






11.1激活函数
激活函数(Activation Function)就是对神经网络中某一部分神经元的非线性运算,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。激活函数一般要求可微,且不会改变输入数据的维度。
在Tensorflow中常用的激活函数包括:
tf.sigmoid(features,name=None)
tf.tanh(features,name=None)
tf.nn.relu(features,name=None)
tf.nn.softplus(features,name=None)
tf.nn.dropout(x,keep_prob,noise_shape=None,seed=None,name=None)等
输入为张量,返回值也是张量。
11.1.1 sigmoid函数
sigmoid函数是传统神经网络常用的一种激活函数,如图所示,优点在于输出映射在(0,1)内,单调连续,适合用作输出层,求导容易;缺点是具有软饱和性,一旦输入数据落入饱和区,一阶导数变得接近为0,就可能产生梯度消失问题。

11.1.2 tanh函数
tanh 激活函数同样具有软饱和性,输出以0为中心,收敛速度比sigmoid快,但是也存在梯度消失问题,如图所示。

11.1.3 relu函数
relu函数是目前最受欢迎的激活函数,在x<0时,硬饱和,x>0时,导数为1,所以在x>0时保持梯度不衰减,从而可以缓解梯度消失问题,能更快的收敛,并提供神经网络的稀疏表达能力。但随着训练的进行,部分输入会落入硬饱和区,导致对应的权重无法更新,称为“神经元死亡”,如图所示。

下面我们用一个实例来说明如何使用Tensorflow的relu函数。
import tensorflow as tf
sess = tf.InteractiveSession()
#产生一个4×4的矩阵,满足均值为0,标准差为1的正态分布
matrix_input=tf.Variable(tf.random_normal([4,4],mean=0.0,stddev=1.0))
#对变量初始化,这里对a进行初始化
tf.global_variables_initializer().run()
#输出原始矩阵的值
print("原始矩阵:\n",matrix_input.eval())
#对原始矩阵用rulu函数进行激活处理
matrix_output=tf.nn.relu(matrix_input)
#输出处理后的矩阵的值
print("Relu函数激活后的矩阵:\n",matrix_output.eval())

11.1.4 softplus函数
softplus 对 relu 函数做了平滑处理,如图所示。

11.1.5 dropout函数
一个神经元以概率keep_prob决定是否被抑制。如果被抑制,神经元的输出为0;如果被抑制,神经元的输出为0;如果不被抑制,该神经元的输出将被放大到原来的1/keep_prob倍。默认情况下,每个神经元是否被抑制是相互独立的。
dropout激活函数格式为:
tf.nn.dropout(x,keep_prob,noise_shape=None,seed=None,name=None)
激活函数在神经网络起着非常重要的作用,理论上添加激活函数的神经网络可以收敛于任意一个函数。因激活函数各有特色,所以具体使用时,应根据具体情况进行选择,一般规则为:
当输入数据特征相差明显时用,用tanh效果很好。
当特征相差不明显的时候,用sigmoid效果比较好。
sigmoid和tanh作为激活函数需要对输入进行规范化,否则激活后的值全部进入平坦区,而relu不会出现这种情况,有时也不需要输入规范化,因此85%~90%的神经网络会采取relu函数。
11.2 代价函数
代价函数是神经网络模型的效果评估及优化的目标函数,常用于监督学习中关于分类模型和回归模型中的迭代优化。分类问题中常用交叉熵(cross_entropy)算法,本节做详细介绍。
11.2.1 sigmoid_cross_entropy_with_logits函数
在深度学习中,分类问题的代价函数一般采用交叉熵函数。基于sigmoid函数的交叉熵函数一般格式为:
tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None,name=None)
主要参数说明:
_sentinel:本质上是不用的参数,不用填。
logits:神经网络运算分类结果的张量表示,一个数据类型float32或float64
labels:实际标签值的张量表示,和logits具有相关的数据类型和shape[batch_size,num_classes]
注意,此函数支持(多标签)分类,例如判断图片中是否包含5种事物中的一种或几种,标签值可以包含多个1或0个1。
name:操作的名字,可填可不填。
本函数对logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
返回值为一个batch中每个样本的loss,shape为[batch_size,num_classes],所以一般配合tf.reduce_mean(loss)使用。(求整体的的loss平均值)
以下通过一个实例代码说明该函数的具体使用方式:
import tensorflow as tf
import numpy as np
def sigmoid(x):
return 1.0/(1+np.exp(-x))
#定义了一个sigmoid函数,np.exp()为返回一个e的n次方
#定义了一个5个样本3种分类的问题,且每个样本可以属于多种分类
y=np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,1]]) #类别标签
logits=np.array([[10,3.8,2],[8,10.9,1],[1,2,7.4],[4.8,6.5,1.2],[3.3,8.8,1.9]])
#按自定义计算公式计算的结果
y_pred=sigmoid(logits)
output1=-y*np.log(y_pred)-(1-y)*np.log(1-y_pred)
print('Self_Define_output1 : ',output1)
with tf.Session() as sess:
y=np.array(y).astype(np.float64)#labels 是float64类型
#按Tensorflow函数计算结果,与自定义计算公式计算结果相同
output2=sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
print('sigmoid_corss_entropy_with_logits : ',output2)
#调用tf.reduce_mean()运算结果的平均值
reduce_mean=sess.run(tf.reduce_mean(output2))
print('reduce_mean : ',reduce_mean)

证明结果是一样的,这个代码的目的就是展示此代价函数内部运作
11.2.2 softmax_cross_entropy_with_logits 函数
基于softmax函数的交叉熵函数,其格式为:
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None,dim=-1,name=None)
其中,dim为类别维度,默认设置为最后一个类别。其他参数请参考sigmoid_cross_entropy_logits函数
本函数对logits先通过softmax函数计算,在计算它们的交叉熵,也对交叉熵计算方式进行了优化,使得结果不至于溢出。
它适用于每个类别相互独立且排斥的情况,例如判断的图片只能属于一个种类,而不能同时包含多个种类。
返回值为一个batch中每个样本的loss,shape为[batch_size,num_classes],所以一般配合tf.reduce_mea(loss)使用。
11.2.3 sparse_softmax_cross_entropy_with_logits函数
这也基于softmax函数的交叉熵函数,不过多了一个sparse前缀,其一般格式为:
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None,name=None)
该函数与tf.nn.softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None,dim=-1,name=None)十分相似,唯一的区别在于labels,该函数的标签labels要求是排他性的即只有一个正确类别,labels的形状要求是[batch_size]而值必须是从0开始编码的int32或int64,而且值范围是[0,num_class)。其他使用注意事项参见tf.nn.softmax_cross_entropy_with_logits的说明。
代码实例:
import tensorflow as tf
labels=[0,2]
logits=[[2,0.5,1],[0.1,1,3]]
logits_scaled=tf.nn.softmax(logits)
result1=tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels,logits=logits)
with tf.Session() as sess:
print(sess.run(result1))
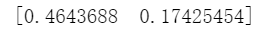
11.2.4 weighted_cross_entropy_with_logits 函数
该代价函数是sigmoid_cross_entropy_with_logits的拓展版,计算方式基本与tf_nn_sigmoid_cross_entropy_with_logits相似,但是加上了权重的功能,是计算具有权重的sigmoid交叉熵函数,其一般格式为:
tf.nn.weighted_cross_entropy_with_logits(targets,logits,pos_weight,name=None)
主要参数说明:
targets:一个和logits具有相同的数据类型(type)和尺寸形状(shape)的张量(tensor)
shape:[batch_size,num_classes],单样本是[num_classes]
logits:一个数据类型(type)是float32或float64的张量
pos_weight:正样本的一个系数
name:操作的名字,可填可不填
其中pos_weight参数,在传统基于sigmoid的交叉熵算法上,正样本算出的值乘以某个系数。
实例代码:
import numpy as np
import tensorflow as tf
input_data=tf.Variable(np.random.rand(3,3),dtype=tf.float32)
#np.random.rand()传入一个shape,返回一个在【0,1】区间符合均匀分布的array
output=tf.nn.weighted_cross_entropy_with_logits(logits=input_data,targets=[[1.0,0.0,0.0],[0.0,0.0,1.0],[0.0,0.0,1.0]],pos_weight=2.0)
with tf.Session() as sess:
init=tf.global_variables_initializer()
sess.run(init)
print(sess.run(output))
















 2151
2151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









