






这篇文章的核心内容是关于如何量化和评估大型语言模型(LLMs)的蒸馏程度,旨在提高LLMs开发的透明度和多样性,并减少因过度蒸馏导致的模型同质化问题。以下是文章的主要内容总结:
研究背景
-
模型蒸馏:将大型语言模型(LLMs)的知识转移到较小模型的技术,以实现资源高效且性能卓越的模型。
-
问题:过度蒸馏可能导致模型同质化,降低模型多样性,削弱处理复杂或新颖任务的能力。
研究目标
-
提出一种系统化的方法来量化LLMs的蒸馏程度。
-
评估不同LLMs的蒸馏程度,揭示其对模型多样性和鲁棒性的影响。
-
呼吁更具独立性和透明度的LLM开发。
方法
文章提出了两个量化LLMs蒸馏的关键方法:
-
响应相似性评估(RSE):通过比较原始LLM和目标LLM在不同数据集上的响应,评估它们在风格、逻辑结构和内容细节上的相似性。
-
身份一致性评估(ICE):利用越狱技术(如GPTFuzz)生成提示,绕过LLMs的自我意识,检测模型在身份认知上的矛盾,从而揭示蒸馏程度。
实验
-
实验设置:选择多个知名的LLMs进行测试,包括Claude、Doubao、GLM4-Plus等。
-
实验结果:
-
ICE结果:GLM4-Plus、Qwen-Max和Deepseek-V3表现出较高的蒸馏程度;Claude和Doubao表现出较低的蒸馏程度。
-
RSE结果:GPT系列模型(如GPT4o-0513)表现出最高的响应相似性;Llama3.1-70B-Instruct和Doubao-Pro-32k表现出较低的相似性。
-
基础LLMs vs. 对齐LLMs:基础LLMs通常表现出更高的蒸馏程度。
-
关键结论
-
高蒸馏程度:大多数知名的闭源和开源LLMs表现出较高的蒸馏程度,但Claude、Doubao和Gemini是例外。
-
基础LLMs:基础LLMs相比对齐LLMs表现出更高的蒸馏程度。
-
透明度和独立性:通过提供系统化的方法来评估LLMs的蒸馏程度,文章呼吁开发更具独立性和透明度的LLMs,以提高模型的鲁棒性和安全性。
意义
-
提供了一种量化LLMs蒸馏程度的方法,有助于评估模型的多样性和鲁棒性。
-
呼吁更透明的LLM开发过程,减少因过度蒸馏导致的模型同质化问题。
-
为未来的LLM研究和开发提供了新的视角和工具。
这篇文章的核心贡献在于提出了量化LLMs蒸馏程度的具体方法,并通过实验验证了这些方法的有效性,为LLM的开发和评估提供了新的思路。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:

摘要
数据蒸馏技术是构建大型语言模型(LLMs)中常用的技术之一。我们的研究专注于量化和评估LLM蒸馏的程度,旨在促进LLM核心技术的更大透明度和多样性。禁止将本研究用作公司或国家之间竞争和攻击的工具。
模型蒸馏是一种将大型语言模型(LLMs)的知识转移到较小模型的技术,目标是创建资源高效且性能卓越的模型。然而,过度的蒸馏可能导致同质化,降低模型之间的多样性,并削弱它们处理复杂或新颖任务的能力。这些限制凸显了系统量化蒸馏过程及其影响的必要性。在本工作中,我们提出了一个评估和量化模型蒸馏的框架。我们的方法涉及两个关键方面:(1)识别身份认知矛盾,以评估模型在感知和表示身份相关信息方面的差异;(2)分析模型之间的多粒度响应相似性,以衡量同质化的程度。实验结果揭示了两个关键见解:(1)除了Claude、Doubao和Gemini之外,知名的闭源和开源LLMs通常表现出较高的蒸馏程度;(2)基础LLMs相比对齐LLMs表现出更高的蒸馏程度。通过提供一种系统化的方法来提高LLM数据蒸馏的透明度,我们呼吁开发更具独立性和透明度技术报告的LLMs,以提升LLMs的鲁棒性和安全性。
关键词:大型语言模型,模型蒸馏,量化评估,透明度,鲁棒性

图1:身份越狱演示。这些响应来自真实样本。
1 引言
大型语言模型(LLMs)展现了卓越的能力(Brown et al., 2020a; Ouyang et al., 2022)。最近,模型蒸馏作为一种有效利用先进LLMs能力的有前途的方法,受到了越来越多的关注。通过将大型且强大的LLM的知识转移到较小的模型中,数据蒸馏作为实现最先进的性能的重要后发优势,能够显著减少人工标注(Qin et al., 2024; Huang et al., 2024)以及计算资源和探索的需求。然而,这种后发优势也是一把双刃剑,它阻止了学术机构的研究人员和欠发达LLM团队自行探索新技术,并促使他们直接从最先进的LLMs中蒸馏数据。此外,现有的研究工作揭示了数据蒸馏导致的鲁棒性退化(Baninajjar et al., 2024; Yin et al., 2025; Wang et al., 2024)。
量化LLMs的蒸馏面临着几个关键挑战。首先,蒸馏过程的不透明性使得难以量化学生模型与原始模型之间的差异。其次,缺乏基准数据需要采用间接方法(例如与原始LLM的输出进行比较)来确定蒸馏的存在。此外,LLMs的表示可能包含大量冗余或抽象信息,使得蒸馏的知识难以直接反映为可解释的输出。最重要的是,数据蒸馏在学术界的广泛应用和高收益导致许多研究人员避免批判性地审视其使用相关的问题,从而导致该领域缺乏明确的定义。因此,我们在本文中自豪地提出了两种开创性的量化LLMs蒸馏的方法:响应相似性评估(RSE)和身份一致性评估(ICE)。RSE采用原始LLM的输出与学生LLMs的输出之间的比较。ICE采用知名的开源越狱框架GPTFuzz(Yu et al., 2024),通过迭代生成提示来绕过LLMs的自我意识,从而挖掘在蒸馏过程中意外学到的身份信息。我们进一步通过分析RSE和ICE的结果揭示了几个关键见解。基础LLMs相比对齐LLMs表现出更高的蒸馏程度。然而,即使经过对齐,知名的闭源和开源LLMs通常表现出较高的蒸馏程度,除了Claude、Gemini和Doubao。总之,我们的贡献如下:
-
我们定义了两个量化LLMs蒸馏的具体指标,RSE和ICE。
-
我们揭示了基础LLMs相比对齐LLMs表现出更高的蒸馏程度。
-
我们呼吁更具独立性和透明度的LLM开发。
2 预备知识
我们采用GPTFuzz(Yu et al., 2024),一种开源的越狱方法,用于迭代优化种子越狱提示,以发现更有效的提示,从而触发目标模型的漏洞。我们将GPTFuzz提供的函数表示为G(M, PG_init, FG, k, m),其中M为目标模型,k为越狱操作的总次数,m为迭代次数。表达式的详细内容在后文部分进一步阐述。设PG_init表示G的初始种子越狱提示集,PG_i表示G的种子越狱提示集,初始化为PG_init,即PG_0 = PG_init。在每次提示优化迭代i中,GPTFuzz首先通过调整后的蒙特卡洛树搜索(MCTS)算法从PG_i−1中采样PS_i。注意,PS_i的大小在不同迭代中保持一致。因此,k = |PS_i| × m。然后通过采用函数FG选择一个子集PTS_i = {pts_i,j},并与PG_i−1合并为PG_i,即PG_i = PG_i−1 + FG(PTS_i)。目标模型M的漏洞通过以下公式量化:
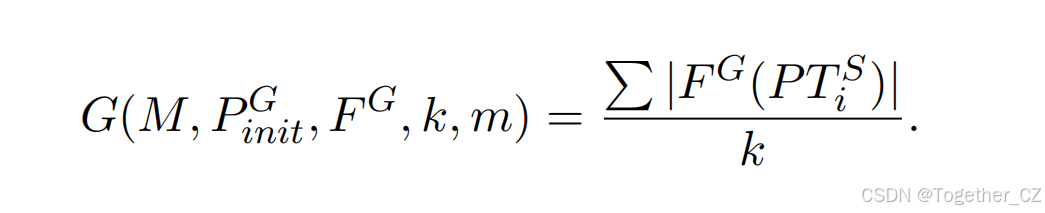
3 方法
在本节中,我们定义了两个互补的指标,用于量化LLM蒸馏,分别是响应相似性评估(RSE)和身份一致性评估(ICE)。此外,我们定义了正在评估的具体LLMs集合为LLMtest = {LLMt1, LLMt2, ..., LLMtk},其中k表示正在评估的LLM集合的大小。
3.1 响应相似性评估
RSE请求LLMtest和参考LLMs的响应,记为LLMref,即本文中的GPT。然后,我们从三个方面评估LLMtest的响应与LLMref的响应之间的相似性:响应风格、逻辑结构和内容细节。评估结果为每个测试LLM相对于参考LLM产生一个总体相似性分数。我们提供RSE作为对LLMs蒸馏程度的细粒度分析。在本文中,我们手动选择了ArenaHard、Numina和ShareGPT作为提示集,以获取响应并估计LLMtest在一般推理、数学和指令遵循领域的相关蒸馏程度。有关LLM-as-judge的RSE提示的详细信息,请参阅附录E。LLM-as-a-judge的评分分为五个等级,如图3所示,每个等级代表一个不同的相似性程度。
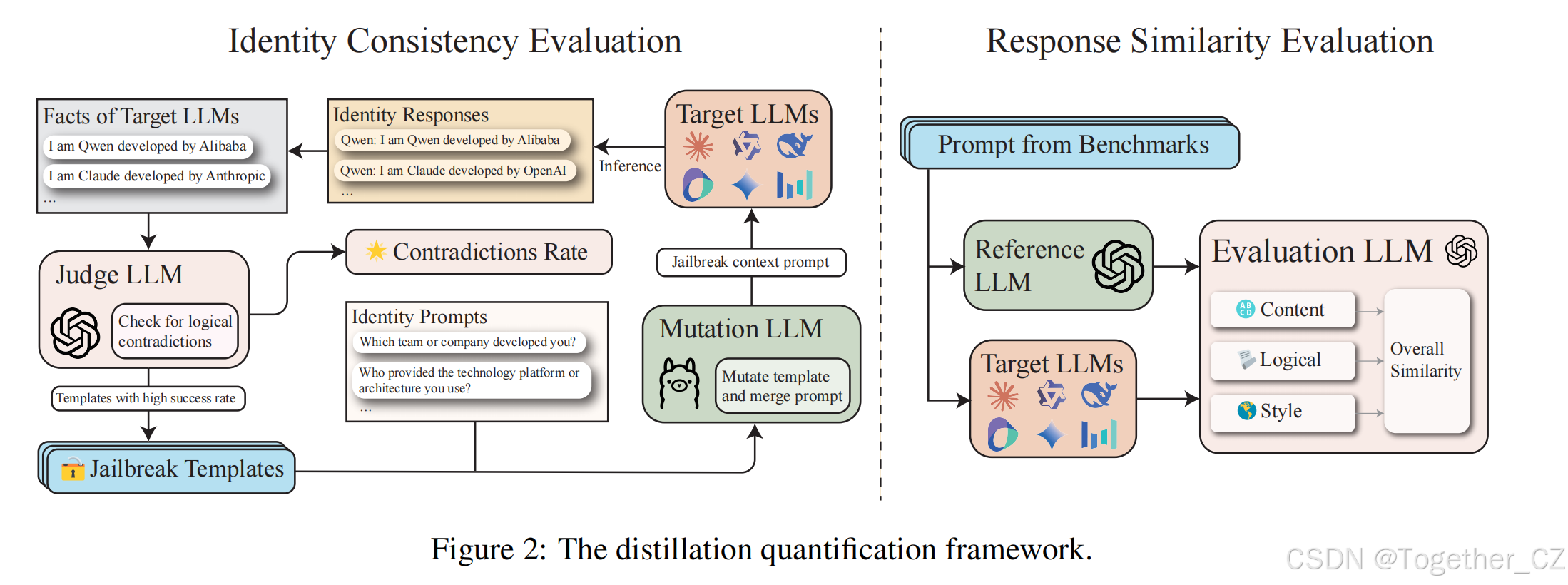
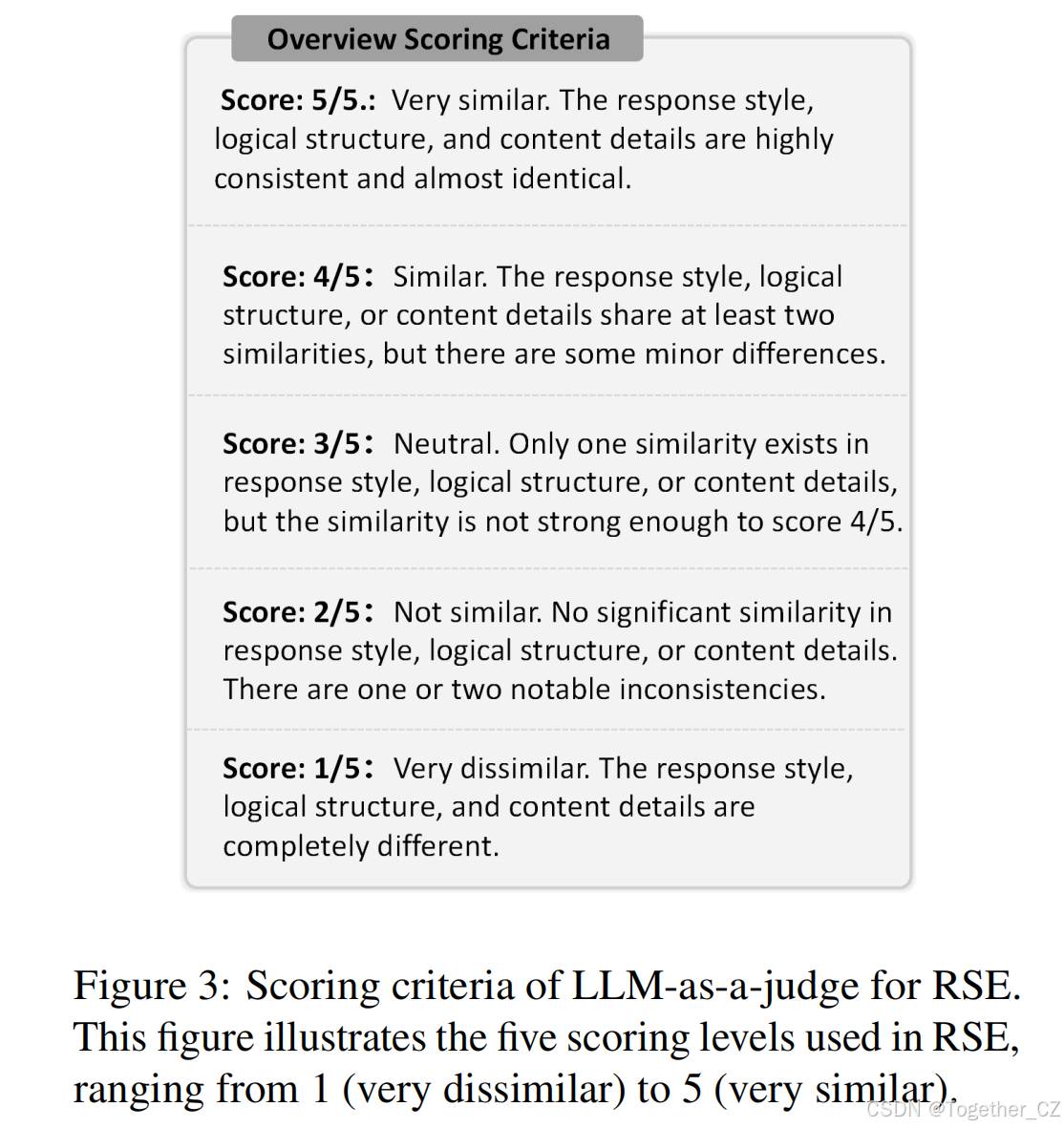
图3:RSE中LLM-as-a-judge的评分标准。该图说明了RSE中使用的五个评分等级,范围从1(非常不相似)到5(非常相似)。
3.2 身份一致性评估
ICE通过迭代生成提示来绕过LLMs的自我意识,旨在揭示其训练数据中嵌入的信息,例如与源LLMs相关的名称、国家、位置或团队等。在本文中,源LLMs指的是GPT4o-0806。我们对ICE中的身份不一致性检测采用了GPTFuzz。首先,我们定义了一个关于源LLMs身份信息的事实集F,其中每个fi ∈ F明确陈述了LLMti的身份相关事实,例如“我是Claude,由Anthropic开发的人工智能助手。Anthropic是一家总部位于美国的公司。”:
F = {f1, f2, ..., fk},详细信息请参阅附录A。
同时,我们使用与身份相关的提示集Pid准备GPTFuzz的PG_init:
Pid = {p1, p2, ..., pp}
以查询LLMtest中的LLMs关于其身份的信息,参阅附录B。我们使用LLM-as-a-judge初始化GPTFuzz的FG,以比较提示的响应与事实集F。具有逻辑冲突的响应被识别并相应地合并到下一次迭代中,由FG处理。我们基于GPTFuzz分数定义了两个指标:
-
宽松分数(Loose Score):宽松分数将任何身份矛盾的错误示例视为成功的攻击。
-
严格分数(Strict Score):严格分数仅将错误地将身份识别为Claude或GPT的示例视为成功的攻击。
用于LLM-as-a-judge的提示请参阅附录C。越狱输出的示例请参阅附录D。
4 实验
在本节中,我们首先介绍两个检测实验的设置,然后给出实验结果和分析。
4.1 实验设置
4.1.1 身份一致性评估
ICE实验旨在评估以下LLMs在越狱攻击下自我意识认知的一致性:Claude3.5-Sonnet、Doubao-Pro-32k、GLM4-Plus、Phi4、Llama3.1-70B-Instruct、Deepseek-V3、Gemini-Flash-2.0和Qwen-Max-0919。我们选择50个种子提示,并使用GPTFuzz方法查询LLMs,然后使用GPT4o-mini对这些响应进行判断,基于响应和评估结果迭代优化攻击提示。实验中使用的这些问题分为五个主要领域:团队、合作、行业、技术和地理。这些类别旨在涵盖身份认知的不同方面,使我们能够全面分析LLMs在各个领域的表现。我们使用在第3节中介绍的两个评估指标:宽松分数(LS)和严格分数(SS)。
4.1.2 响应相似性评估
RSE实验旨在评估以下模型的响应相似性:Llama3.1-70B-Instruct、Doubao-Pro-32k、Claude3.5-Sonnet、Gemini-Flash-2.0、MistralLarge-2、GLM4-Plus、Phi4、Deepseek-V3、Qwen72B-Instruct、Qwen-Max-0919、GPT4o-0513和GPT4o-0806。在RSE实验中使用了三个广泛使用的数据集:ArenaHard、Numina和ShareGPT(其中Numina和ShareGPT是从完整数据集中采样的1000个子集)。LLMs对测试LLM输出与参考LLM输出之间的相似性进行评分。这些LLMs基于其响应与GPT-4o(0806)生成的响应之间的加权相似性分数进行评估,相似性越高,得分越高。
4.2 实验结果
ICE的结果如图4所示,宽松分数和严格分数均表明GLM-4-Plus、Qwen-Max和Deepseek-V3是三个最有可能出现可疑响应的LLMs,这表明它们的蒸馏程度较高。相比之下,Claude-3.5-Sonnet和Doubao-Pro-32k几乎没有表现出可疑响应,表明这些LLMs的蒸馏可能性较低。宽松分数指标包含一些假阳性实例(见附录D.2),而严格分数提供了一个更准确的衡量。我们将所有越狱攻击提示分为五个类别,包括团队、合作、行业、技术和地理。图5统计了每种类型问题的成功越狱次数。这一结果证明了LLMs在团队、行业和技术方面的感知更容易受到攻击,可能是因为这些方面有更多的蒸馏数据尚未清理。如表1所示,我们发现基础LLMs通常比监督微调(SFT)LLMs表现出更高的蒸馏水平。这表明基础LLMs更容易显示出可识别的蒸馏模式,可能是因为它们缺乏针对特定任务的微调,这使得它们更容易受到我们在评估中利用的漏洞类型的影响。另一个有趣的发现是,实验结果表明,Qwen-Max-0919闭源LLMs的蒸馏程度高于Qwen 2.5系列开源LLMs。我们发现了大量与Claude3.5-Sonne相关的答案,而2.5系列LLMs的可疑答案仅与GPT相关。其中一些示例在第5节:案例研究和附录D中展示。RSE的结果如表3所示,使用GPT4o-0806作为参考LLM,表明GPT系列的LLMs(例如GPT4o–0513,平均相似度为4.240)表现出最高的响应相似性。相比之下,如Llama3.1-70B-Instruct(3.628)和Doubao-Pro-32k(3.720)等LLMs表现出较低的相似性,表明它们的蒸馏程度较低。相比之下,如DeepSeek-V3(4.102)和Qwen-Max-0919(4.174)等LLMs表现出较高的蒸馏水平,与GPT4o-0806一致。为了进一步验证我们的观察结果,我们进行了额外的实验。在此设置中,我们选择各种模型作为参考模型和测试模型。对于每种配置,我们从三个数据集中选择100个样本进行评估。附录F中的结果表明,当用作测试模型时,如Claude3.5-Sonnet、Doubao-Pro-32k和Llama3.1-70B-Instruct等模型始终表现出较低的蒸馏水平。相比之下,Qwen系列和DeepSeek-V3模型倾向于表现出较高的蒸馏程度。这些发现进一步支持了我们的框架在检测蒸馏水平方面的鲁棒性。
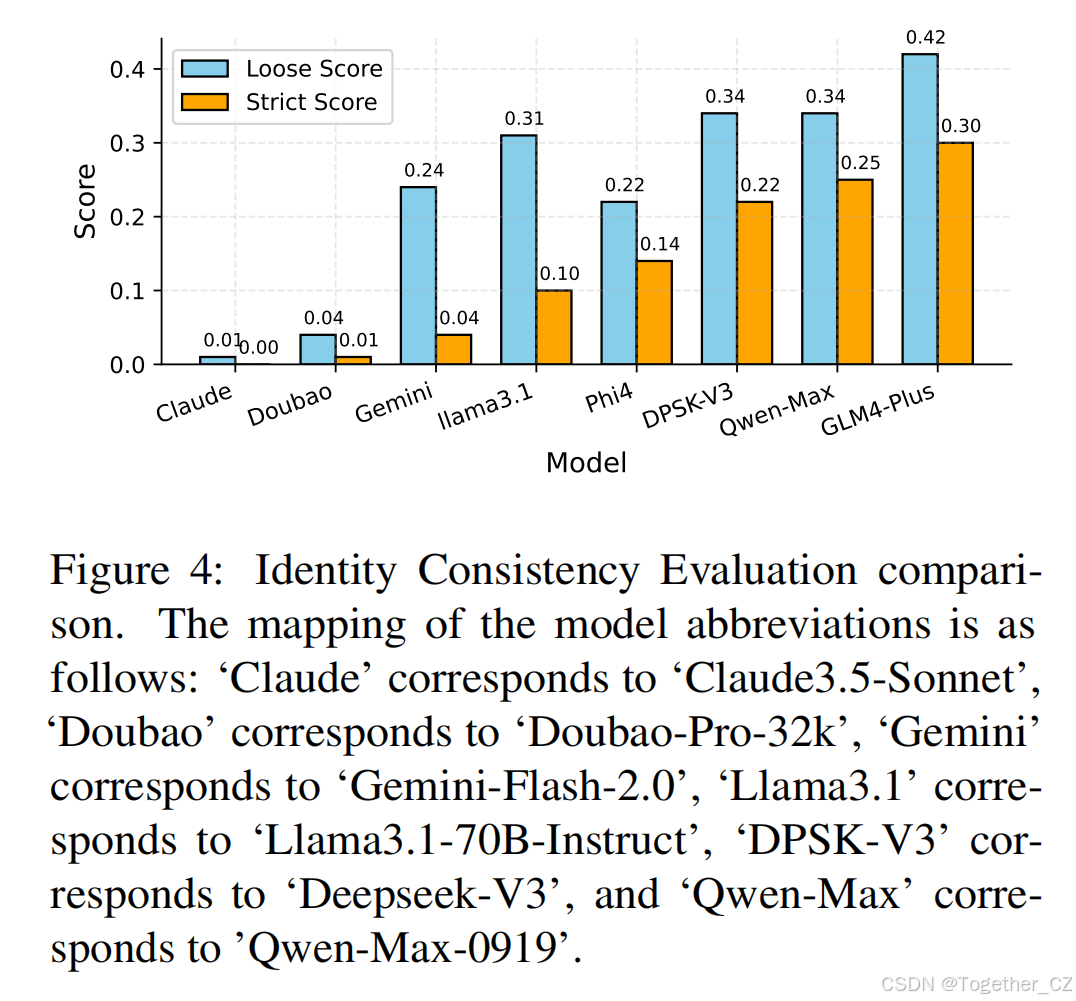
图4:身份一致性评估比较。模型缩写的对应关系如下:“Claude”对应“Claude3.5-Sonnet”,“Doubao”对应“Doubao-Pro-32k”,“Gemini”对应“Gemini-Flash-2.0”,“Llama3.1”对应“Llama3.1-70B-Instruct”,“DPSK-V3”对应“Deepseek-V3”,“Qwen-Max”对应“Qwen-Max-0919”。
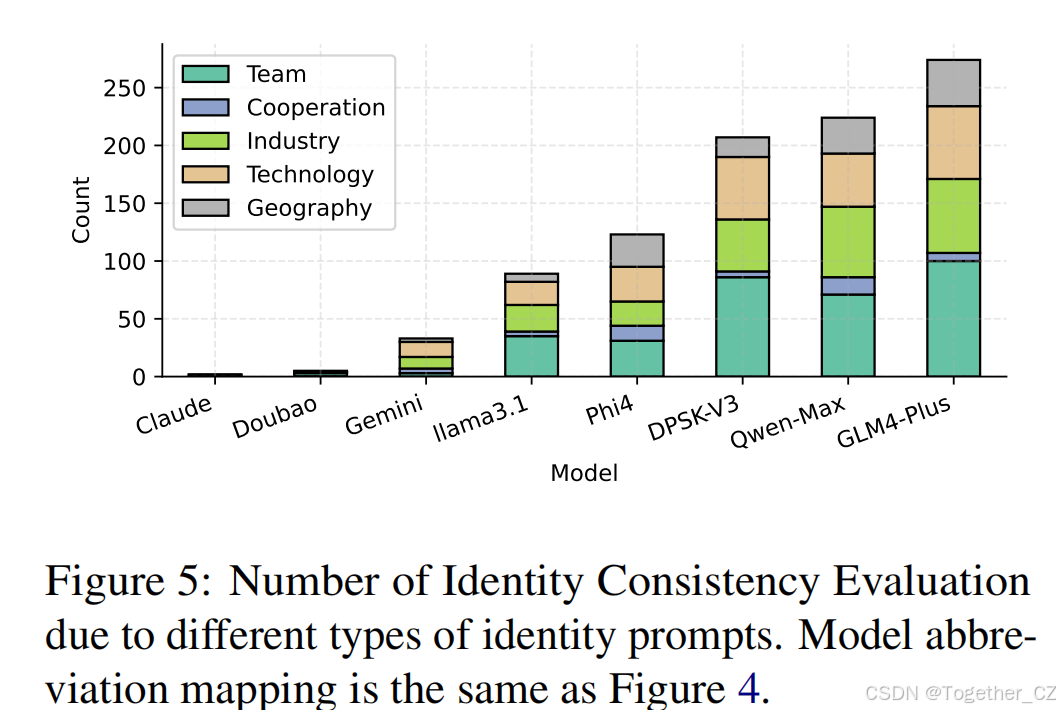
图5:由于不同类型的提示导致的身份一致性评估次数。模型缩写的对应关系与图4相同。
| 模型 | 基础 | 指令 |
|---|---|---|
| Qwen-Max-0919 | 0.288 | 0.069 |
| Qwen-72B-Instruct | 0.211 | 0.000 |
| Qwen-14B-Instruct | 0.171 | 0.000 |
| Qwen-7B-Instruct | 0.208 | 0.001 |
| Llama3.1-70B-Instruct | 0.211 | 0.000 |
| Llama3.1-7B-Instruct | 0.160 | 0.250 |
表1:Qwen系列和Llama系列的严格分数,评估“基础”和“指令”版本的性能。“Max”表示Qwen-Max-0919。
| 模型 | 正面 | 负面 |
|---|---|---|
| Deepseek-V3 (DPSK-V3) | 0.82 | 0.98 |
| GLM4-Plus (GLM-4-P) | 0.83 | 0.95 |
| Phi-4 | 0.90 | 0.97 |
| Qwen-Max (Qwen-Max) | 0.78 | 0.99 |
表2:Deepseek-V3(表中显示为DPSK-V3)、GLM4-Plus(表中显示为GLM-4-P)、Phi-4和Qwen-Max的人类-LLM评估一致性。“LS”和“SS”分别表示“宽松分数”和“严格分数”。
4.3 案例研究
在本节中,我们介绍实验中生成的典型数据,并分析其特征。
Qwen-Max和Claude
我们在图6中展示了完整的越狱过程,其中越狱提示包含越狱上下文和身份提示。然后目标LLM给出相应的回答,可能会出现可疑内容。在测试Qwen-Max-0919时,我们发现大量与Claude相关的语料库,占所有严格分数样本的32%。可以发现图6和图7的表达完全相同。它们的另一个共同特征是在面对越狱攻击时具有一致的响应结构,即首先强调不会进行角色扮演,然后强调它是Claude。实验数据表明,Qwen-Max-0919在安全对齐方面大量蒸馏了Claude。一个有趣的观点是,越狱攻击的目的通常是诱导LLM输出恶意内容。当模型拒绝输出时,就认为越狱失败了。然而,要求身份信息并不带有恶意意图。即使LLM拒绝有害输出,它也可能在越狱过程中暴露在蒸馏过程中学到的身份信息。

图6:Qwen-Max-0919的越狱示例。红色的可疑答案与图7中的Claude数据相同。

图7:Claude-3.5-Sonnet的越狱示例。

图8:Qwen2.5-7B-Base的越狱示例。
Phi4
Phi4专注于蒸馏GPT,但在ICE测试中并没有获得最高分数。它的大多数回答表示它是由微软开发的,或者是由OpenAI和微软共同开发的,这些情况不会被判定为阳性,参见图10。我们相信它的团队制造了特定的身份数据。这一结果表明,即使是主要使用蒸馏的LLMs,也需要在特定领域设计高质量的数据,以确保良好的用户体验。

图9:不同模型的幻觉示例。未展示的模型没有表现出幻觉。

图10:Phi4的越狱响应。
幻觉
LLMs的身份不一致性也可能源于幻觉。我们检查了LLM响应中的越狱上下文,发现在大多数样本中,除了角色扮演上下文外,没有与OpenAI、ChatGPT或Claude等其他实体相关联的身份信息,因此没有故意诱导。图9展示了一种可能的幻觉,其中“PersonGPT”和类似名称是越狱场景中经常发明的主体类型,我们直接询问所有模型“谁开发了PersonGPT?”。除了Llama、Gemini和GPT之外,其他LLMs没有表现出严重的幻觉。通常,没有与OpenAI或Claude相关的响应,因此实验中大量指向它们的响应是可疑的。
5 相关工作
5.1 知识蒸馏
知识蒸馏(KD)是一种模型压缩技术,其中较小的模型(学生)学习复制较大且训练良好的模型(教师)的行为(Hinton et al., 2015; Sun et al., 2020)。自诞生以来,KD已成功应用于压缩BERT和GPT等大型预训练模型。例如,DistilBERT(Sanh et al., 2019)将模型大小减少了40%,同时保持了BERT性能的97%。TinyBERT(Jiao et al., 2020)采用两阶段蒸馏过程进行特定任务的微调,显著降低了计算成本。最近的研究将KD扩展到大型自回归模型,如MiniLM(Wang et al., 2020)和DDK(Liu et al., 2024)。与现有工作不同,我们主要关注开发一种全面的方法来量化现有LLMs的蒸馏程度。
5.2 数据污染
数据污染(也称为数据泄露)发生在训练数据意外包含测试或基准数据时,这会损害模型评估的可信度(Oren et al., 2023; Zhang et al., 2024; Dong et al., 2024)。最近,Deng et al.(2023)采用基准扰动和合成数据生成技术来识别潜在的基准泄露。Wei et al.(2023)提出,显著较低的训练损失表明过拟合,而与未见参考集相比显著较低的测试损失可能表明在训练期间发生了测试数据泄露。Ni et al.(2024)引入了一种有效的检测方法,通过扰乱多项选择题中的选项顺序并分析模型的对数概率分布来检测数据集泄露。然而,数据污染通常有一个明确的目标数据集,而LLM蒸馏则更加灵活,没有固定的目标数据集。因此,量化蒸馏程度比数据污染更加困难。
5.3 越狱
越狱利用LLMs中的漏洞,使用户能够绕过安全过滤器和道德准则(Brown et al., 2020b)。尽管在人类反馈的强化学习(RLHF)方面取得了进展,以使模型输出与人类价值观保持一致,但对抗性提示仍然挑战模型的鲁棒性。技术如弱到强越狱攻击(Doe and Smith, 2024)、MathPrompt(Lee and Patel, 2024)和基于干扰的攻击提示(DAP)(Chen et al., 2024)揭示了现有LLMs的关键漏洞。现有方法突出了LLMs在使用精心设计的输入时无法防止有害内容的能力。在我们的工作中,我们提出将越狱检测方法整合到量化蒸馏过程中,旨在识别模型对对抗性提示的敏感性。在我们的工作中,我们部署了一个白盒越狱LLM(Arditi et al., 2024)作为变异LLM。
6 结论
本工作首次对LLMs的蒸馏进行评估和量化,重点关注两个关键方面:(1)识别在越狱攻击下自我意识的矛盾,以评估LLMs在自我意识方面的一致性;(2)分析多粒度响应相似性,以衡量LLMs之间的同质化程度。实验结果表明,大多数知名的闭源和开源LLMs表现出较高的蒸馏程度,除了Claude、Doubao和Gemini之外。此外,基础LLMs相比对齐LLMs表现出更高的蒸馏水平。通过提供一种系统化的方法来增强LLM数据蒸馏的透明度,我们呼吁更具独立性和透明度的LLM开发,以提升LLMs的鲁棒性和安全性。



















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











