






这篇文章提出了一种名为 MM-Tracker 的多目标跟踪(MOT)方法,专门用于无人机(UAV)平台上的目标跟踪。文章的主要贡献和创新点如下:
-
问题背景:
-
无人机平台上的多目标跟踪面临两个主要挑战:局部目标运动和全局相机运动,以及由运动引起的运动模糊问题。
-
现有的方法要么只关注局部运动,要么忽略了运动模糊的影响,导致跟踪性能受限。
-
-
提出的方法:
-
Motion Mamba模块:通过局部互相关和双向Mamba模块来建模目标的局部和全局运动特征,实现了高效的运动建模。
-
Motion Margin Loss (MMLoss):针对运动模糊问题,提出了运动边界损失函数,通过为运动较大的目标分配更大的分类边界,提高了对运动模糊目标的检测精度。
-
-
实验与结果:
-
在两个公开的无人机MOT数据集(Visdrone和UAVDT)上进行了实验,结果表明MM-Tracker在跟踪精度(MOTA和IDF1)和推理速度上均优于现有的最先进方法。
-
消融实验验证了Motion Mamba模块和MMLoss的有效性,两者结合使用显著提升了跟踪性能。
-
-
主要贡献:
-
提出了Motion Mamba模块,实现了快速准确的运动建模。
-
提出了Motion Margin Loss,有效解决了运动模糊目标的检测问题。
-
在无人机MOT任务中,MM-Tracker达到了最先进的性能,推动了该领域的发展。
-
这篇文章通过创新的运动建模和损失函数设计,显著提升了无人机平台上多目标跟踪的性能,特别是在处理运动模糊和全局相机运动方面表现出色。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
摘要:
无人机平台上的多目标跟踪(MOT)需要高效的运动建模,因为无人机MOT同时面临局部目标运动和全局相机运动的挑战。运动模糊也增加了检测大运动目标的难度。以往的无人机运动建模方法要么仅关注局部运动,要么忽略运动模糊效应,从而限制了其跟踪性能和速度。为了解决这些问题,我们提出了Motion Mamba模块,通过互相关和双向Mamba模块探索局部和全局运动特征,以实现更好的运动建模。为了应对运动模糊带来的检测困难,我们还设计了运动边界损失,有效提高了运动模糊目标的检测精度。基于Motion Mamba模块和运动边界损失,我们提出的MM-Tracker在两个广泛开源的无人机MOT数据集中超越了现有技术。
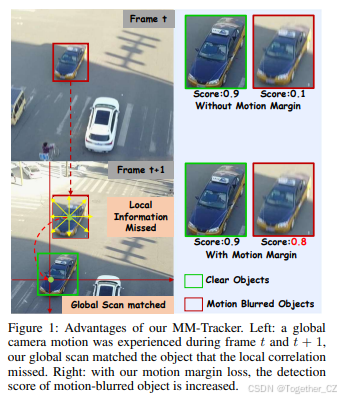
图1:我们的MM-Tracker的优势。左图:在帧t和t+1之间发生了全局相机运动,我们的全局扫描匹配到了局部相关错过的目标。右图:通过我们的运动边界损失,运动模糊目标的检测得分得到了提高。
1. 引言
多目标跟踪(MOT)旨在识别给定视频中的目标,并广泛应用于计算机视觉领域(Luo等,2021;Kalake等,2021),包括自动驾驶(Geiger等,2013)、人机交互(Chandra等,2015)和行人跟踪(Peng等;Meinhardt等,2022)。典型的MOT方法包括两个主要阶段:检测和关联(Shuai等,2021)。检测阶段识别每帧中的所有目标,而关联阶段则在连续帧之间匹配目标,以建立每个目标的完整轨迹(Liu等)。近年来,无人机平台上的MOT引起了广泛的研究兴趣。与传统的MOT(Dendorfer等,2020)相比,无人机视角下的MOT面临更多挑战。首先,无人机MOT任务中同时存在地面目标运动和空中相机运动,这对跟踪器准确跟踪目标提出了挑战。其次,相机运动引起的严重运动模糊(Kurimo等,2009)将显著增加目标检测的难度。
卡尔曼滤波及其各种变体是非常常用的运动建模方案(Bewley等,2016;Cao等,2023;Zhang等,2022;Liu等,2023)。然而,卡尔曼滤波是一种非学习算法,只能对运动做出预先假设(例如假设线性运动),因此在相机运动场景中的精度有限。一些研究(Shuai等,2021;Zhou等,2020;Yao等,2023)提出了基于学习的运动建模,但大多数基于局部互相关或局部卷积,忽略了全局运动信息。因此,缺乏全局运动建模限制了这些跟踪器在具有显著全局相机运动的场景中的跟踪精度。此外,以往的研究忽略了无人机MOT数据集中存在的运动长尾分布。因此,具有显著运动的目标(难以检测)接受的训练较少,而易于检测的目标(运动较小)接受的训练较多。
为了解决这些问题,我们提出了MM-Tracker,用于快速准确的运动建模和专注于运动模糊的目标检测器训练。与以往的工作不同,MM-Tracker从双时态目标检测特征中估计目标运动,这大大减少了运动建模的计算量。此外,MM-Tracker通过提出运动边界损失函数,对具有较大运动的目标施加更大的分类损失,从而有效提高了运动模糊目标的检测性能。本文的主要贡献总结如下:
-
我们提出了Motion Mamba模块,通过检测特征的局部相关性和双向Mamba块的全局扫描来建模目标运动,实现了快速准确的运动建模。
-
我们提出了运动边界损失(MMLoss),对具有较大运动的目标施加更大的决策边界,以监督目标检测器,并提高了运动模糊目标的检测性能。
-
基于Motion Mamba模块和运动边界损失提出的MM-Tracker在两个公开的无人机MOT数据集上达到了最先进的水平,推动了无人机场景中多目标跟踪的进展。
2. 相关工作
2.1 MOT中的运动建模
现有的MOT方法通常遵循检测和关联方案(Luo等,2021;Fagot-Bouquet等,2016;Peng等)。关联标准可以分为两类:位置信息(Zhao等,2012;Forsyth等,2006;Takala和Pietikainen,2007)和外观信息(Sugimura等,2009;Li等,2013;Yang和Nevatia,2012;Peng等,2018)。基于位置信息的关联需要建模目标运动以预测目标在下一时刻的位置(Bewley等,2016;Shuai等,2021;Zhou等,2020;Zhang等,2022;Bochinsk等,2017),而基于外观信息的方法需要提取目标的外观信息以计算目标在帧之间的外观相似性(Wojke等,2017;Zheng等,2016;Wang等;Zhang等,2021)。在无人机MOT场景中,目标尺寸小、外观模糊以及地面车辆之间的外观非常相似,使得外观信息在目标关联中不可靠(Yao等,2023)。因此,本工作专注于运动建模作为关联。
MOT中最常用的运动建模方法是卡尔曼滤波(KF)(Kalman,1960)及其各种变体(Bewley等,2016;Cao等,2023;Zhang等,2022)。这些方法需要对目标运动模式及其概率分布进行先验假设,没有任何可学习参数,这限制了它们在具有人为全局相机运动的场景中的性能。一些研究(Zhou等,2020;Shuai等,2021;Yao等,2023)引入了可学习的神经网络来学习目标的运动。这些方法比基于预设规则的方法表现更好。然而,它们主要由局部卷积和互相关组成,因此对全局运动的建模有限。此外,这些方法还存在重复特征提取的问题,引入了冗余计算。
2.2 有效的全局信息聚合
一些研究(Azad等,2019;Wang等,2018;Huang等,2021)将序列模型(例如RNN(Elman,1990),LSTM(Hochreiter和Schmidhuber,1997))与卷积结合以提取全局图像特征。然而,它们的递归推理方案使得它们难以并行训练,导致训练速度较慢。它们的堆叠序列架构也容易出现梯度爆炸或消失等问题。通过引入全局注意力机制,Transformer模型(Vaswani等,2017)有效克服了训练并行性低和梯度消失的问题,因此在长序列文本任务(如语言建模(Subakan等,2021))中取得了成功。然而,对于图像的全局信息建模(Choi等,2020;Liu等,2021),Transformer的计算复杂度太大,例如O(n2)O(n2),容易过拟合且难以实现实时跟踪。Mamba(Gu和Dao,2023)的出现带来了更高效的全局信息提取方案,可以在线性时间内实现全局注意力计算,同时也能很好地并行训练。因此,本文采用双向扫描的Mamba结构来计算全局信息聚合,从而更好地预测长距离目标运动。
2.3 不平衡训练损失
传统的不平衡训练(Wang等)指的是不同类别之间的不平衡,即多个类别在数据集中只占很小比例,而少数类别占数据集的很大比例。这种不平衡导致训练样本较少的类别没有得到充分训练,影响了分类精度。许多学者提出了解决这一问题的方法,例如重采样(Huang等,2016;Li等,2020;Ren等,2020)、损失重加权(Lin等,2017;Li等,2021,2022)、重新调整边界(Cao等,2019;Wang等,2018;Menon等,2020)。
在无人机MOT场景中,相机视角的变化会导致目标的大幅度运动,而这种视角变化是偶然的,使得这种情况在数据集中占比较小。然而,大运动会在目标上引入严重的运动模糊,要求我们更多地关注那些难以检测的目标,而这一点在以往的研究中被忽略了。为此,我们提出了运动边界损失,对具有较大运动的目标施加更大的分类边界,从而更好地解决大运动目标训练不足的问题。
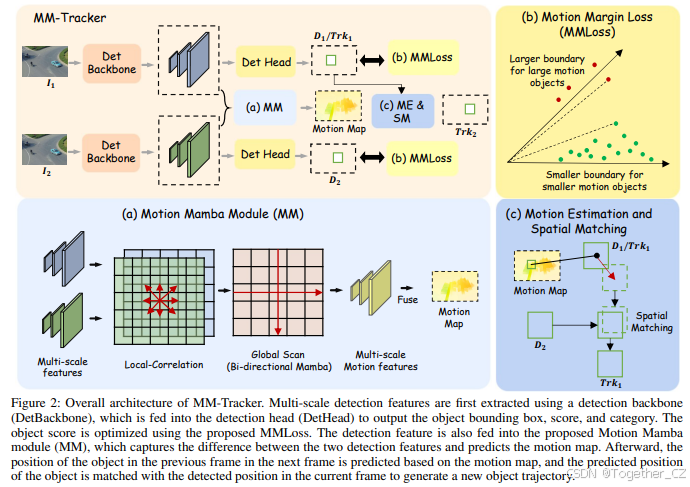
图2:MM-Tracker的整体架构。首先使用检测骨干网络(DetBackbone)提取多尺度检测特征,这些特征被输入到检测头(DetHead)中,输出目标边界框、得分和类别。目标得分通过提出的MMLoss进行优化。检测特征还被输入到提出的Motion Mamba模块(MM)中,该模块捕捉两个检测特征之间的差异并预测运动图。随后,基于运动图预测前一帧中目标在下一帧中的位置,并将预测的目标位置与当前帧中检测到的位置进行匹配,生成新的目标轨迹。
3. 提出的方法
3.1 概述
为了实现高效的全局运动建模和快速的跟踪速度,我们设计了一个具有特征重用方案的Motion Mamba块。此外,为了更好地检测运动模糊的目标,我们提出了运动边界损失函数来监督目标检测器的分类分支。图2展示了我们提出的MM-Tracker的整体架构。DetBackbone从视频的每一帧中提取检测特征,这些特征被输入到DetHead中进行目标检测,并输入到Motion Mamba模块中进行运动特征提取。DetBackbone生成三个尺度的特征图,其大小分别为原始图像大小的1/8、1/16和1/32。DetHead在这三个尺度上分别检测目标。检测器的分类分支由提出的MMLoss监督,回归分支由IOU Loss和L1 Loss监督。Motion Mamba模块分别从三个尺度的双时态检测特征中提取运动特征。然后,该模块从最低尺度逐步上采样特征并与更高尺度融合,最后生成大小为原始图像1/8的运动特征图。最后,该特征图通过L1 Loss与真实运动图进行监督。真实运动图的生成方式如图4所示。DetBackbone和DetHead分别是YOLOX的骨干和YOLOX的头部。
3.2 Motion Mamba模块
Motion Mamba模块致力于高效且轻量级的运动建模。因此,该模块从先前和后续图像的现有检测特征中提取运动特征,这大大降低了模型的计算复杂度。Motion Mamba模块在三个尺度上提取运动特征。然后,这些多尺度特征从最低尺度逐步融合,最后输出大小为原始图像1/8的运动特征图。对于每个尺度,Motion Mamba首先使用先前和后续时刻特征图的互相关来提取局部运动信息,然后使用Motion Mamba块来提取全局运动特征。如图3所示,每个Motion Mamba块由两个分支组成:垂直状态空间模型(V-SSM)和水平状态空间模型(H-SSM)。这两个分支分别在垂直和水平方向上进行选择性扫描(Gu和Dao,2023)。为了在降低计算复杂度的同时充分扫描整个特征图,每次扫描使用像素位置的向量作为基本单元。具体来说,对于高度、宽度和通道分别为(H,W,C)的特征图,垂直扫描从每列的第一行开始,以大小为(1,1,C)的特征向量作为输入,扫描到最后一行。每列的扫描是单独进行的,总共进行W组扫描。水平SSM扫描总共进行H组,遵循与垂直扫描相同的方案。垂直扫描的特征图和水平扫描的特征图相加以实现全局特征交互。还采用了原始输入到输出的短连接以加速训练。特征图的顶层通过卷积输出大小为(1/8H,1/8W,2)的特征图,其中第一个通道表示水平运动,第二个通道表示垂直运动。
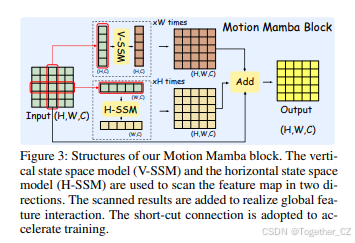
图3:我们的Motion Mamba块的结构。垂直状态空间模型(V-SSM)和水平状态空间模型(H-SSM)用于在两个方向上扫描特征图。扫描结果相加以实现全局特征交互。采用短连接以加速训练。
状态空间模型 我们Motion Mamba中使用的状态空间模型(Gu和Dao,2023)通过序列的迭代计算得出:

运动真实值生成 如图4所示,我们首先使用预训练的EMD-Flow(Deng等,2023)网络生成数据集中每一帧的光流图。然后我们计算数据集中每个标注目标在前后帧之间的中心偏移,并将偏移值重叠在目标的边界框范围内的原始光流图上。该图用作真实运动图以监督Motion Mamba模块。引入的光流图有助于加速运动模型的收敛。使用目标运动真实值还充分利用了原始数据集的标注信息。
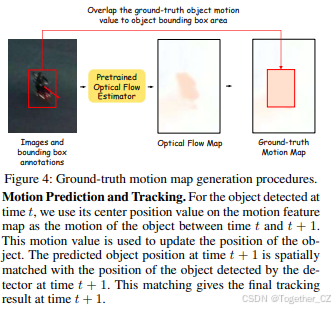
图4:真实运动图的生成过程。
运动预测与跟踪。对于在时间t检测到的目标,我们使用其在运动特征图上的中心位置值作为目标在时间t和t+1之间的运动。该运动值用于更新目标的位置。在时间t+1预测的目标位置与检测器在时间t+1检测到的目标位置进行空间匹配。该匹配给出了时间t+1的最终跟踪结果。
运动边界损失
相机视角的旋转引入了图像中目标的大幅度运动,导致严重的运动模糊。这种运动模糊将大大增加目标检测的难度。然而,由于数据集中这种情况较少,这些难以检测的样本比容易样本的训练次数少,这进一步增加了检测难度。对于目标跟踪任务,即使有几帧无法检测到,也会导致跟踪中断,大大影响跟踪精度。为此,我们提出了运动边界损失函数,根据目标的运动分配不同的决策边界。我们对具有较大运动的目标分配更大的决策边界,从而迫使模型在学习过程中为具有较大运动的目标输出更高的分数,以便在推理过程中有效检测这些目标。具体来说,我们根据目标偏移x计算每个目标帧的运动边界:
![]()
其中M定义为:
![]()
运动边界函数的设计遵循以下标准:(1)当目标运动为0时,不设置边界。(2)目标的运动越大,运动边界值越大。(3)随着目标运动的增加,运动边界逐渐收敛。图5展示了不同s值的运动边界函数曲线,表明该函数满足这三个标准。
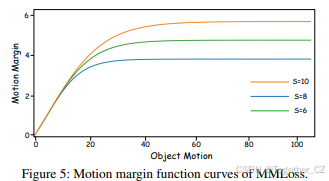
从观察到大约30像素的运动会导致较大的运动模糊开始,我们选择s=10作为MMLoss的参数。图5显示,当s=10时,运动边界在30以上趋于饱和。
对于每个目标框的分类,运动边界损失定义为:

4. 实验
4.1 数据集和指标
数据集 我们在Visdrone(Zhu等,2020)和UAVDT(Du等,2018)数据集上进行了对比实验。这两个数据集是开源的多类多目标跟踪数据集,并且都是从无人机的视角收集的。因此,研究这两个数据集中具有全局运动和运动模糊问题的跟踪目标是合适的。

图6:大运动场景的可视化结果。没有Motion Mamba的模型错过了道路上快速移动的三轮车,而带有Motion Mamba的模型成功跟踪了它们,并分配了ID 20、25和47。
Visdrone数据集包括训练集(56个序列)、验证集(7个序列)、测试开发集(7个序列)和测试挑战集(6个序列)。Visdrone数据集中有10个类别:行人、人、汽车、货车、公交车、卡车、摩托车、自行车、遮阳三轮车和三轮车。上述类别中的每个目标都由边界框、类别编号和唯一标识号进行标注。在Visdrone的实验中,我们在训练中使用全部十个类别,而在测试中仅使用五个类别进行评估,即汽车、公交车、卡车、行人和货车,因为Visdrone官方提供的评估工具包仅评估这五个类别。
UAVDT数据集是一个基于航拍视角的汽车跟踪数据集。它包括不同的常见场景,如广场、主干道和收费站。UAVDT数据集包括训练集(30个序列)和测试集(20个序列),有三个类别:汽车、卡车和公交车。在UAVDT的实验中,使用Visdrone的官方评估工具包评估所有三个类别。
指标 我们选择MOTA和IDF1作为主要评估指标。
4.2 实现细节
在所有实验中,我们保持与Visdrone和UAVDT数据集的官方划分相同的训练-测试划分。我们在两个数据集上使用YOLOX-S(Ge等,2021)模型作为基础目标检测器,输入图像大小为1088×608。我们使用随机梯度下降法(Bottou,2010)优化检测器,学习率设置为0.0001,批量大小设置为8,每个数据集训练10个epoch,训练和测试在单张2080TI显卡上完成。Motion Mamba模块和检测器的目标回归分支使用L1损失函数进行训练。检测器的目标分类分支使用提出的MMLoss进行训练。我们选择Visdrone数据集官方提供的精度评估工具来完成所有指标的对比。

4.3 消融实验
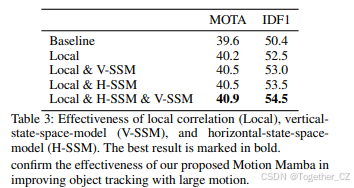
Motion Mamba模块的有效性 我们首先评估了Motion Mamba模块的有效性。如表2所示,与仅使用局部互相关的基线模型相比,Motion Mamba模块在Visdrone测试集上的MOTA和IDF1分别提高了1.3%和4.1%。我们还比较了Motion Mamba模块与其他全局运动建模方法(如FastFlowNet、GMA和EMD-Flow)的性能。如表2所示,Motion Mamba模块在MOTA和IDF1上均优于这些方法,并且在推理时间上显著更快(6.9ms vs. 11ms、102ms和115ms)。我们还评估了Motion Mamba模块中不同组件的贡献。如表3所示,仅使用局部互相关的模型在MOTA和IDF1上表现最差(39.6%和50.4%),而结合两个SSM的模型在不同方向上实现了最佳的跟踪精度(MOTA为40.9%,IDF1为54.5%)。综上所述,上述定性和定量结果证实了我们提出的模块的有效性。

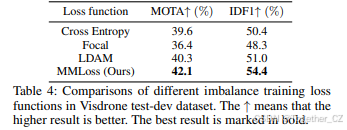
MMLoss的有效性 我们进一步评估了MMLoss在提高运动模糊目标检测性能方面的有效性。如表4所示,与交叉熵损失、Focal损失和LDAM损失相比,MMLoss在Visdrone测试开发集上的MOTA和IDF1分别提高了2.5%和4.0%。图7可视化了我们的消融结果。如图7所示,使用MMLoss的模型成功跟踪了外观模糊的移动骑行者(标记为ID 38),而基线模型未能跟踪到它。上述定性和定量结果证实了我们提出的损失函数的有效性。
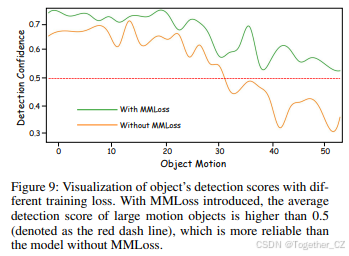
我们进一步研究了MMLoss在提高快速移动目标检测方面的有效性。如图9所示,引入MMLoss有效提高了大运动目标(具有较大相对速度的目标)的平均目标分数。使用MMLoss时,大运动目标的平均分数高于0.5,比没有MMLoss的模型更可靠。
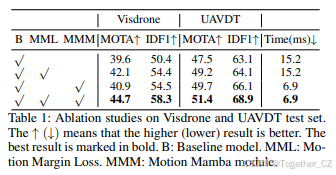
组合使用 我们还评估了我们的MMLoss和Motion Mamba组合使用的有效性。如表1所示,Motion Mamba和MMLoss都能有效提高Visdrone数据集上的跟踪性能(MOTA从39.6%提高到40.9%和42.1%,IDF1从50.4%提高到54.5%和54.4%)和UAVDT数据集上的跟踪性能(MOTA从47.5%提高到49.7%和49.2%,IDF1从63.1%提高到66.1%和64.1%)。当MMLoss和Motion Mamba共同使用时,获得了最佳的跟踪性能(Visdrone上的MOTA为44.7%,IDF1为58.3%;UAVDT上的MOTA为51.4%,IDF1为68.9%),并且运动推理时间低于基线模型(从15.1ms降低到6.9ms)。
4.4 与最先进方法的比较
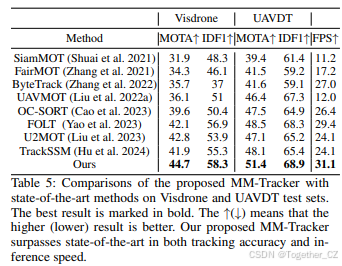
如表5所示,本文提出的MM-Tracker在MOTA和IDF1上超过了当前最先进(SOTA)的方法。我们还在Visdrone数据集和UAVDT数据集中可视化了最新最佳方法(OC-SORT和FOLT)与我们的MM-Tracker的比较结果。如图8左侧所示,我们的MM-Tracker成功跟踪了T1和T2帧中的小型快速移动的公交车和卡车(目标ID为1、15和12),而OC-SORT未能跟踪到这三辆车,FOLT未能跟踪到半遮挡的卡车(ID 12)。如图8右侧所示,相机和目标都在运动,引入了大而不规则的运动,导致目标特征模糊。在这种困难情况下,我们的MM-Tracker成功跟踪了T1帧中的所有五辆汽车,而OC-SORT错过了左下角的汽车,FOLT在T1时刻和T2时刻对同一辆汽车(ID 72,61和72,75)进行了重复跟踪。FOLT还错过了由于大而不规则运动而严重模糊的右上角汽车。
5. 结论
为了实现高效和快速的全局运动建模,我们提出了Motion Mamba模块。Motion Mamba基于目标检测器提取的特征估计运动图,大大降低了运动建模的计算成本。引入的双向选择性扫描模块有效提取了全局运动特征,因此在无人机MOT场景中优于以往的运动建模方法。为了解决当前无人机MOT数据集中的运动不平衡训练问题,我们提出了运动边界损失(MMLoss),根据目标的运动监督目标检测器,并提高了快速移动目标的检测性能。实验表明,MMLoss和Motion Mamba都能提高无人机视角下多目标跟踪的准确性。与最先进方法的比较表明,我们的MM-Tracker在两个公开的无人机MOT数据集上在跟踪精度和推理速度方面均取得了最佳结果。



















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











