






1、前文说明
使用jeecgboot框架时,demo服务居然也会触发Quartz任务,但是因为class类不存在,直接导致异常报错
2、配置描述(properties)
#============================================================================
# 1. 基本配置
#============================================================================
# 调度标识名,集群中每一个实例都必须使用相同的名称。
# 可以为任意字符串,对于scheduler来说此值没有任何意义,但是可以区分同一系统中多个不同的实例。
# 如果使用了集群的功能,就必须对每一个实例使用相同的名称,这样使这些实例“逻辑上”是同一个scheduler。
org.quartz.scheduler.instanceName = SERVICEX-SCHEDULER-INSTANCE
# ID设置为自动获取,每一个实例不能相同。
# 可以为任意字符串,如果使用了集群的功能,SCHEDULER实例的值必须唯一,可以使用AUTO自动生成。
org.quartz.scheduler.instanceId = AUTO
# 默认值为false
org.quartz.scheduler.rmi.export = false
# 默认值为false
org.quartz.scheduler.rmi.proxy = false
# 默认false,若是在执行Job之前Quartz开启UserTransaction,此属性应该为true。Job执行完毕,JobDataMap更新完(如果是StatefulJob)事务就会提交。
# 可以在JOB类上使用 @ExecuteInJTATransaction注解,以便在各自的JOB上决定是否开启JTA事务。
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
# 一个SCHEDULER节点允许接收的TRIGGER的最大数,默认是1。值越大定时任务执行的越多,代价是集群节点之间的不均衡。
org.quartz.scheduler.batchTriggerAcquisitionMaxCount=1
#============================================================================
# 2. 调度器线程池配置
#============================================================================
# 线程池的实现类,一般使用SimpleThreadPool即可满足需求
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
# 指定线程数无默认值,至少为1,指定该值后线程数量不会动态增加。
org.quartz.threadPool.threadCount = 20
# 线程的优先级(最大为java.lang.Thread.MAX_PRIORITY 10,最小为Thread.MIN_PRIORITY 1,默认为5)
org.quartz.threadPool.threadPriority = 5
# 加载任务代码的ClassLoader是否从外部继承
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
# 是否设置调度器线程为守护线程
org.quartz.scheduler.makeSchedulerThreadDaemon = true
#============================================================================
# 3. 作业存储配置
#============================================================================
# JDBC的存储方式
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
# 数据库驱动,类似于Hibernate的dialect,用于处理DB之间的差异,StdJDBCDelegate能满足大部分的DB的使用。
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
# 是否加入集群,当有多个Quartz实例在用同一套数据库时,必须设置为true。
org.quartz.jobStore.isClustered = true
# 检查集群节点状态的频率, 默认值是 15000(即15秒)
# 只用于设置了isClustered为true的时,才需要设置该项,用于实例上报信息给集群中的其他实例,这个值的大小会影响到侦测失败实例的敏捷度。
org.quartz.jobStore.clusterCheckinInterval = 15000
# 这是JobStore能处理的错过触发的TRIGGER的最大数量。处理太多则很快就会导致数据库中的表被锁定够长的时间,这样则会妨碍别的(还未错过触发)TRIGGER执行的性能。
org.quartz.jobStore.maxMisfiresToHandleAtATime = 1
org.quartz.jobStore.txIsolationLevelSerializable = true
# 设置这个参数为true会告诉Quartz从数据源获取连接后不要调用它的setAutoCommit(false)方法,大部分情况下驱动都要求调用setAutoCommit(false)。
org.quartz.jobStore.dontSetAutoCommitFalse = false
# 这必须是一个从LOCKS表查询一行并对这行记录加锁的SQL。假设没有设置,默认值如下。{0}会在运行期间被配置的TABLE_PREFIX所代替。
org.quartz.jobStore.selectWithLockSQL=SELECT * FROM {0}LOCKS WHERE LOCK_NAME = ? FOR UPDATE
# 设置调度引擎对触发器超时的忍耐时间 (单位毫秒)
org.quartz.jobStore.misfireThreshold = 12000
# 表的前缀,默认QRTZ_
org.quartz.jobStore.tablePrefix = QRTZ_
3、配置描述(yml)
string:
quartz:
job-store-type: jdbc
initialize-schema: embedded
#定时任务启动开关,true-开 false-关
auto-startup: true
#延迟1秒启动定时任务
startup-delay: 1s
#启动时更新己存在的Job
overwrite-existing-jobs: true
properties:
org:
quartz:
scheduler:
# 集群名,区分同一系统的不同实例,若使用集群功能,则每一个实例都要使用相同的名字
instanceName: MyScheduler2
# 若是集群下,每个instanceId必须唯一
instanceId: AUTO
# 存储方式
jobStore:
# 选择JDBC的存储方式
class: org.springframework.scheduling.quartz.LocalDataSourceJobStore
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_
isClustered: true
misfireThreshold: 12000
clusterCheckinInterval: 15000
# 线程配置
threadPool:
# 线程池
class: org.quartz.simpl.SimpleThreadPool
# 线程数量
threadCount: 10
threadPriority: 5
threadsInheritContextClassLoaderOfInitializingThread: true
4、修改点
# 不用应用服务,修改此处的名称即可
org.quartz.scheduler.instanceName = MyScheduler2
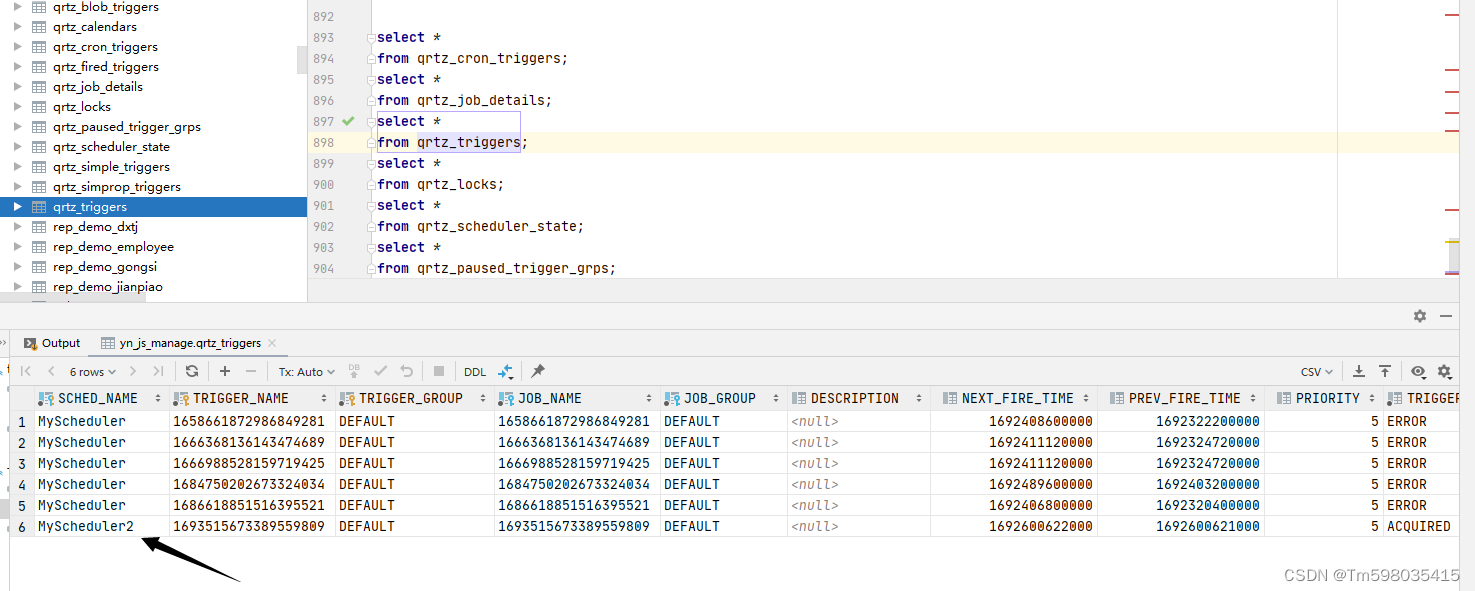
当修改instanceName名称的时候,Quartz也会随着创建新的空间


















 3234
3234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









