*Channel*Height*Width;
卷积权重表示为Output*Input*Height*Width;
卷积偏置表示为Output*1*1*1。
三、TensorFlow
1、什么是TensorFlow、
TensorFlow是一个采用数据流图进行数值计算的开源软件库。节点(node)在数据流图中表示数学操作,线(edge)则表示在节点间相互联系的多维数据数组,即张量(tensor)。灵活的架构让你可以在多种平台上展开计算。
TensorFlow由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其可以广泛用于其他计算领域。
2、数据流图
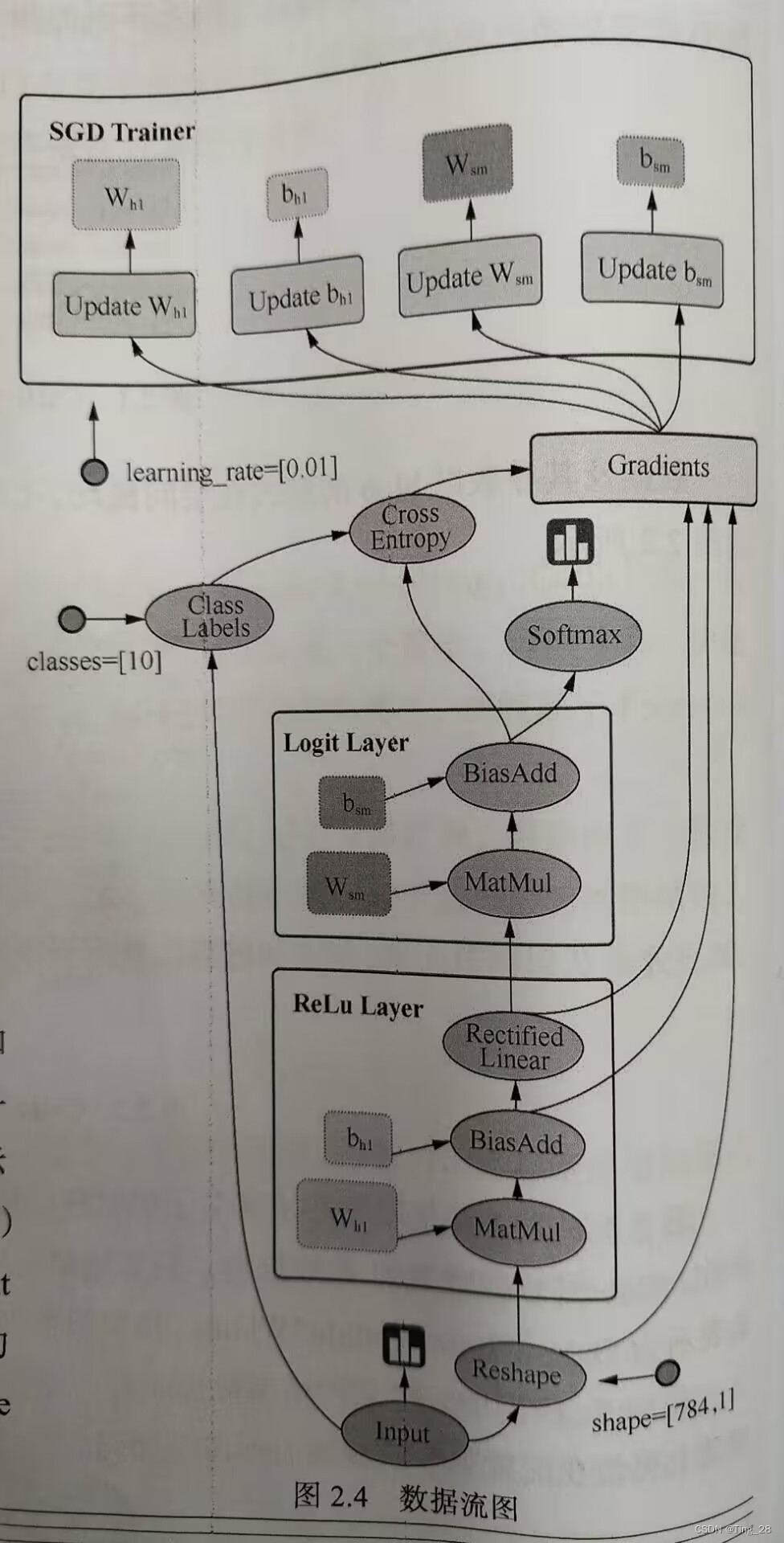
数据流图用“节点”和“线”的有向图来描述数学计算。
“节点”一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点。
“线”表示“节点”之间的输入/输出关系。
“线”可以运输“size可动态调整”的多维数据数组,即“张量”。
张量从图中“流过"的直观图像是这个工具取名为“TensorFlow”的原因。
一旦输入端的所有张量准备好,节点将被分配到各种计算设备,完成异步与并行的运算。
3、特点
1、只要用户将计算表示为一个数据流图就可以使用TensorFlow。
2、TensorFlow提供有用的工具来帮助用户组装“子图”,用户也可以自己在TensorFlow基础上写自己的“上层库”。
3、TensorFlow的可扩展性相当强,如果用户找不到想要的底层数据操作,也可以自己写一些C++代码来丰富底层的操作。
4、TensorFlow可在CPU和GPU上运行,如:可以运行在台式计算机、服务器、手机移动设备等。
5、TensorFlow支持自动在多个CPU上规模化运算训练模型,以及迁移到后台。
6、TensorFlow有一个合理的C++使用界面,也有一个易用的python使用界面来构建和执行你的图。
4、概述
TensorFlow中的Flow,也就是流,是其完成运算的基本方式。
流是指一个计算图或简单的一个图,图不能形成环路,图中的每个节点代表一个操作。如:加法、减法等。每个操作都会导致新的张量形成。
5、简单的计算图
表达式:e=(a+b)*(b+1)
计算图:

①:叶子顶点或起始顶点始终是张量,即操作永远不会发生在图的开头,由此可以推断,图中的每个操作都应该接收一个张量并产生一个新的张量。
②:张量不能作为非叶子节点出现,意味着它们应始终作为输入提供给操作/节点。
③:计算图总是以层次顺序表达复杂的操作,通过a+b表示为c,将b+1表示为d,可以分层次组织上述表达式。 因此,可以将e写为:e=(c)*(d)。
④:计算图的并行,即同级节点的操作彼此独立,这是计算图的重要属性之一。在同一级中的节点,例如c和d,彼此独立。意味着没有必要在计算d之前计算c,因此它们可以并行执行。
同级的节点是独立的。意味着在c被计算之前不需空闲,可以在计算c的同时并行计算d。
TensorFlow允许用户使用并行计算设备更快地执行操作。计算的节点或操作自动调度进行并行计算。这一切的发生在内部,如上图,可以在CPU上调度操作c,在GPU上调度操作d。
6、两种分布式执行过程
1、两种分布式
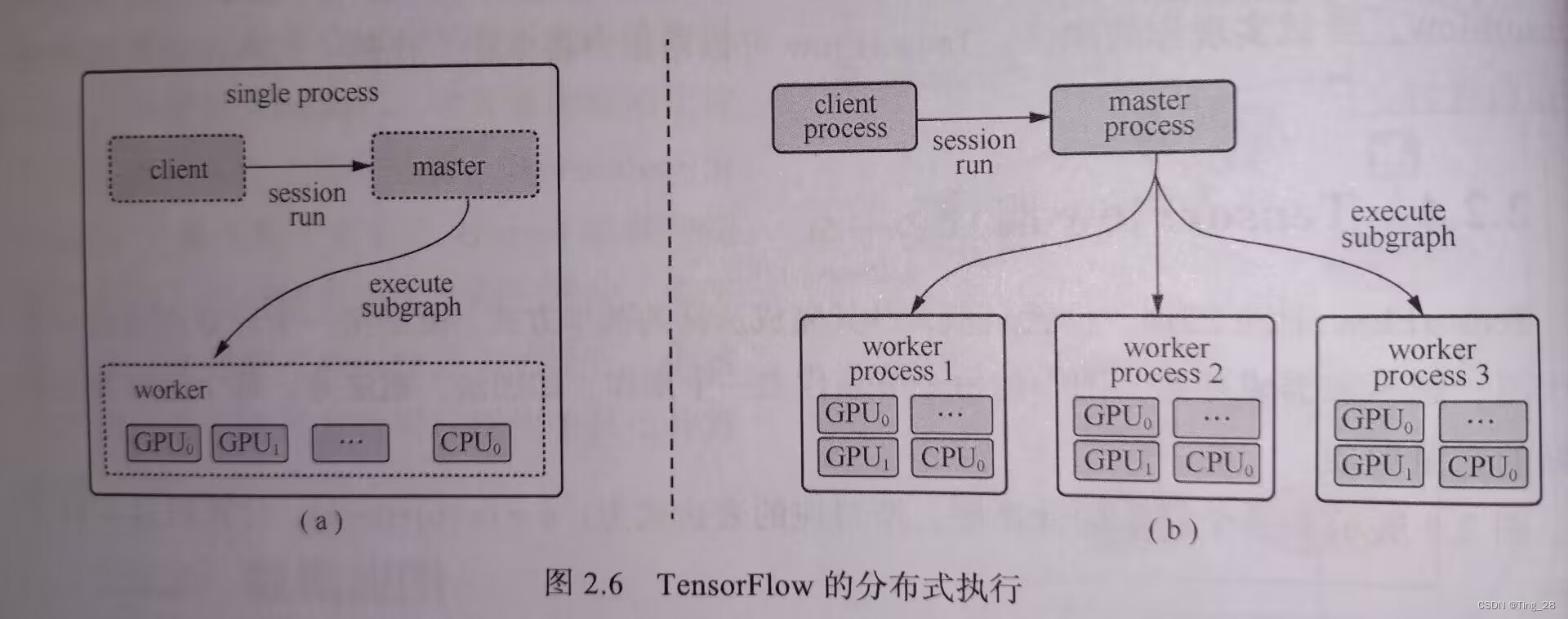
(a)是单个系统分布式执行,其中单个TensorFlow会话创建单个worker,并且该worker负责在各设备上调度任务。
(b)所示有多个worker,它们可以在同一台机器上或不同机器上,每个worker都在自己的上下文中运行。worker processl运行在独立的机器上,并调度所有可用设备进行计算。
2、计算子图
计算子图是主图的一部分,其本身就是计算图。
例:图2.5可以获得许多子图,其中之一如图2.7
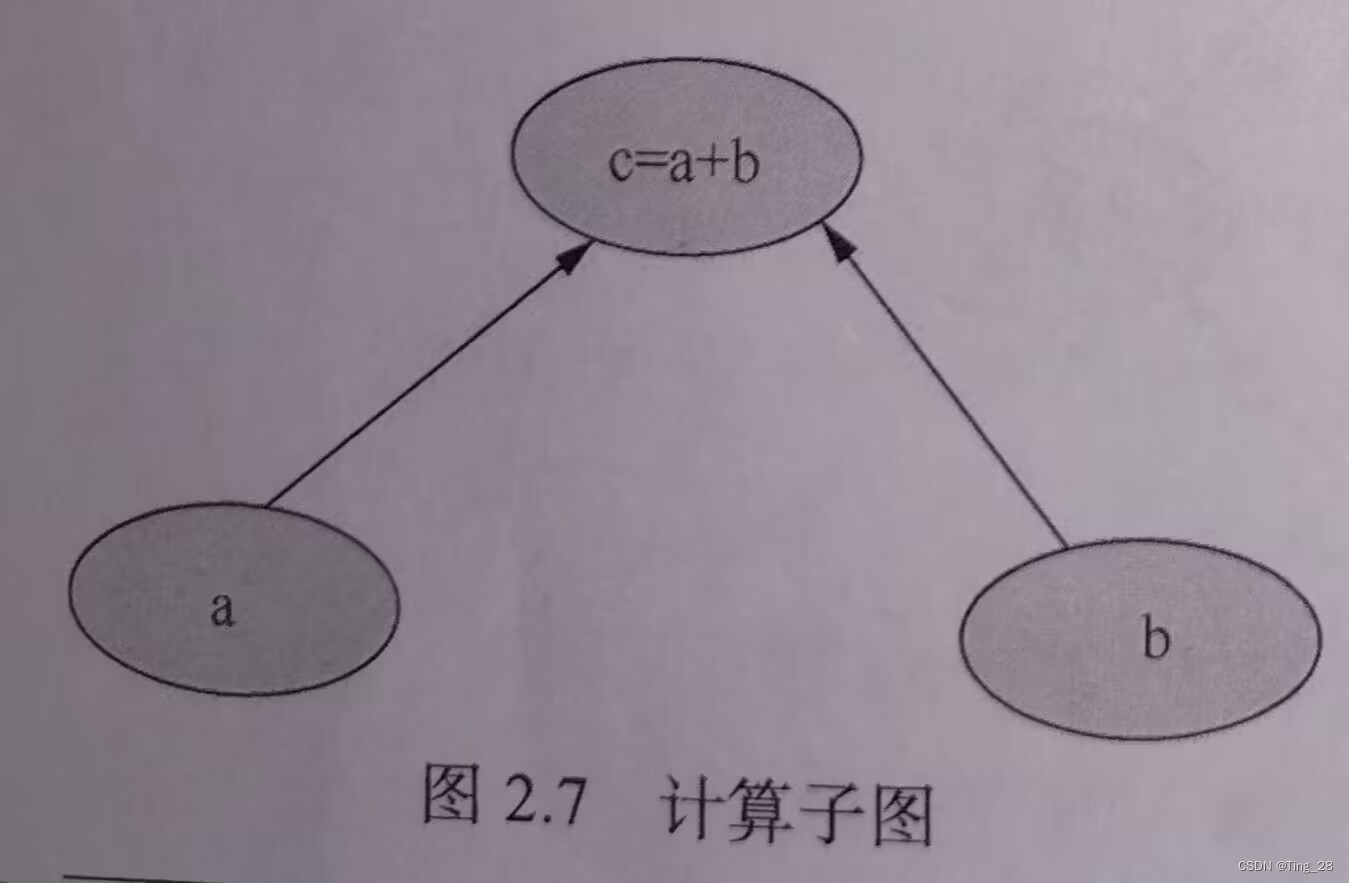
是主图的一部分,可以表示一个子表达式,因为c是e的子表达式。
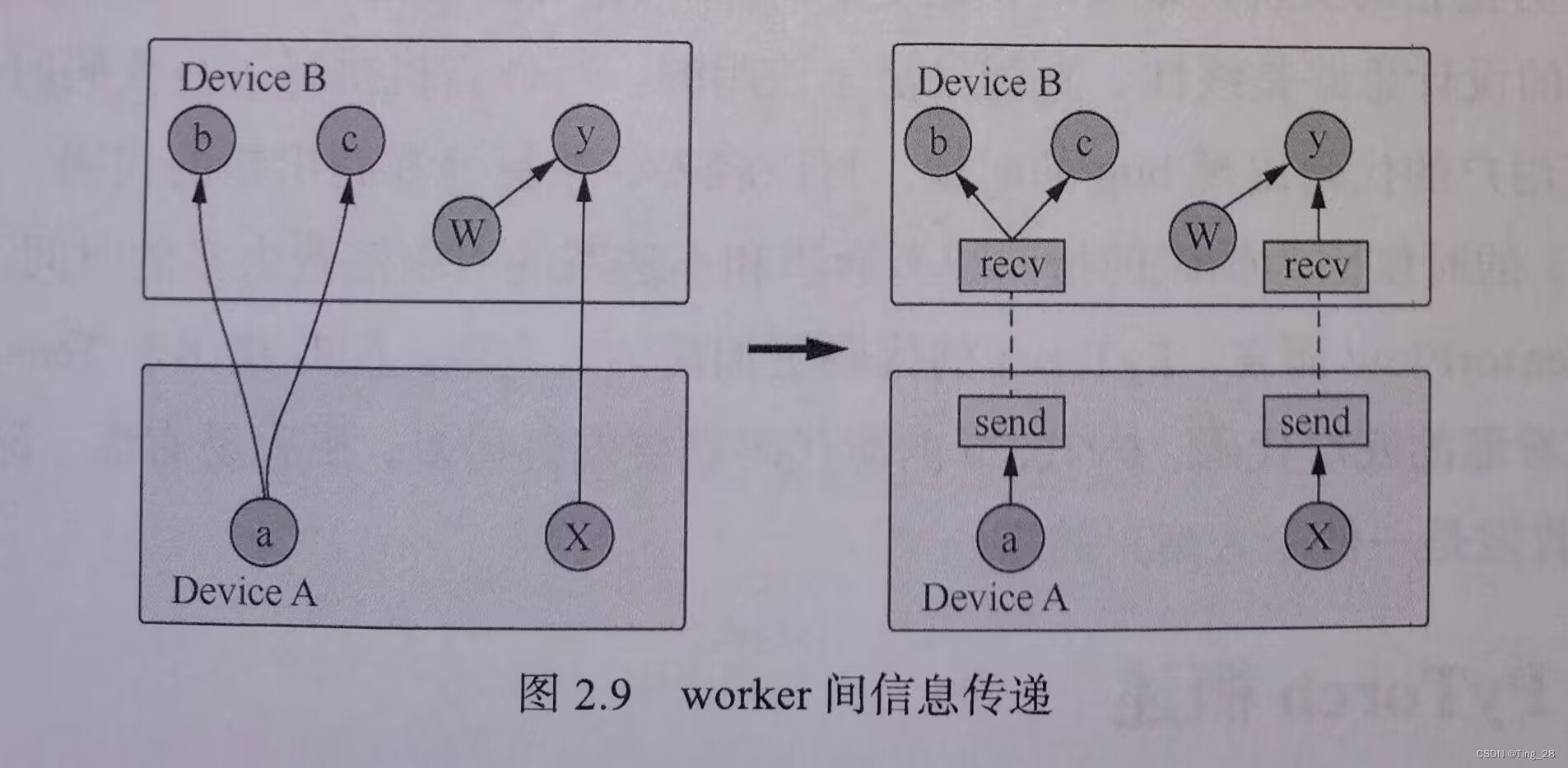
下图解释了子图的并行执行:

有两个矩阵(MatMul)乘法运算,它们都处于同一级别且彼此独立。
由于独立性,节点安排在不同的设备gpu_0和gpu_1上。
TensorFlow将其所有操作分配到由worker管理的不同设备上。更常见的是worker之间交换张量形式的数据,如:e=(c)*(d)的计算图中,一旦计算出c,就需要将其传递给e,因此张量在节点间前向流动。worker间信息传递如下图:















 2293
2293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









