







简介
空间中的信号经过采样量化编码后变成形如0101的比特流,然后在微处理器中进行进一步的信源编码以及信道编码后,仍然是形如0101的比特流。这时候通信系统为了发送和接收信息,会进行数字基带调制(Digital Modulation)和模拟调制(Analogue Modulation),前者在一定程度上更高效地利用了频谱资源,提升了码率,而后者使信号更加舒服地在信道(介质Medium)中传输。然而,在传输的过程中,由于加性高斯白噪声(AWGN:Additive White Gaussian Noise)以及衰落信道的影响,接收机有时候会做出“误判”的决定,也就是有时候明明发的是0,接收端却以为是1。而不同的调制技术,其出错的概率是不一样的。本篇文章将讲解分析各种调制技术的误码率(SER: Symbol Error Rate)和误比特率(BER: Bit Error Rate)的基本方法。
目录
1.1 功率谱密度(Power Spectrum Density)
1.1.1 自相关函数(Autocorrelation Function)
1.2 信噪比(SNR:Signal To Noise Ratio)和Eb/N0
1.3.1 条件概率(Conditional Probability)
2.5.1 最大后验概率准则(MAP: Maximum a Prosterior Criterion)
一、前置知识
由于从这一块起,我们会需要很多前置知识,比如功率谱密度,匹配滤波器,最大后验概率准则等,所以我们先对这些知识进行讲解。如若需要更加深入且完整的了解,可以看李晓峰教授的 通信原理 以及 随机信号分析 。
1.1 功率谱密度(Power Spectrum Density)
这一小节的知识主要会用于匹配滤波器的推导以及后续的最佳接收机的BER Performance 分析
1.1.1 自相关函数(Autocorrelation Function)
信号 的 自相关函数
是表示
在任意两个时刻 t1,t2 上取值,这两个取值之间的关联程度,其计算式为:(两种意思一样)
1.1.2 平稳信号(Stationary Signal)
平稳信号的简单理解就是,统计特性不随时间变化的信号。所以有如下两个性质:
1. 均值和时间无关,是一个常数:
, m为任意常数
2. 自相关函数与两时间参量的绝对位置无关,即:
1.1.3 平稳信号的功率谱密度
我们通常更关注平稳信号的功率谱密度, 而根据维纳-辛钦定理(Wiener-Khintchine),平稳随机信号的功率谱密度 是其自相关函数
的傅里叶变换:
而功率谱密度代表以下重要的两点:
1.
沿着数字角频率
轴的“总和”是信号的平均功率
2. 如果在某个数字角频率
的
比较大,这说明该信号中含有较多的
1.1.4 高斯白噪声的定义
前面的铺垫都是为了AWGN的定义,首先,AWGN是平稳的,它是及其理想的,代表着信号“随机性”的一种极限。有如下性质:
1. AWGN的自相关函数恒有:
2. AWGN的功率谱密度有:
它们分别长这样:
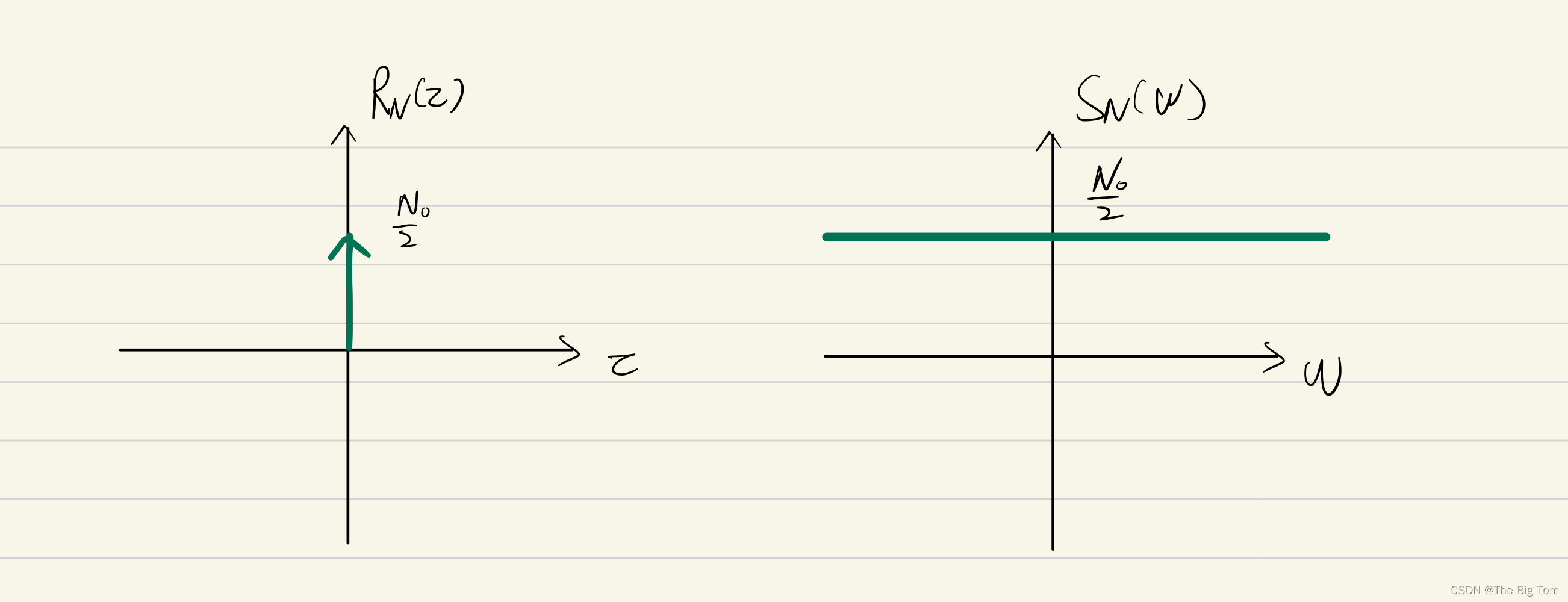
可见,高斯白噪声的功率谱密度是恒定值的。这也就意味着,高斯白噪声在各个频率的噪声分量都是一样的。而又因为它是无限长的,那么它沿着数字角频率轴的“总和”就会是无限大,所以其高斯分布的平均功率即方差无限大(后面解释),所以无法写出其概率分布函数。
那么为啥其平均功率等于方差呢?下面给出证明。

但是经常实验的时候会叫你算出噪声功率,再用代码生成高斯白噪声啊,那功率无限大我算个锤子?
其实是这样的,我们在实际处理的时候,一方面,一个信号不可能有所有频率的分量,所以我们只需要进行一段区间的积分得到平均功率,比如信号经过LPF(Low Pass Filter),另一方面,我们通常处理离散序列,而高斯白噪声的平稳序列也恒有下面关系:
1. 自相关函数恒有
2. 其自相关函数的DTFT也即功率谱密度恒有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4413
4413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









