









在以往的项目中,我们想要计算时间序列的相关性的话,大都是把整体的数据中不同维度的数据当做是一个整体序列来进行两两序列之间的相关性分析计算,也比较简洁实用一些,这里今天遇上一个新的需求就是,我们需要把滑窗这一工具加入进来,原本滑窗是为了创建监督数据集为时间序列预测模型服务的,但是这里可以将其用作于相关性计算,通过切分出来不同的片段数据,可以计算出来多组相关性数据,也就是说在以往的实践中,序列A和序列B的相关性结果是一个数值,这里序列A和序列B的相关性结果也是一个序列,这个序列的长度取决于切分得到的窗口的数量。
首先看下自己创建的数据集,样例如下:

接下来需要对原始数据集进行解析转化处理,核心实现如下所示:
def parseData(data="data1.xlsx", save_path="data.json"):
"""
解析数据集
"""
data = pd.read_excel(data)
data_list = data.values.tolist()
print("data_list_length: ", len(data_list))
title_list = data_list[0]
for one_list in data_list[:5]:
print(one_list)
res_list=[]
for one_list in data_list:
one_vec=[float(one) for one in one_list[1:]]
res_list.append(one_vec)
with open(save_path,"w") as f:
f.write(json.dumps(res_list))结果数据如下所示:

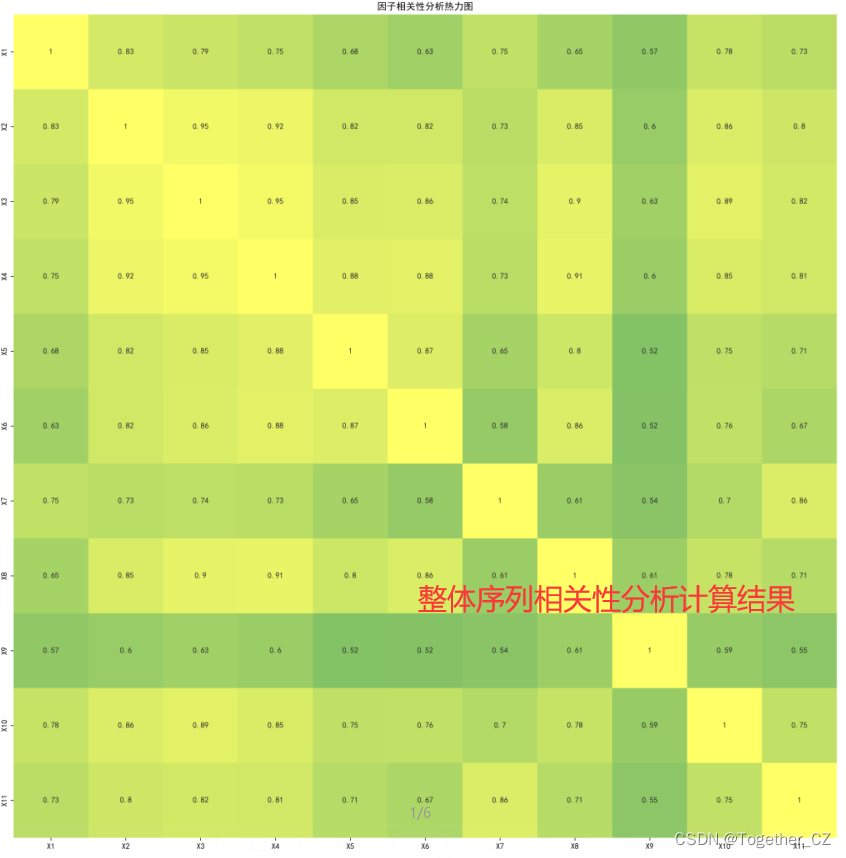
这里我们首先对整体序列数据进行相关性分析计算,核心实现如下所示:
def main(data="data.json"):
"""
主入口
"""
with open(data) as f:
data_list=json.load(f)
print("data_list_length: ", len(data_list))
matrix = dataTransform(data_list)
title = "因子相关性分析热力图"
label = ["X"+str(i) for i in range(1,12)]
print("label: ", label)
relationAnalysis(matrix, label, title, savepath="heatmap.png")很多组件函数在我以往的文章中都有,这里就不再赘述了,可视化得到的热力图如下所示:
之后,我们开始基于滑窗来对其进行数据的片段切分处理,核心实现如下所示:
def windowsRelation(data="data.json",step=200):
"""
计算滑窗相似度
"""
with open(data) as f:
data_list=json.load(f)
print("data_list_length: ", len(data_list))
windows=sliceWindow(data_list,step)
for i in range(len(windows)):
one_window=windows[i]
one_matrix = dataTransform(one_window)
title = "因子相关性分析热力图"
label = ["X"+str(i) for i in range(1,12)]
print("label: ", label)
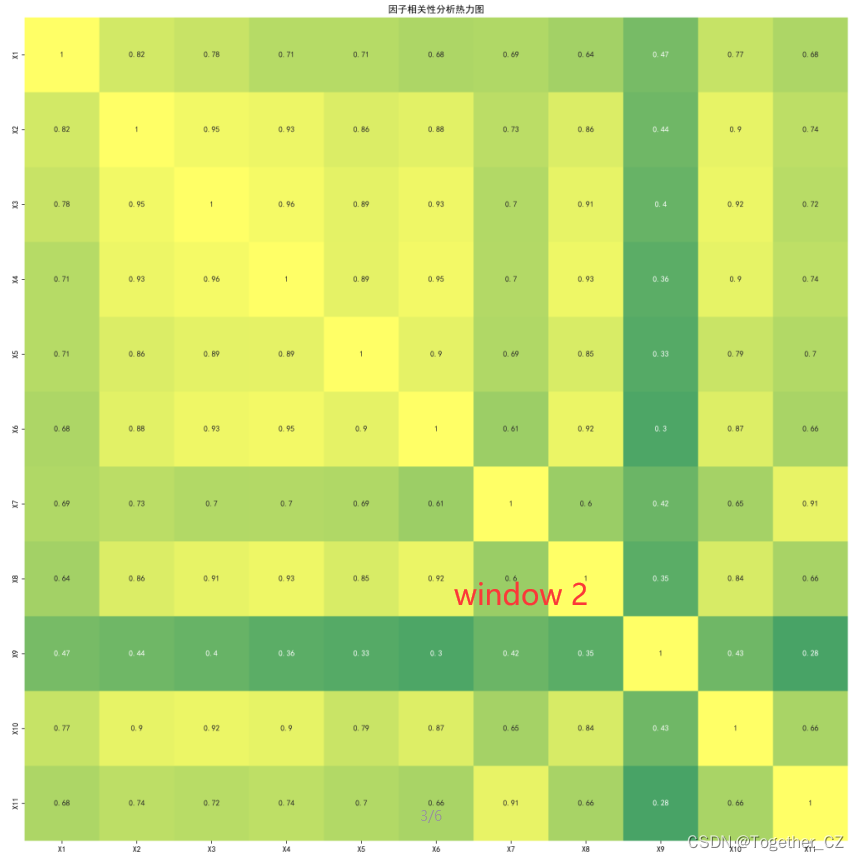
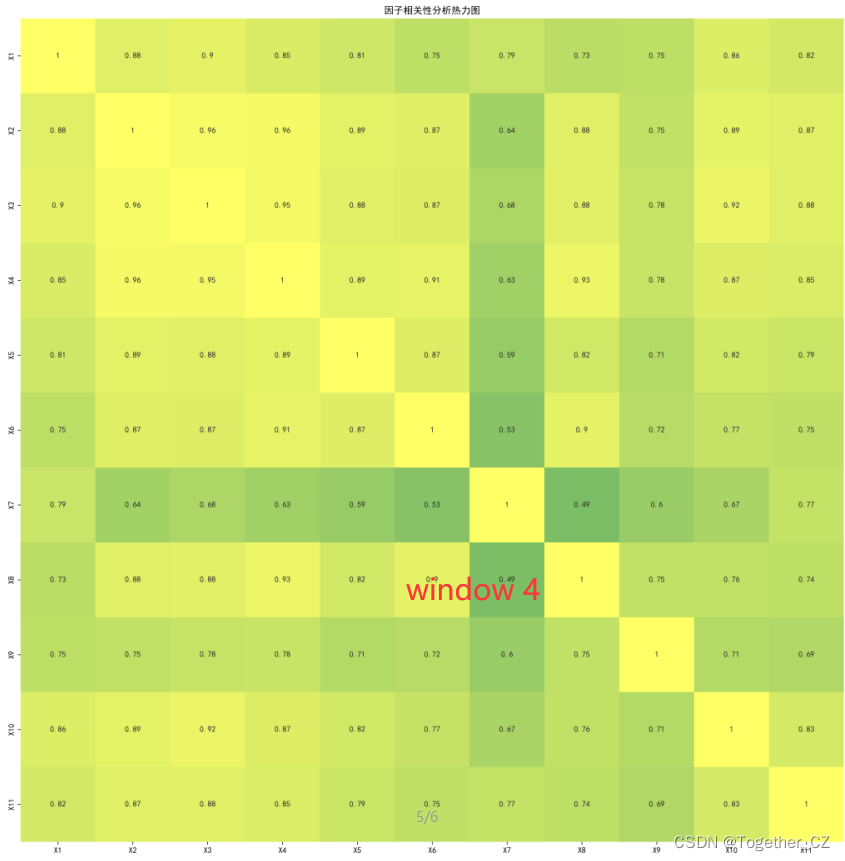
relationAnalysis(one_matrix, label, title, savepath="window_heatmap_"+str(i)+".png")在我的数据集种,总样本数据集1000+左右,所以能够切分得到5个时间片段的窗口数据,这里为了能够直观地呈现结果数据,对其进行了热力图的可视化展示,如下所示:
窗口1:

窗口2:
窗口3:

窗口4:
窗口5:

还是能够看到跟整体序列计算结果上面的差异的。

















 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











