







先看效果:
 Oxford-IIIT Pet Dataset是一个不错的数据集,牛津官方整理出来的一个关于各种猫和狗的数据集,可以很方便被我们用来做图像识别或者是图像分割类型的任务,这里我们主要是做图像识别的应用。
Oxford-IIIT Pet Dataset是一个不错的数据集,牛津官方整理出来的一个关于各种猫和狗的数据集,可以很方便被我们用来做图像识别或者是图像分割类型的任务,这里我们主要是做图像识别的应用。
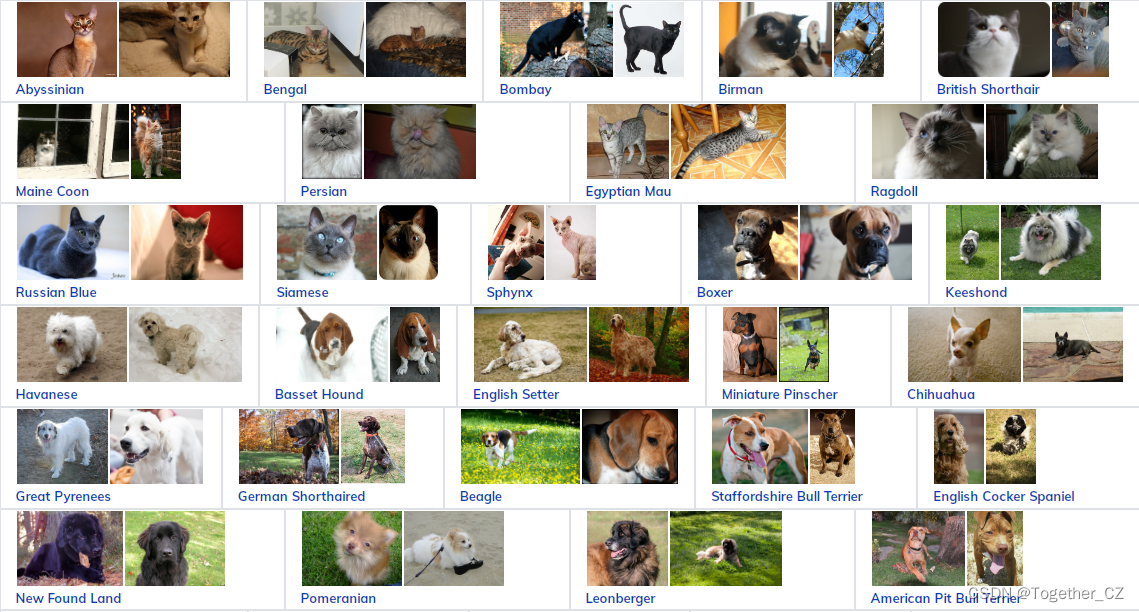
官方介绍如下所示:

除了这些以外,官方还对数据集下各个类别中的数据量进行了统计,如下所示:
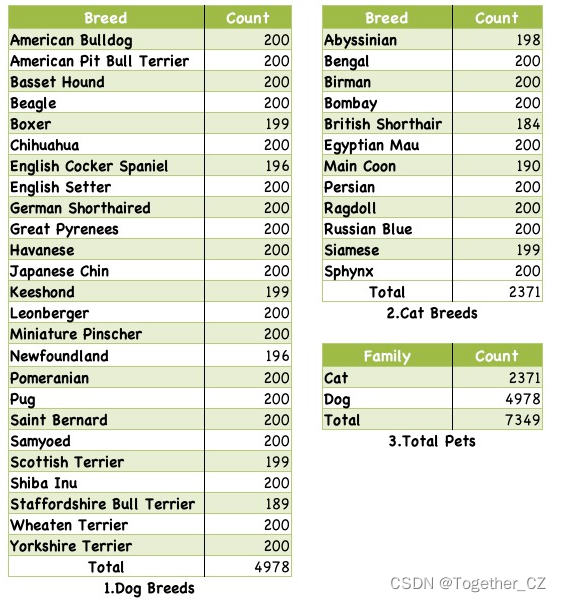
从数据统计结果上来看,狗的图像数据量是猫的两倍以上。
这里我们要做的是图像识别的任务,由于原始数据集是混在一起的,这里我首先将其拆分开来,归类到不同的目录中,核心代码实现如下所示:
#!usr/bin/env python
# encoding:utf-8
from __future__ import division
"""
功能: 数据处理模块
"""
import os
import shutil
def splitImg2Category(dataDir="images/",resDir="dataset/"):
'''
归类图像到不同目录中
'''
for one_pic in os.listdir(dataDir):
one_path=dataDir+one_pic
oneDir=resDir+one_pic.split('_')[0].strip()+"/"
if not os.path.exists(oneDir):
os.makedirs(oneDir)
shutil.copy(one_path,oneDir+one_pic)
归类处理之后得到如下目录:
随机看几个目录:
【Abyssinian】
【Egyptian】
【miniature】
【shiba】
接下来对总的数据集进行随机划分,得到训练集-测试集,核心代码实现如下:
def random2Dataset(dataDir='data/original/',ratio=0.3):
'''
对原始数据集进行划分,得到:训练集和测试集
'''
label_list=os.listdir(dataDir)
for one_label in label_list:
oneDir=dataDir+one_label+'/'
pic_list=os.listdir(oneDir)
testNum=int(len(pic_list)*ratio)
oneTrainDir='data/train/'+one_label+'/'
oneTestDir='data/test/'+one_label+'/'
if not os.path.exists(oneTrainDir):
os.makedirs(oneTrainDir)
if not os.path.exists(oneTestDir):
os.makedirs(oneTestDir)
#创建测试集
for i in range(testNum):
one_path=oneDir+random.choice(os.listdir(oneDir))
name=str(len(os.listdir(oneTestDir))+1)
new_path=oneTestDir+one_label+'_'+name+'.jpg'
shutil.move(one_path,new_path)
#创建训练集
for one_pic in os.listdir(oneDir):
one_path=oneDir+one_pic
name=str(len(os.listdir(oneTrainDir))+1)
new_path=oneTrainDir+one_label+'_'+name+'.jpg'
shutil.move(one_path,new_path)
接下来搭建CNN模型:
def buildModel(h=16, w=10, way=1):
"""
构建模型
"""
model = Sequential()
input_shape = (h, w, way)
model.add(Conv2D(64, (3, 3), input_shape=input_shape))
model.add(Activation("relu"))
model.add(Dropout(0.3))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.3))
model.add(Dense(35))
model.add(Activation("sigmoid"))
lrate = 0.01
decay = lrate / 100
sgd = SGD(lr=lrate, momentum=0.9, decay=decay, nesterov=False)
model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=["accuracy"])
print(model.summary())
return model之后就可以训练模型了,核心代码实现如下:
#数据加载
X_train, X_test, y_train, y_test = load()
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
#数据归一化
X_train /= 255
X_test /= 255
# 模型
model = buildModel(h=h, w=w, way=way)
# 拟合训练
checkpoint = ModelCheckpoint(
filepath=saveDir + "best.h5",
monitor="val_loss",
verbose=1,
mode="auto",
save_best_only="True",
period=1,
)
history = model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
callbacks=[checkpoint],
epochs=nepochs,
batch_size=32,
)
print(history.history.keys())
#可视化
plt.clf()
plt.plot(history.history["acc"])
plt.plot(history.history["val_acc"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epochs")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(saveDir + "train_validation_acc.png")
plt.clf()
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epochs")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(saveDir + "train_validation_loss.png")
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1] * 100))
model_json = model.to_json()
with open(saveDir + "structure.json", "w") as f:
f.write(model_json)
model.save_weights(saveDir + "weights.h5")
model.save(saveDir + "model.h5")
print("=====================Finish=========================")
# 持久化
lossdata, vallossdata = history.history["loss"], history.history["val_loss"]
accdata, valaccdata = history.history["acc"], history.history["val_acc"]
history = {}
history["loss"], history["val_loss"] = lossdata, vallossdata
history["acc"], history["val_acc"] = accdata, valaccdata
with open(saveDir + "history.json", "w") as f:
f.write(json.dumps(history))训练完成结果如下所示:
准确率曲线如下:
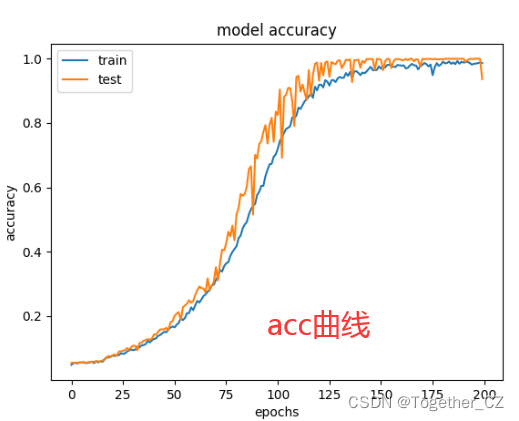
损失值曲线如下所示:
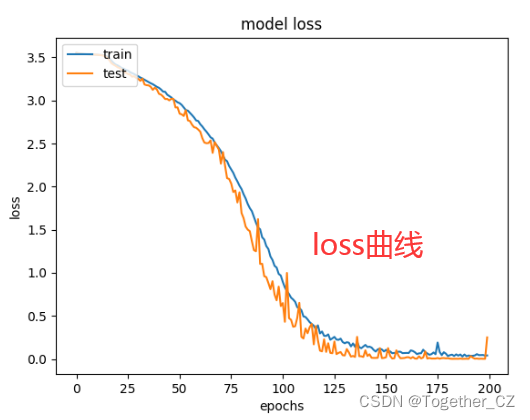
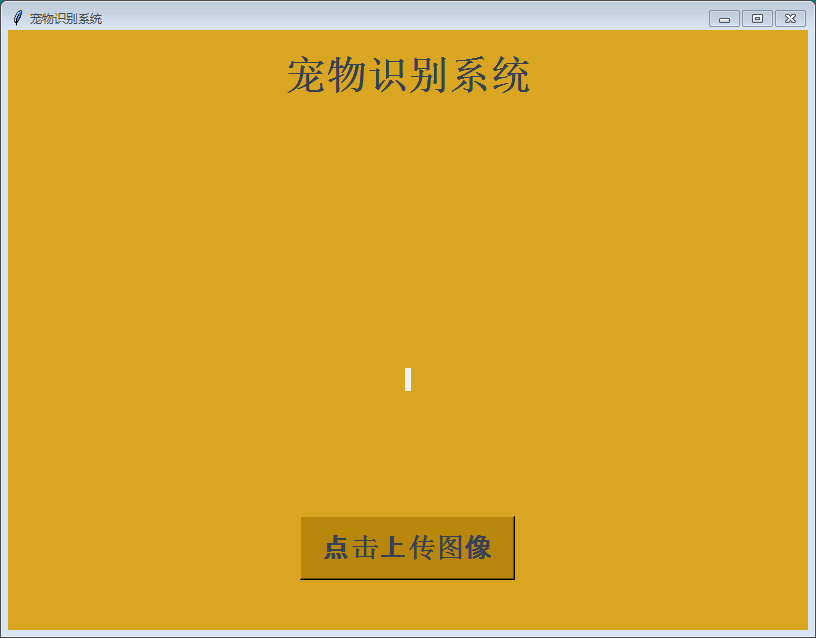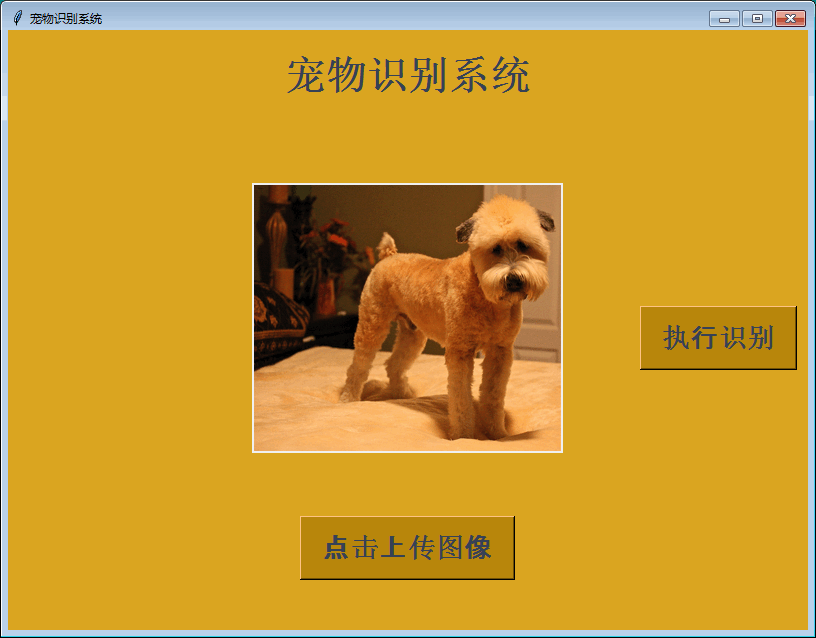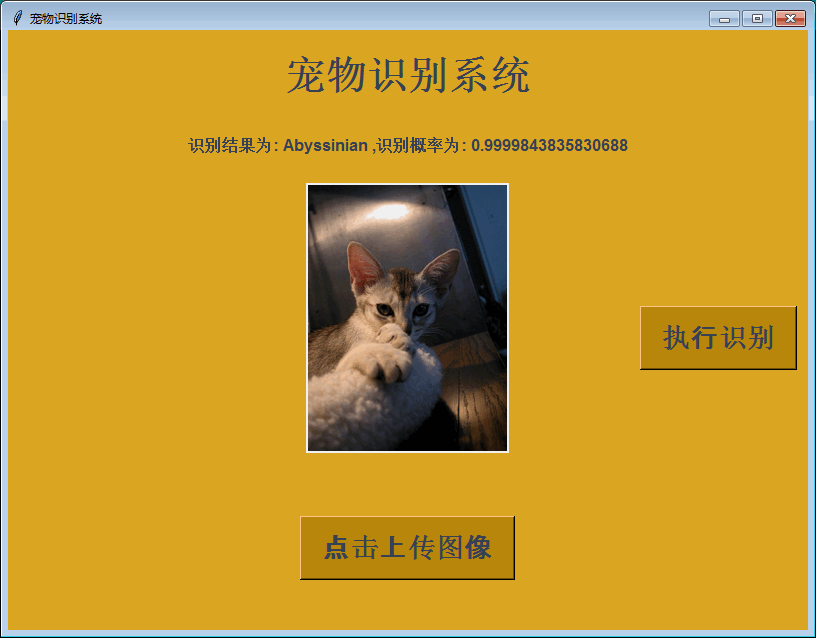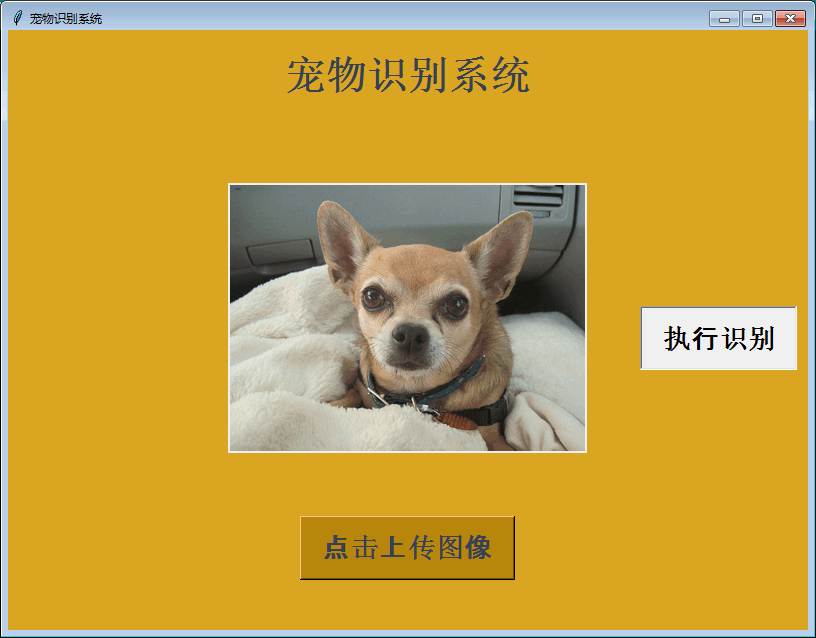
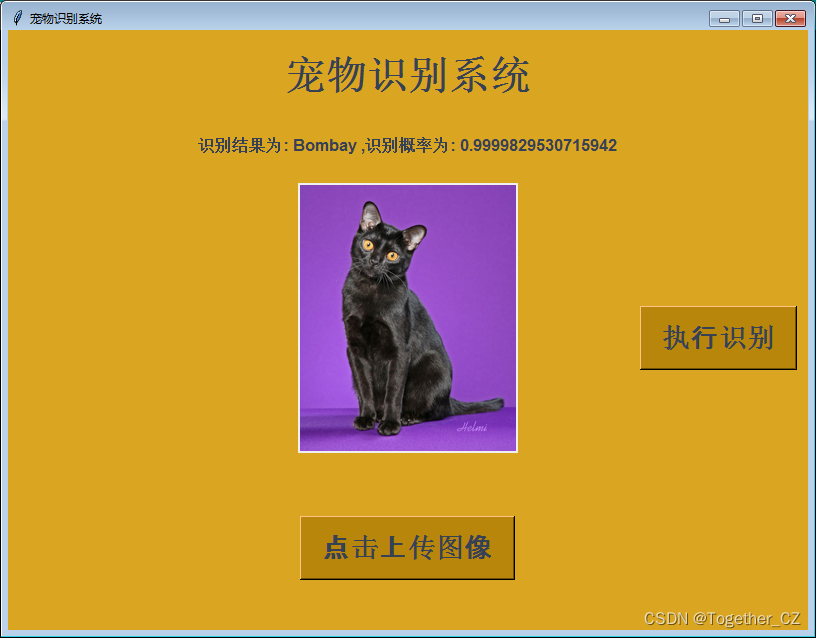
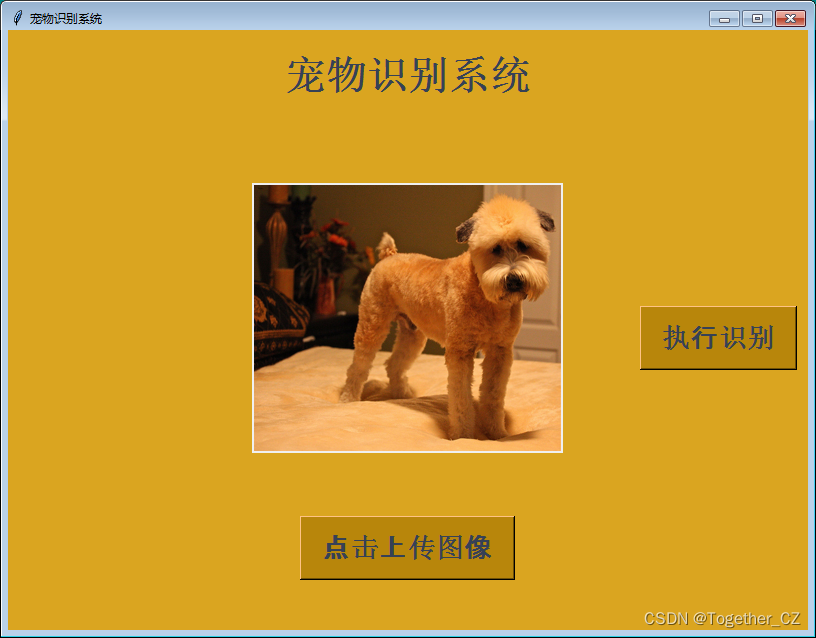
同样,这里开发对应的界面,方便使用,效果图如下:
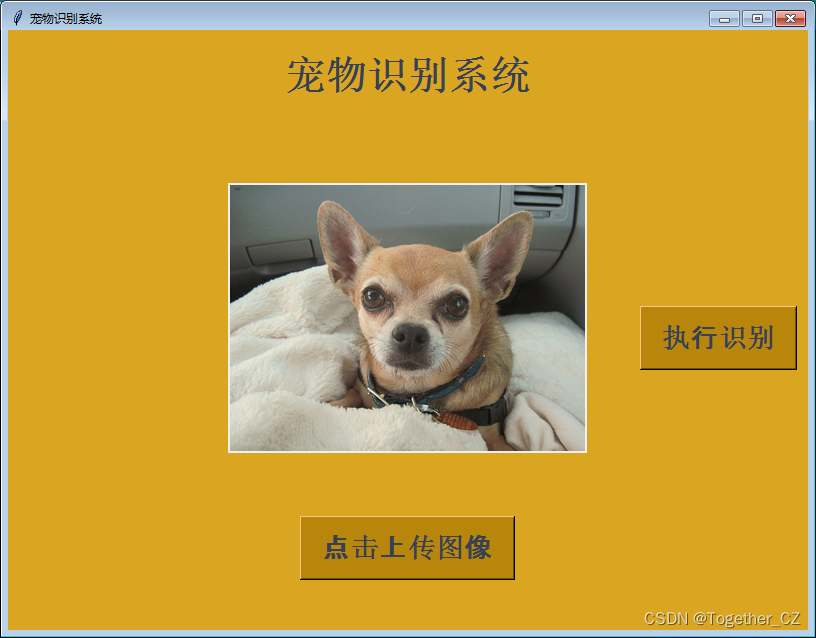
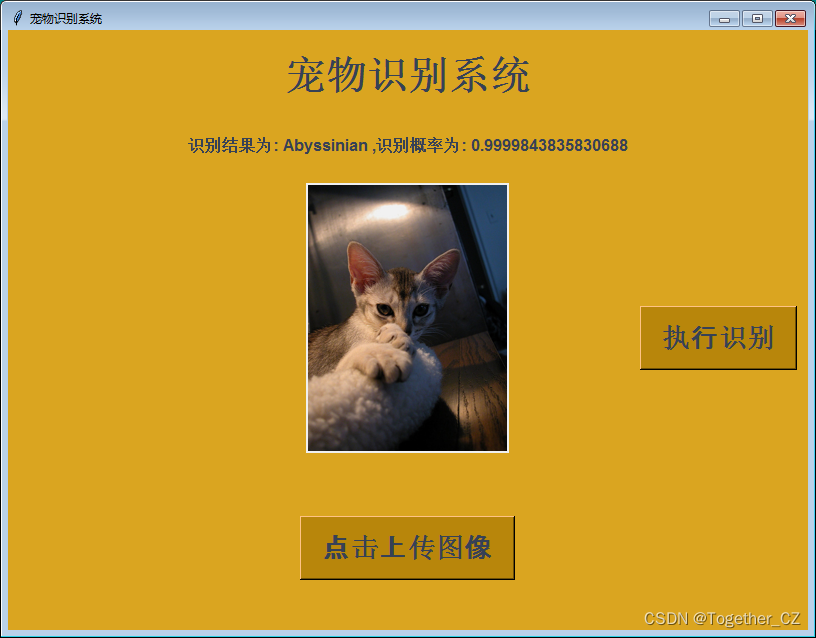



















 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











