






这篇文章介绍了一种名为**流匹配(Flow Matching, FM)的新方法,用于训练连续归一化流(Continuous Normalizing Flows, CNF)**模型。流匹配是一种无模拟的训练框架,旨在通过回归固定条件概率路径的向量场来实现高效的生成建模。其主要贡献和内容可以总结如下:
1. 背景与动机
-
生成模型的挑战:深度生成模型(如GAN、VAE)在估计和采样未知数据分布方面取得了显著进展,但现有的扩散模型依赖于简单的扩散过程,导致训练时间长且采样效率低。
-
连续归一化流(CNF):CNF是一种能够建模任意概率路径的强大工具,但传统的CNF训练方法(如最大似然训练)需要昂贵的数值ODE模拟,限制了其扩展性。
2. 流匹配(Flow Matching)
-
核心思想:流匹配通过回归目标向量场来训练CNF,避免了昂贵的数值ODE模拟。目标向量场定义了从噪声分布到数据分布的概率路径。
-
条件流匹配(Conditional Flow Matching, CFM):通过条件概率路径和向量场的构造,CFM提供了一个更易处理的目标函数,且与原始流匹配目标具有相同的梯度。
-
理论保证:文章通过定理1和定理2证明了CFM与FM在梯度上的等价性,确保了CFM可以有效替代FM进行训练。
3. 条件概率路径与向量场
-
高斯路径:文章提出了一类通用的高斯条件概率路径,并通过最优传输(OT)位移插值定义了更高效的路径。
-
扩散路径与OT路径:与传统的扩散路径相比,OT路径更简单,采样路径更直观,且在训练和采样效率上表现更好。
4. 实验验证
-
数据集:在CIFAR-10和ImageNet(分辨率32、64、128)上进行了实验,验证了流匹配的有效性。
-
性能提升:流匹配在似然性(NLL)和样本质量(FID)上均优于现有的扩散模型,尤其是在使用OT路径时,训练和采样效率显著提高。
-
采样效率:流匹配模型在低NFE(函数评估次数)下仍能保持较高的样本质量,展示了其在计算成本和生成质量之间的良好权衡。
5. 条件生成
-
图像上采样:流匹配还被应用于条件生成任务,例如将64×64的图像上采样到256×256,展示了其在条件生成中的潜力。
6. 结论与未来工作
-
总结:流匹配为CNF训练提供了一种高效、无模拟的框架,能够直接指定概率路径,避免了扩散过程的复杂性。
-
未来方向:流匹配有望应用于更多类型的概率路径(如非各向同性高斯或更一般的核),进一步扩展其应用范围。
7. 社会责任
-
潜在风险:图像生成技术可能被滥用于有害目的,因此需要通过内容控制和图像验证来减少这些风险。
-
能源效率:训练大型深度学习模型的能源需求不断增加,流匹配等方法通过减少梯度更新次数,有助于节省时间和能源。
这篇文章提出了一种名为流匹配的新方法,通过回归目标向量场来训练连续归一化流模型,避免了昂贵的数值ODE模拟。流匹配不仅在似然性和样本质量上优于现有的扩散模型,还显著提高了训练和采样效率。通过引入最优传输路径,流匹配进一步提升了模型的性能,展示了其在生成建模中的广泛应用潜力。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
我们引入了一种基于连续归一化流(CNF)的新生成建模范式,使我们能够在前所未有的规模上训练CNF。具体来说,我们提出了流匹配(Flow Matching, FM)的概念,这是一种基于回归固定条件概率路径的向量场的无模拟方法。流匹配与一系列高斯概率路径兼容,用于在噪声和数据样本之间进行转换——这涵盖了现有的扩散路径作为特定实例。有趣的是,我们发现使用扩散路径的流匹配为训练扩散模型提供了一种更稳健和稳定的替代方案。此外,流匹配为使用其他非扩散概率路径训练CNF打开了大门。特别感兴趣的一个实例是使用最优传输(OT)位移插值来定义条件概率路径。这些路径比扩散路径更高效,提供更快的训练和采样,并导致更好的泛化。在ImageNet上使用流匹配训练CNF,在似然性和样本质量方面,其性能始终优于基于扩散的替代方法,并且允许使用现成的数值ODE求解器进行快速可靠的样本生成。
1 引言
深度生成模型是一类旨在估计和从未知数据分布中采样的深度学习算法。近年来,生成建模的惊人进展(例如,用于图像生成的Ramesh等人(2022);Rombach等人(2022))主要得益于基于扩散模型的可扩展且相对稳定的训练(Ho等人(2020);Song等人())。然而,对简单扩散过程的限制导致采样概率路径的空间相当有限,导致训练时间非常长,并需要采用专门的方法(例如,Song等人();Zhang & Chen(2022))以实现高效采样。

图1:使用最优传输概率路径训练的CNF生成的无条件ImageNet-128样本
在这项工作中,我们考虑了连续归一化流(CNF;Chen等人(2018))的通用确定性框架。CNF能够建模任意概率路径,并且特别已知其涵盖了扩散过程建模的概率路径(Song等人,2021)。然而,除了可以通过去噪分数匹配(Vincent,2011)等方法高效训练的扩散外,尚无已知的可扩展CNF训练算法。事实上,最大似然训练(例如,Grathwohl等人(2018))需要昂贵的数值ODE模拟,而现有的无模拟方法要么涉及难以处理的积分(Rozen等人,2021),要么涉及有偏梯度(Ben-Hamu等人,2022)。
这项工作的目标是提出流匹配(FM),一种高效的无模拟方法,用于训练CNF模型,允许采用通用概率路径来监督CNF训练。重要的是,FM打破了扩散之外的可扩展CNF训练的障碍,并避免了推理扩散过程的需要,直接使用概率路径。
2 预备知识:连续归一化流


3 流匹配

从条件概率路径和向量场构建pt,ut

我们的第一个关键观察是:
边缘向量场(方程8)生成边缘概率路径(方程6)。
这提供了条件向量场(生成条件概率路径)与边缘向量场(生成边缘概率路径)之间的惊人联系。这一联系允许我们将未知的、难以处理的边缘向量场分解为更简单的条件向量场,这些条件向量场仅依赖于单个数据样本,因此更容易定义。我们在以下定理中形式化了这一性质。
定理1:给定向量场ut(x∣x1)生成条件概率路径pt(x∣x1),对于任何分布q(x1),方程8中的边缘向量场ut生成方程6中的边缘概率路径pt,即ut和pt满足连续性方程(方程26)。
条件流匹配
不幸的是,由于边缘概率路径和向量场的定义中存在难以处理的积分(方程6和8),计算ut仍然是不可行的,因此,直接计算原始流匹配目标的无偏估计量也是不可行的。相反,我们提出了一个更简单的目标,令人惊讶的是,这将导致与原始目标相同的优化结果。具体来说,我们考虑_条件流匹配_(CFM)目标:
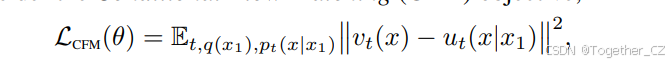

4 条件概率路径和向量场
条件流匹配目标适用于任何条件概率路径和条件向量场的选择。在本节中,我们讨论了高斯条件概率路径的构建,即:

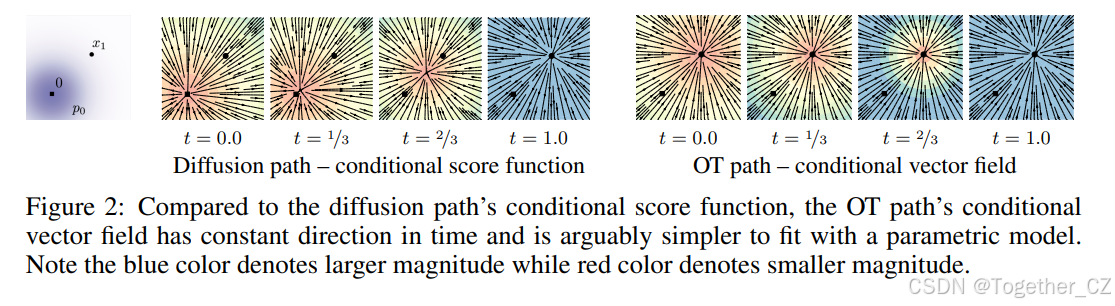
图2:与扩散路径的条件分数函数相比,OT路径的条件向量场在时间上具有恒定方向,可以说更易于用参数化模型拟合。请注意,蓝色表示较大的幅度,而红色表示较小的幅度
通过重新参数化pt(x∣x1)并代入CFM损失,我们得到:
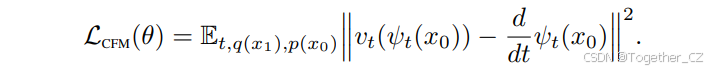

特殊的高斯条件概率路径实例
我们的公式对任意函数μt(x1)和σt(x1)完全通用,我们可以将它们设置为满足所需边界条件的任何可微函数。我们首先讨论恢复先前使用的扩散过程对应概率路径的特殊情况。由于我们直接处理概率路径,我们可以完全摆脱对扩散过程的推理。因此,在下面的第二个例子中,我们直接基于Wasserstein-2最优传输解决方案制定了一个有趣的实例。
示例I:扩散条件向量场
扩散模型从数据点开始,逐渐添加噪声,直到接近纯噪声。这些可以被表述为随机过程,在任意时间tt获得封闭形式表示有严格要求,导致高斯条件概率路径pt(x∣x1)具有特定的均值μt(x1)和标准差σt(x1)(Sohl-Dickstein等人,2015;Ho等人,2020;Song等人,)。例如,反向(噪声→→数据)方差爆炸(VE)路径具有以下形式:


示例II:最优传输条件向量场
定义条件概率路径的一个更自然的选择是简单地定义均值和标准差随时间线性变化,即:

在这种情况下,CFM损失(见方程9和14)的形式为:
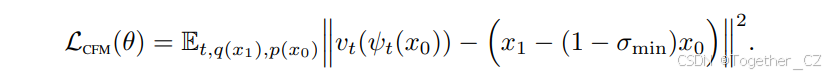
允许均值和标准差线性变化不仅导致简单且直观的路径,而且实际上在以下意义上也是最优的。条件流ψt(x)实际上是两个高斯分布p0(x∣x1)和p1(x∣x1)之间的最优传输(OT)位移映射。OT 插值,即概率路径,定义为(见McCann(1997)中的定义1.1):

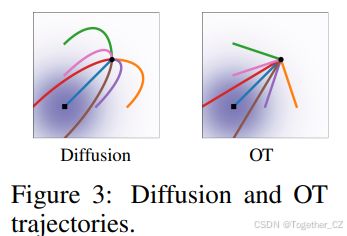
直观地说,在OT位移映射下,粒子总是沿直线轨迹并以恒定速度移动。图3展示了扩散和OT条件向量场的采样路径。有趣的是,我们发现扩散路径的采样轨迹可能会“超调”最终样本,导致不必要的回溯,而OT路径则保证保持直线。

5 相关工作
连续归一化流(CNF)在Chen等人(2018)中被引入,作为归一化流(NF)的连续时间版本(参见Kobyzev等人(2020);Papamakarios等人(2021)的概述)。最初,CNF通过最大似然目标进行训练,但这涉及昂贵的ODE模拟,用于前向和反向传播,导致由于ODE模拟的顺序性质而具有高时间复杂度。尽管一些工作展示了CNF生成模型在图像合成中的能力(Grathwohl等人,2018),但扩展到非常高维度的图像本质上具有挑战性。一些工作尝试通过正则化ODE使其更易于求解,例如使用数据增强(Dupont等人,2019),添加正则化项(Yang & Karniadakis,2019;Finlay等人,2020;Onken等人,2021;Tong等人,2020;Kelly等人,2020),或随机采样积分区间(Du等人,2022)。这些工作仅仅旨在正则化ODE,但并不改变基本的训练算法。

图4:(左)在2D棋盘数据上使用不同目标训练的CNF的轨迹。OT路径更早地引入了棋盘图案,而FM则实现了更稳定的训练。(右)使用中点法求解时,FM与OT结合实现了更高效的采样
为了加速CNF训练,一些工作开发了无模拟的CNF训练框架,通过显式设计目标概率路径和动力学。例如,Rozen等人(2021)考虑了先验和目标密度之间的线性插值,但涉及在高维空间中难以估计的积分,而Ben-Hamu等人(2022)考虑了与本文类似的一般概率路径,但在随机小批量训练中存在有偏梯度。相比之下,流匹配框架允许无偏梯度的无模拟训练,并易于扩展到非常高维度。
另一种无模拟训练方法依赖于构建扩散过程,以间接定义目标概率路径(Sohl-Dickstein等人,2015;Ho等人,2020;Song & Ermon,2019)。Song等人()表明,扩散模型通过去噪分数匹配(Vincent,2011)进行训练,这是一种条件目标,提供了关于分数匹配目标的无偏梯度。条件流匹配从这一结果中汲取灵感,但推广到直接匹配向量场。由于易于扩展,扩散模型受到了越来越多的关注,产生了各种改进,例如损失重缩放(Song等人,2021),添加分类器引导以及架构改进(Dhariwal & Nichol,2021),以及学习噪声计划(Nichol & Dhariwal,2021;Kingma等人,2021)。然而,(Nichol & Dhariwal,2021)和(Kingma等人,2021)仅考虑了由简单扩散过程定义的高斯条件路径的受限设置——特别是,它不包括我们的条件OT路径。在另一系列工作中,(De Bortoli等人,2021;Wang等人,2021;Peluchetti,2021)通过扩散桥理论提出了有限时间的扩散构造,解决了无限时间去噪构造中产生的近似误差。尽管现有工作利用了扩散过程与具有相同概率路径的连续归一化流之间的联系(Maoutsa等人,;Song等人,;2021),但我们的工作使我们能够推广到由简单扩散建模的概率路径类别之外。通过我们的工作,可以完全绕过扩散过程的构造,直接推理概率路径,同时仍然保持高效的训练和对数似然评估。最后,与我们的工作同时进行的(Liu等人,2022;Albergo & Vanden-Eijnden,2022)提出了类似的条件目标,用于无模拟训练CNF,而Neklyudov等人(2023)在假设ut为梯度场时推导了隐式目标。
6 实验
我们在CIFAR-10(Krizhevsky等人,2009)和ImageNet数据集上探索了使用流匹配的实证优势,分辨率为32、64和128(Chrabaszcz等人,2017;Deng等人,2009)。我们还对流匹配中的扩散路径选择进行了消融实验,特别是在标准方差保持扩散路径和最优传输路径之间。我们讨论了通过直接参数化生成向量场并使用流匹配目标来改进样本生成的方法。最后,我们展示了流匹配也可以用于条件生成设置。除非另有说明,否则我们使用dopri5(Dormand & Prince,1980)在绝对和相对容差为1e-5的情况下评估模型的似然性和样本。生成的样本见附录,所有实现细节见附录E。
表1:使用不同方法训练的相同模型的似然性(BPD)、生成样本的质量(FID)以及评估时间(NFE)

图6:使用在ImageNet 64×64上训练的模型,从相同的初始噪声生成的样本路径。OT路径大致线性地减少噪声,而扩散路径仅在路径的末端明显去除噪声。请注意生成图像之间的差异
密度建模和样本质量
我们首先比较了在CIFAR-10和ImageNet 32/64上训练的相同模型架构(即Dhariwal & Nichol(2021)中的U-Net架构,仅有少量改动),使用不同的流行扩散损失:DDPM(Ho等人,2020),分数匹配(SM)(Song等人,),以及分数流(SF)(Song等人,2021);详见附录E.1。表1(左)总结了我们的结果,与这些基线一起报告了每维比特的负对数似然(NLL),样本质量(通过Fréchet Inception Distance(FID;Heusel等人(2017))衡量),以及自适应求解器达到预设数值容差所需的平均函数评估次数(NFE),平均超过50k个样本。所有模型都使用相同的架构、超参数值和训练迭代次数进行训练,基线允许更多的迭代以实现更好的收敛。请注意,这些是_无条件_模型。在CIFAR-10和ImageNet上,FM-OT在所有定量指标上始终获得最佳结果,优于竞争方法。我们注意到CIFAR-10的FID性能高于之前的研究(Ho等人,2020;Song等人,;2021),这可能是因为我们使用的架构未针对CIFAR-10进行优化。
其次,表1(右)比较了使用OT路径在ImageNet分辨率128×128上训练的模型。我们的FID达到了最先进的水平,除了IC-GAN(Casanova等人,2021),它使用了带有自监督ResNet50模型的条件生成,因此不包括在此表中。附录中的图11、12、13展示了这些模型的非精选样本。
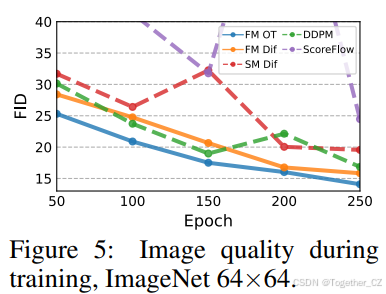
更快的训练。现有工作训练扩散模型时使用了非常多的迭代次数(例如,Score Flow和VDM分别报告了1.3m和10m次迭代),我们发现流匹配通常收敛得更快。图5展示了在ImageNet 64×64上训练期间流匹配和所有基线的FID曲线;FM-OT能够比其他方法更快地降低FID,并且效果更好。对于ImageNet-128,Dhariwal & Nichol(2021)训练了4.36m次迭代,批量大小为256,而FM(模型大小增加25%)使用了500k次迭代,批量大小为1.5k,即图像吞吐量减少了33%;详见表3。此外,对于分数匹配,采样成本在训练期间可能会大幅变化,而使用流匹配进行训练时,采样成本保持不变(附录中的图10)。
采样效率

采样路径。我们首先定性地可视化扩散和OT之间的采样路径差异。图6展示了使用相同随机种子的ImageNet-64模型的样本,我们发现OT路径模型比扩散路径模型更早开始生成图像,而扩散路径模型在最后时间点之前图像主要由噪声主导。我们还在2D棋盘图案生成中描绘了概率密度路径,图4(左),注意到类似的趋势。
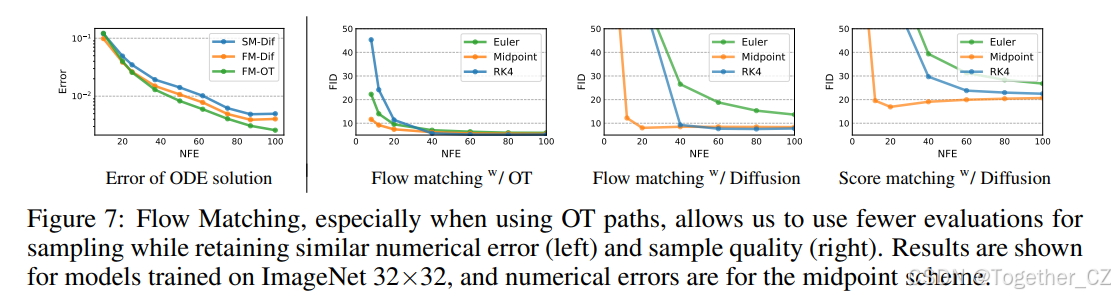
图7:流匹配,尤其是使用OT路径时,允许我们在保持相似数值误差(左)和样本质量(右)的情况下,使用更少的评估次数进行采样。结果显示了在ImageNet 32×32上训练的模型,数值误差为中点法
低成本采样。接下来,我们切换到固定步长求解器,并使用表1中的ImageNet-32模型比较了低(≤100)NFE采样。在图7(左)中,我们比较了低NFE解与1000 NFE解的每像素均方误差(我们使用了256个随机噪声种子),并注意到FM与OT模型在计算成本方面产生了最佳的数值误差,仅需大约60%的NFE即可达到与扩散模型相同的误差阈值。其次,图7(右)展示了由于计算成本的变化FID的变化,我们发现FM与OT即使在非常低的NFE值下也能实现不错的FID,与消融模型相比,提供了更好的样本质量与成本之间的权衡。图4(右)展示了2D棋盘实验的低成本采样效果。
从低分辨率图像进行条件生成
最后,我们使用流匹配进行了条件图像生成实验。特别是,将图像从64×64上采样到256×256。我们遵循(Saharia等人,2022)的评估程序,并计算了上采样的验证图像的FID;基线包括参考(原始验证集的FID)和回归。结果见表2。上采样的图像样本见附录中的图14、15。FM-OT在PSNR和SSIM值上与(Saharia等人,2022)相似,同时在FID和IS上显著改进,正如(Saharia等人,2022)所认为的那样,这是生成质量的更好指标。
7 结论
我们引入了流匹配,一种用于训练连续归一化流模型的新型无模拟框架,依赖于条件构造,轻松扩展到非常高维度。此外,FM框架为扩散模型提供了一个替代视角,并建议放弃随机/扩散构造,转而直接指定概率路径,使我们能够构建允许更快采样和/或改进生成的路径。我们在实验中展示了使用流匹配框架进行训练和采样的便捷性,并期望FM为允许多种概率路径(例如,非各向同性高斯或更一般的核)打开大门。
8 社会责任
除了其许多积极应用外,图像生成也可能被用于有害目的。使用内容控制的训练集和图像验证/分类可以帮助减少这些用途。此外,训练大型深度学习模型的能源需求正在迅速增加(Amodei等人,2018;Thompson等人,2020),专注于使用更少梯度更新/图像吞吐量的方法可以显著节省时间和能源。



















 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











