






这篇文章提出了一种名为SGFormer的简化单层图Transformer模型,旨在解决大规模图表示学习中的效率和可扩展性问题。主要内容如下:
-
问题背景:现有图Transformer通常采用多层注意力机制,计算复杂度高(O(N^2)),难以扩展到大规模图(如数百万或数十亿节点)。
-
主要贡献:
-
理论分析:证明多层传播可简化为单层传播,单层模型能达到与多层模型相当的表示能力。
-
模型设计:提出SGFormer,采用单层全局注意力机制,计算复杂度为O(N),无需近似处理全节点对交互。
-
高效性:SGFormer在大规模图上表现优异,可扩展到1亿节点的图(如ogbn-papers100M),并在中等规模图上实现数量级的推理加速。
-
-
模型架构:
-
单层全局注意力:捕捉全节点对交互,复杂度为O(N)。
-
混合传播层:结合全局注意力和基于图的传播(如GCN),兼顾全局交互和局部结构信息。
-
轻量设计:无需位置编码、特征预处理或额外损失函数,架构简单高效。
-
-
实验与结果:
-
数据集:在多个中等和大规模图数据集上实验,包括引用网络、社交网络和蛋白质相互作用网络。
-
性能对比:SGFormer在节点分类任务上显著优于现有GNN和图Transformer,尤其在异质图上表现突出。
-
效率与可扩展性:训练和推理时间比现有模型快数十倍,可扩展到1亿节点的超大规模图。
-
-
结论与未来工作:
-
结论:SGFormer通过简化架构,显著提升了大图上的可扩展性和效率,同时保持强大的表示学习能力。
-
未来工作:计划将SGFormer扩展到组合优化等更多应用场景。
-
SGFormer是一种高效的单层图Transformer,通过简化架构和降低计算复杂度,解决了大规模图表示学习的可扩展性问题,适用于大规模图任务。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
在大图上学习表示是一个长期存在的挑战,主要是由于节点之间的相互依赖性。Transformer最近在小图上表现出色,得益于其全局注意力机制,能够捕捉超越观察结构的全节点对交互。现有的方法倾向于继承Transformer在语言和视觉任务中的设计理念,采用复杂的多层注意力传播架构。本文试图评估在图Transformer中采用多层注意力的必要性,这显著限制了模型的效率。具体来说,我们分析了一个通用的混合传播层,该层由全节点对注意力和基于图的传播组成,并展示了多层传播可以简化为单层传播,且具有相同的表示学习能力。这为构建强大且高效的图Transformer提供了一条新的技术路径,特别是通过简化模型架构而不牺牲表达能力。作为示例,我们提出了简化单层图Transformer(SGFormer),其主要组件是一个单层全局注意力机制,该机制随图大小线性扩展,并且不需要任何近似来适应全节点对交互。实验表明,SGFormer成功扩展到包含1亿个节点的web-scale图ogbn-papers100M,在中等规模的图上相比同类Transformer实现了数量级的推理加速,并在有限标签数据下表现出竞争力。
关键词: 图表示学习,图神经网络,Transformer,线性注意力,可扩展性,效率
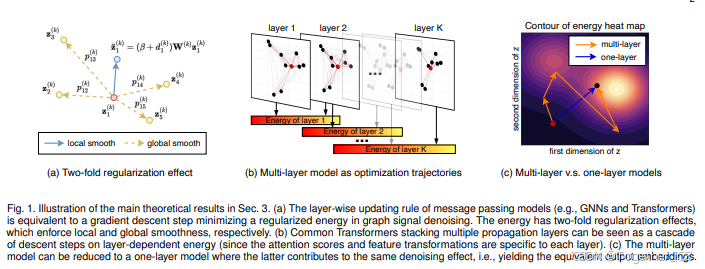
1 引言
在连接相互依赖数据点的大图上进行学习是机器学习和模式识别中的一个基本挑战,应用范围广泛,从社会科学到自然科学。一个关键问题是如何在有限的计算预算(如时间和空间)下获得有效的节点表示,即编码语义和拓扑特征的低维向量(也称为嵌入),以便在下游任务中高效使用。
最近,Transformer作为一种流行的基础编码器,通过将图中的节点视为输入标记,在图结构数据上表现出色,并在图级任务和节点级任务上展示了高度竞争力。Transformer的全局注意力机制可以捕捉图中未体现的节点间隐含依赖关系,这可能在数据生成中产生差异(例如,缺乏已知三级结构的蛋白质的未确定结构)。这一优势使Transformer在小图应用中比图神经网络(GNN)具有更强的表达能力,能够捕捉长程依赖和未观察到的交互。
然而,当前架构的一个令人担忧的趋势是它们倾向于自动采用Transformer在视觉和语言任务中的设计理念,即堆叠深层的多头注意力层,这导致模型规模庞大且数据需求高。然而,这种设计方法对Transformer扩展到包含数百万甚至数十亿节点的大图提出了重大挑战,特别是由于以下两个障碍:
-
全局全节点对注意力机制是现代Transformer的关键组成部分。由于全局注意力,Transformer的时间和空间复杂度通常随节点数量呈二次方增长,计算图随着层数的增加呈指数增长。因此,训练具有数百万节点的大图的深层Transformer可能极其耗费资源,并且可能需要精细的技术将相互连接的节点划分为较小的mini-batch以减轻计算开销。
-
在小图任务中,如图级预测分子属性,每个实例是一个图,通常有丰富的标记图实例,大型Transformer可能有足够的监督进行泛化。然而,在大图任务中,如节点级预测蛋白质功能,通常只有一个图,每个节点是一个实例,标记节点可能相对有限。这增加了具有复杂架构的Transformer在这些情况下学习有效表示的难度。
本文试图探讨在图表示中使用深层传播层的必要性,并探索简化Transformer架构的新技术路径,使其能够扩展到大规模图。
2 背景与相关工作
在本节中,我们介绍了分析的基础符号,并简要回顾了与本文相关的工作。
2.1 图神经网络
图神经网络(GNN)通过观察结构上的消息传递规则计算节点嵌入。GNN的逐层消息传递可以定义为递归传播邻居节点的嵌入以更新节点表示:

2.2 图Transformer
除了在局部邻域内的消息传递外,Transformer最近作为强大的图编码器获得了关注。这些模型使用全局全节点对注意力,聚合所有节点嵌入以更新每个节点的表示:

3 理论分析与动机
在介绍我们提出的模型之前,我们从理论角度出发,分析如何同时实现构建强大且可扩展的图Transformer的有效性和效率。
3.1 混合模型骨干
我们定义了一个模型骨干,其逐层更新规则由三个项组成:

3.2 从多层到单层的简化
我们进一步分析了使用多层传播是否是实现满意表达能力的必要条件,并提出了简化Transformer架构的潜在方法。

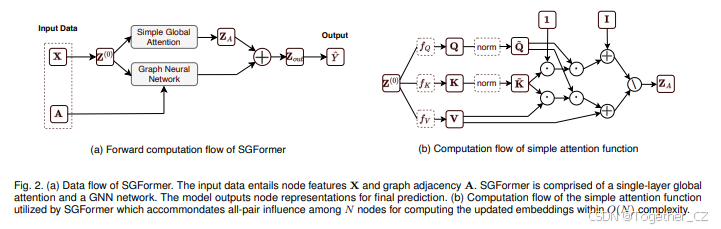
图2. (a) SGFormer的数据流。输入数据包括节点特征X和图邻接矩阵A。SGFormer由单层全局注意力机制和一个GNN网络组成。模型输出节点表示以进行最终预测。(b) SGFormer使用的简单注意力函数的计算流程,该函数在O(N)复杂度内计算N个节点之间的全节点对影响,以更新嵌入。
4 提出的模型
在本节中,我们介绍了我们的模型,称为简化图Transformer(SGFormer),在第三节的理论结果的指导下。总体而言,架构设计采用了公式19中的混合模型,并遵循奥卡姆剃刀原则进行具体实例化。特别是,SGFormer仅需要 O(N) 复杂度来适应全节点对交互并计算 N 个节点的表示。这是通过一个简单的注意力函数实现的,该函数具有先进的计算效率,并且不需要任何近似方案。除了可扩展性优势外,轻量级架构使SGFormer能够在有限标签的大图上进行学习。
4.1 模型设计



扩展到更大的图。对于更大的图,即使GCN也无法在单个GPU上进行全批量处理,我们可以使用[12]中使用的随机mini-batch分区方法,我们发现这种方法在实践中效果良好且高效。具体来说,我们随机打乱所有节点,并将节点划分为大小为 B 的mini-batch。然后在每次迭代中,我们将一个mini-batch(这些 B 个节点之间的输入图直接由原始图的子图提取)输入模型,以计算该mini-batch中训练节点的损失。该方案在训练期间产生的额外成本可以忽略不计,并且允许模型扩展到任意大的图。此外,由于SGFormer所需的节点数量线性复杂度,我们可以使用较大的批量大小(例如 B=0.1M),这有助于模型在每个mini-batch内捕捉节点之间的信息丰富的全局交互。除了这个简单的方案,我们的模型还兼容其他技术,如邻居采样[52]、图聚类[53]和历史嵌入[54]。这些技术可能需要额外的训练时间成本,我们将沿着这个正交方向的探索留给未来的工作。图2展示了所提出模型的数据流。
4.2 与现有模型的比较
我们接下来提供更深入的讨论,将我们的模型与现有技术进行比较,并阐明其在广泛应用场景中的潜力。表1展示了当前图Transformer在架构、表达能力和可扩展性方面的头对头比较。大多数现有的Transformer已经开发并优化用于小图上的图分类任务,而一些最近的工作则专注于节点分类的Transformer,由于图的大小,可扩展性的挑战出现了。
∙∙架构。关于模型架构,一些现有模型结合了边/位置嵌入(例如拉普拉斯分解特征[6]、度中心性[9]、Weisfeiler-Lehman标签[7])或利用增强的训练损失(例如边正则化[12, 41])来捕捉图信息。然而,位置嵌入需要一个额外的预处理过程,复杂度高达 ![]() ,这对于大图来说可能是时间和内存消耗的,而增强损失可能会使优化过程复杂化。此外,现有模型通常采用堆叠深层多头注意力层的默认设计以获得竞争性能。相比之下,SGFormer不需要任何位置嵌入、增强损失或预处理,并且仅使用单层、单头全局注意力,使其既高效又轻量。
,这对于大图来说可能是时间和内存消耗的,而增强损失可能会使优化过程复杂化。此外,现有模型通常采用堆叠深层多头注意力层的默认设计以获得竞争性能。相比之下,SGFormer不需要任何位置嵌入、增强损失或预处理,并且仅使用单层、单头全局注意力,使其既高效又轻量。
∙∙表达能力。最近提出的一些用于大图的图Transformer[11, 13, 44]将注意力计算限制在节点的子集上,例如邻域节点或从图中采样的节点。这种方法允许线性扩展图的大小,但牺牲了适应全节点对交互的表达能力。相比之下,SGFormer在每一层中保持对所有 N 个节点的注意力计算,同时仍然实现 O(N) 复杂度。此外,与NodeFormer[12]和GraphGPS[10]依赖随机特征映射作为近似不同,SGFormer不需要任何近似或随机组件,并且在训练期间更稳定。
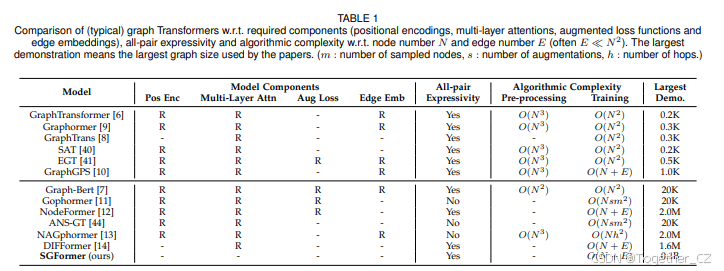
∙∙可扩展性。在算法复杂度方面,大多数现有的图Transformer由于全局全节点对注意力而具有![]() 复杂度,这是一个关键的计算瓶颈,阻碍了它们扩展到具有数千个节点的中等规模图。虽然邻居采样可以作为一种可行的补救措施,但它通常会由于显著减少的接收域而牺牲性能[25]。SGFormer随 N 线性扩展,并支持在具有多达0.1M个节点的大图上进行全批量训练。对于更大的图,SGFormer兼容使用大批量大小的mini-batch训练,这使得模型能够捕捉信息丰富的全局信息,同时对性能的影响可以忽略不计。值得注意的是,由于线性复杂度和简单架构,SGFormer可以在单个GPU上扩展到包含0.1B个节点的web-scale图ocbn-papers100M,比大多数图Transformer的最大演示大两个数量级。
复杂度,这是一个关键的计算瓶颈,阻碍了它们扩展到具有数千个节点的中等规模图。虽然邻居采样可以作为一种可行的补救措施,但它通常会由于显著减少的接收域而牺牲性能[25]。SGFormer随 N 线性扩展,并支持在具有多达0.1M个节点的大图上进行全批量训练。对于更大的图,SGFormer兼容使用大批量大小的mini-batch训练,这使得模型能够捕捉信息丰富的全局信息,同时对性能的影响可以忽略不计。值得注意的是,由于线性复杂度和简单架构,SGFormer可以在单个GPU上扩展到包含0.1B个节点的web-scale图ocbn-papers100M,比大多数图Transformer的最大演示大两个数量级。
5 实验评估
我们将SGFormer应用于现实世界的图数据集,其预测任务可以建模为节点级预测。后者通常用于评估学习图表示的有效性和扩展到大规模图的能力。我们在第5.1节中介绍了实现和数据集的详细信息。然后在第5.2节中,我们在中等规模的图(从2K到30K个节点)上测试SGFormer,并将其与一系列表达能力强的GNN和Transformer进行比较。在第5.3节中,我们将SGFormer扩展到大规模图(从0.1M到0.1B个节点),展示了其在可扩展GNN和Transformer上的优越性。随后在第5.5节中,我们进一步比较了不同标签数据比例下的性能。此外,我们在第5.4节中比较了模型的时间和空间效率以及可扩展性。在第5.6节中,我们分析了模型中几个关键组件的影响。第5.7节提供了关于单层模型与多层模型性能的进一步讨论。
5.1 实验细节
数据集。我们在12个具有不同属性的现实世界数据集上评估模型。它们的大小(以图中节点数量衡量)从千级到十亿级不等。我们使用0.1M作为阈值,并将这些数据集分为中等规模数据集(少于0.1M个节点)和大规模数据集(多于0.1M个节点)。中等规模数据集包括三个引用网络cora、citeseer和PubMed[55],这些图具有较高的同质性比率,以及四个异质图actor[56]、squirrel、chameleon[57]和deezer-europe[58],其中邻域节点往往具有不同的标签。这些图有2K-30K个节点,详细统计信息见表II。大规模数据集包括引用网络ocbn-array和pcbn-papers100M、蛋白质相互作用网络ocbn-proteins[27]、项目共现网络Amazon2M[59]和社交网络pokec[60]。特别是,Amazon2M包含长程依赖,而pokec是一个异质图。详细统计信息见表III,最大的数据集ocbn-papers100M包含超过0.1B个节点。
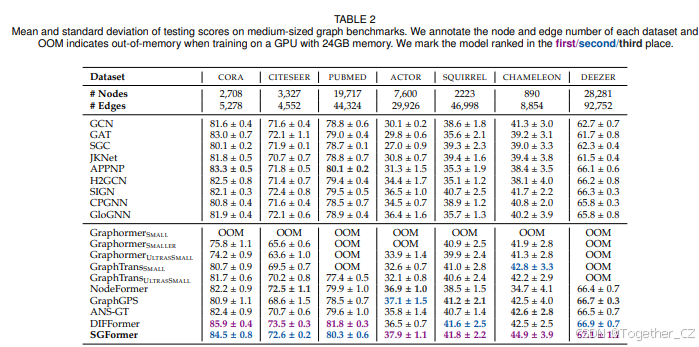

评估协议。我们遵循常见做法,设置固定的训练轮数:中等规模图为300轮,大规模图为1000轮,超大规模图OcBN-Papers100M为50轮。我们使用ROC-AUC作为OcBN-protems的评估指标,其他数据集使用准确率。使用在验证集上报告最高分数的模型的测试分数进行评估。我们使用不同的初始化运行每个实验五次,并报告指标的平均值和方差进行比较。
5.2 中等规模图的比较结果
设置。我们首先在中等规模数据集上评估模型。对于引用网络CORA、CITESEER和PUBMED,我们遵循常用的基准设置,即[29]采用的半监督数据分割。对于ACTOR和DEEZER-EUROPE,我们使用[61]引入的基准设置的随机分割。对于SQUIRREL和CHAMELEON,我们使用最近评估论文[62]提出的分割,该论文过滤了原始数据集中的重叠节点。
竞争对手。鉴于图的中等规模,大多数现有模型可以顺利扩展,我们从多个方面与多组竞争对手进行比较。基本上,我们采用标准GNN包括GCN[29]、GAT[30]和SGC[32]作为基线。此外,我们与高级GNN模型进行比较,包括JKNet[31]、APPNP[63]、SIGN[64]、H2GCN[33]、CPGNN[35]和GloGNN[34]。在Transformer方面,我们主要与最先进的可扩展图Transformer NodeFormer[12]、GraphGPS[10]、ANS-GT[44]和DIFFormer[14]进行比较。此外,我们调整了两个强大的Transformer,即Graphormer[9]和GraphTrans[8],用于比较。特别是,由于这些模型的原始实现规模较大,难以在所有节点级预测数据集上进行扩展,我们采用其较小版本进行实验。我们使用![]() (6层和32个头)、GraphormerSMALLER(3层和8个头)和
(6层和32个头)、GraphormerSMALLER(3层和8个头)和![]() (2层和1个头)。对于GraphTrans,我们使用
(2层和1个头)。对于GraphTrans,我们使用![]() (3层和4个头)和
(3层和4个头)和![]() (2层和1个头)。
(2层和1个头)。
结果。表II报告了所有模型的结果。我们发现SGFormer显著优于三个标准GNN(GCN、GAT和SGC),在Actor上比GCN提高了25.9%,这表明我们的单层全局注意力模型尽管简单,但确实有效。此外,我们观察到SGFormer在异质图Actor、SQUIRREL、CHAMELEON和DEEZER上相对于三个标准GNN的相对改进总体上更为显著。可能的原因是在这种情况下,全局注意力可以帮助过滤掉来自不同类别的邻域节点的虚假边,并适应图中未连接但信息丰富的节点。与其他高级GNN和图Transformer(NodeFormer、ANS-GT和GraphGPS)相比,SGFormer的性能具有高度竞争力,甚至在大多数情况下优于亚军。这些结果作为具体证据,验证了SGFormer作为节点级预测的强大学习者的有效性。我们还发现,Graphormer和GraphTrans都遭受了严重的过拟合,这可能是由于它们相对复杂的架构和有限的标记节点比例。相比之下,SGFormer的简单轻量架构使其在这些数据集中具有更好的泛化能力。
5.3 大规模图的比较结果
设置。我们进一步在节点数量从百万到十亿的大规模图数据集上评估模型。对于三个OGB数据集OcBN-ARXIV、OcBN-protems和OcBN-papers100M,我们使用[27]提供的公共分割。此外,我们遵循最近工作[12]对Amazon2M使用的分割,并采用1:1:8的随机分割对pokec。
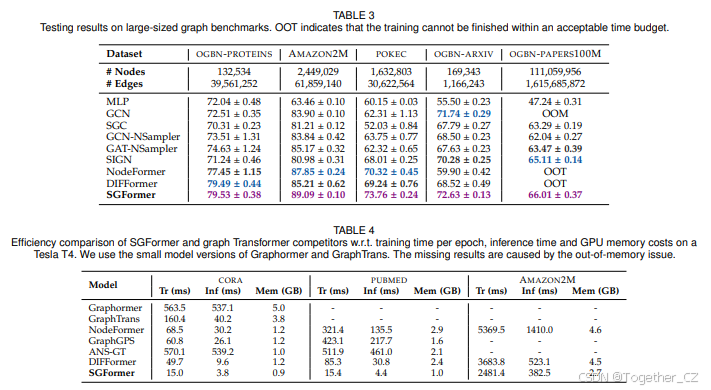
竞争对手。由于图的大小,大多数在第5.2节中比较的表达能力强的GNN和Transformer难以在可接受的时间和内存成本预算内扩展。因此,我们与MLP、GCN和两个可扩展GNN,即SGC和SIGN进行比较。我们还与使用邻居采样技术[52]的GNN进行比较:GCN-NSampler和GAT-NSampler。我们的主要竞争对手是NodeFormer[12]和DIFFormer[14],这是最近提出的具有全节点对注意力的可扩展图Transformer。
结果。表III展示了实验结果。我们发现SGFormer在五个数据集上始终表现出色,相对于GNN竞争对手有显著的性能提升。这表明全局注意力的有效性,可以学习大量节点之间的隐含依赖关系,超越输入结构。此外,SGFormer在所有情况下都明显优于NodeFormer,这展示了SGFormer的优越性,它使用更简单的架构并在大图上实现了更好的性能。对于最大的数据集OGBN-PAPERS100M,之前的Transformer模型未能展示,SGFormer顺利扩展,具有不错的效率,并产生了高度竞争力的结果。具体来说,SGFormer在单个GPU上训练约3.5小时和23.0 GB内存的情况下,达到了66.0的测试准确率。这一结果提供了强有力的证据,展示了SGFormer在极大图上的潜力,以有限的计算预算产生卓越的性能。
5.4 效率与可扩展性
我们接下来提供更多关于SGFormer与图Transformer竞争对手在不同规模数据集上的效率和可扩展性的定量比较。
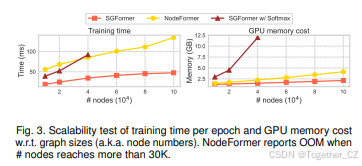
效率。表IV报告了在CORA、PUBMED和AMAZON2M上的每个epoch的训练时间、推理时间和GPU内存成本。由于这些数据集中的模型训练常见做法是使用固定的训练轮数,我们在这里报告每个epoch的训练时间以比较训练效率。我们发现,值得注意的是,SGFormer比其他竞争对手快几个数量级。与Graphormer和GraphTrans相比,它们需要二次复杂度进行全局注意力计算,并且难以扩展到具有数千个节点的图,SGFormer由于简单的 O(N) 复杂度全局注意力显著减少了内存成本。在时间成本方面,它在CORA上比Graphormer快38倍/141倍(训练/推理),在PUBMED上比NodeFormer快20倍/30倍。这主要是因为Graphormer需要计算二次全局注意力,这非常耗时,而NodeFormer还采用了增强损失和Gumbel技巧。对于GPU成本,SGFormer、NodeFormer和ANS-GT在两个中等规模图上的内存使用相当,而在大图AMAZON2M上,SGFormer比NodeFormer消耗的内存少得多。在大图AMAZON2M上,NodeFormer和SGFormer都利用mini-batch训练,SGFormer在训练和推理方面分别比NodeFormer快2倍和4倍。
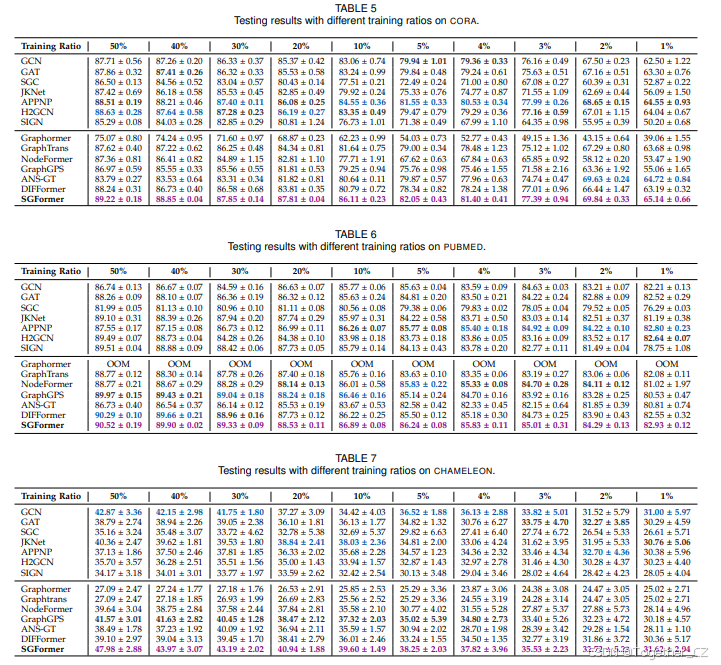
可扩展性测试。我们进一步测试了模型在单个计算批次内节点数量方面的可扩展性。我们采用Amazon2M数据集,并随机采样节点子集,节点数量从10K到100K不等。为了公平比较,我们为所有模型使用相同的隐藏大小256。在图3中,我们可以看到SGFormer的时间和内存成本都随图大小线性扩展。当节点数量达到40K时,用Softmax注意力替换我们注意力的模型(SGFormer w / Softmax)出现内存不足,相比之下,SGFormer仅消耗1.5GB内存。
5.5 有限标签数据的结果
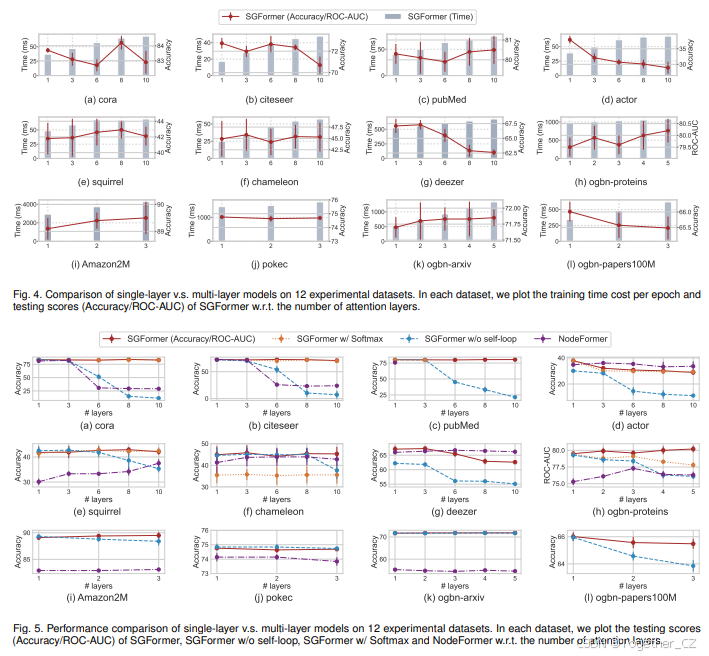
作为基准结果的扩展,我们接下来测试模型在不同数量标签数据下的表现,以研究模型在有限训练数据下的泛化能力。我们考虑三个数据集cora、pubmed和chameleon,并在每个数据集中随机将节点分割为训练/验证/测试,比例不同。具体来说,我们将验证和测试比例固定为25%,并将训练比例从50%更改为1%。表V、6和7分别展示了三个数据集上的实验结果,我们将SGFormer与GNN和Transformer竞争对手进行比较。我们发现,随着训练比例的降低,所有模型的性能都表现出一定程度的下降。相比之下,SGFormer保持了优越性,并在大多数情况下取得了最佳测试分数。这验证了我们的模型在有限训练数据下具有先进的学习能力,归功于其简单轻量的架构。
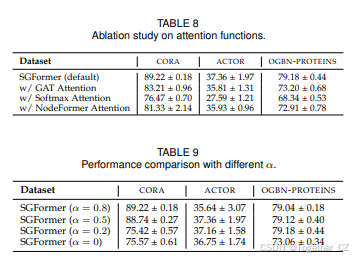
5.6 消融研究与超参数分析
除了比较实验外,我们提供了更多讨论以证明我们模型的有效性,包括关于不同注意力函数的消融研究以及超参数 α 的影响分析。
注意力函数的影响。SGFormer采用了一种新的注意力函数来计算全节点对交互以计算更新的节点嵌入。为了验证其有效性,我们将其替换为GAT[30]的注意力、[15]使用的Softmax注意力和NodeFormer[12]的注意力。表VIII展示了在CORA、ACTOR和PROTEINS上使用不同注意力函数的结果。我们发现默认的注意力函数在三个数据集上产生了最佳结果,这表明我们的设计在学习节点表示方面具有优越性。特别是,原始的Softmax注意力导致不令人满意的性能,与其他选择相比。这可能是由于[12]识别的过度归一化问题,即Softmax操作后的归一化注意力分数往往集中在极少数节点上,并在优化过程中导致其他节点的梯度消失。相比之下,SGFormer使用的线性注意力函数通过点积直接计算全节点对相似度,可以克服过度归一化问题。
α 的影响。超参数 α 控制GN模块和全节点对注意力在计算聚合嵌入时的权重。具体来说,较大的 α 意味着更多的权重附加到GN模块和输入图上以计算表示。在表IX中,我们报告了在三个数据集上不同 α 设置的结果,这表明 α 的最佳设置因情况而异。特别是,α=0.8 在cora上产生了最佳结果,可能是因为该数据集具有较高的同质性比率,输入图对预测任务有用。不同的是,对于异质图action,我们发现使用 α=0.5 实现了最佳性能。这是因为在这种情况下,观察到的结构可能是有噪声的,全节点对注意力对于学习有用的未观察到的交互变得重要。类似的情况适用于proteins,这也是一个异质图,我们发现设置相对较小的αα 会导致最高的测试分数。事实上,输入图的信息量在实践中可能因情况而异,取决于数据集的性质和下游任务。SGFormer允许通过调整权重 α 来控制附加到输入结构的重要性,具有足够的灵活性。
5.7 进一步讨论
我们继续分析模型层数对性能的影响,并进一步比较不同数据集上的单层和多层模型。图4和5展示了12个数据集上的实验结果。
SGFormer的单层与多层注意力。在图4中,我们绘制了当全局注意力层数从一层增加到多层时,SGFormer的每个epoch的训练时间和测试性能。我们发现使用更多层并不会带来显著的性能提升,反而在某些情况下(例如异质图action和deezer)导致性能下降。更糟糕的是,多层注意力需要更多的训练时间成本。值得注意的是,使用SGFormer的单层注意力可以始终产生与多层注意力相当的高度竞争力性能。这些结果验证了第III节中的理论结果以及我们单层注意力的有效性,它具有所需的表达能力和卓越的效率。
其他Transformer的单层与多层注意力。在图5中,我们展示了SGFormer、NodeFormer、SGFormer w/o self-loop(移除公式23中的自环传播)和SGFormer w/ Softmax(用Softmax注意力替换我们的注意力)的测试性能,分别与不同注意力层数的模型进行比较。我们发现,对于这些模型的单层注意力实现,在许多情况下可以产生不错的结果,这表明对于其他全局注意力的实现,使用单层模型也具有竞争性能的潜力。在某些情况下,例如,NodeFormer在ogen-proteins上使用一层时产生了不令人满意的结果。这可能是因为NodeFormer在每一层中耦合了全局注意力和局部传播,使用单层模型可能会牺牲后者的有效性。在此基础上,我们可以看到,探索有效且稳定的浅层注意力模型可能是一个有前途的未来方向。我们还发现,当使用更深的模型深度时,SGFormer w/o self-loop表现出明显的性能下降,并且比SGFormer的结果差得多,这表明公式23中的自环传播有助于保持SGFormer在多层注意力下的竞争力。
6 结论
本文旨在解锁简单Transformer风格架构在学习大规模图表示中的潜力,其中可扩展性挑战成为瓶颈。通过对Transformer在图上的学习行为进行分析,我们揭示了一种通过简化架构到单层模型来构建强大Transformer的潜在方法。基于此,我们提出了简化图Transformer(SGFormer),它具有捕捉全节点对交互的所需表达能力,且仅需一层注意力的最小成本。简单轻量的架构使其能够顺利扩展到包含0.1B个节点的大图,并在中等规模图上相比同类Transformer实现了显著的加速。在我们的技术贡献之上,我们相信这些结果可以为构建强大且可扩展的大规模图Transformer提供新的有前途的方向,这一领域目前尚未得到充分探索。未来的工作,我们计划将SGFormer扩展到解决组合问题的设置[65, 66, 67],其中GNN已成为流行的骨干。



















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











