







 本文介绍了如何将Facebook的Llama2模型转换为API服务,使用FastAPI和uvicorn搭建服务器,同时实现了一个类似OpenAI的聊天界面,通过Streamlit集成到一个可交互的对话框中。
本文介绍了如何将Facebook的Llama2模型转换为API服务,使用FastAPI和uvicorn搭建服务器,同时实现了一个类似OpenAI的聊天界面,通过Streamlit集成到一个可交互的对话框中。
最近按照官方例子,把Llama2跑起来了测试通了,但是想封装成api服务,耗费了一些些力气
参考:https://github.com/facebookresearch/llama/pull/147/files
1. 准备的前提如下
- 按照官方如下命令,可以运行成功
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-2-7b-chat/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 6
- 使用的模型是
llama-2-7b-chat
2. 第一步,增加依赖包
fastapi
uvicorn
3. 第二步,增加文件server.py在llama仓库的根目录下
from typing import Tuple
import os
import sys
import argparse
import torch
import time
import json
from pathlib import Path
from typing import List
from pydantic import BaseModel
from fastapi import FastAPI
import uvicorn
import torch.distributed as dist
from fairscale.nn.model_parallel.initialize import initialize_model_parallel
from llama import ModelArgs, Transformer, Tokenizer, Llama
parser = argparse.ArgumentParser()
parser.add_argument('--ckpt_dir', type=str, default='llama-2-7b-chat')
parser.add_argument('--tokenizer_path', type=str, default='tokenizer.model')
parser.add_argument('--max_seq_len', type=int, default=512)
parser.add_argument('--max_batch_size', type=int, default=6)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12345'
os.environ['WORLD_SIZE'] = '1'
app = FastAPI()
def setup_model_parallel() -> Tuple[int, int]:
local_rank = int(os.environ.get("LOCAL_RANK", 0))
world_size = int(os.environ.get("WORLD_SIZE", 1))
print("world_size", world_size)
print("loal_rank", local_rank)
dist.init_process_group(backend="nccl", init_method="env://", world_size=world_size, rank=local_rank)
initialize_model_parallel(world_size)
torch.cuda.set_device(local_rank)
# seed must be the same in all processes
torch.manual_seed(1)
return local_rank, world_size
def load(
ckpt_dir: str,
tokenizer_path: str,
local_rank: int,
world_size: int,
max_seq_len: int,
max_batch_size: int,
) -> Llama:
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
model_parallel_size=1
)
return generator
def init_generator(
ckpt_dir: str,
tokenizer_path: str,
max_seq_len: int = 512,
max_batch_size: int = 8,
):
local_rank, world_size = setup_model_parallel()
if local_rank > 0:
sys.stdout = open(os.devnull, "w")
generator = load(
ckpt_dir, tokenizer_path, local_rank, world_size, max_seq_len, max_batch_size
)
return generator
if __name__ == "__main__":
args = parser.parse_args()
generator = init_generator(
args.ckpt_dir,
args.tokenizer_path,
args.max_seq_len,
args.max_batch_size,
)
class Config(BaseModel):
prompts: List[str]
system_bg: List[str]
max_gen_len: int = 510
temperature: float = 0.6
top_p: float = 0.9
if dist.get_rank() == 0:
@app.post("/llama/")
def generate(config: Config):
dialogs: List[Dialog] = [
[
{
"role": "system",
"content": config.system_bg[0],
},
{
"role": "user",
"content": config.prompts[0],
}
],
]
results = generator.chat_completion(
dialogs, # type: ignore
max_gen_len=config.max_gen_len,
temperature=config.temperature,
top_p=config.top_p,
)
return {"responses": results}
uvicorn.run(app, host="0.0.0.0", port=8042)
else:
while True:
config = [None] * 4
try:
dist.broadcast_object_list(config)
generator.generate(
config[0], max_gen_len=config[1], temperature=config[2], top_p=config[3]
)
except:
pass
4. 运行测试
直接运行python sever.py即可运行成功
提供了一个post接口,具体信息为
URL:http://localhost:8042/llama
Body:
{
"prompts":["你好,你是谁?"],
"system_bg":["你需要用中文回答问题"]
}
其中prompts为输入内容,system_bg为给提前设定的背景
5. 做一个互动的网页
想做一个类似OpenAI那样子的对话框,继续添加依赖
streamlit
添加如下文件chatbot.py
import streamlit as st
import requests
import json
st.title("llama-2-7b-chat Bot")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# React to user input
if prompt := st.chat_input("What is up?"):
# Display user message in chat message container
st.chat_message("user").markdown(prompt)
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
url = 'http://localhost:8042/llama'
d = {"prompts": [prompt], "system_bg": [""]}
print(d)
r_resp_txt = requests.post(url, data=json.dumps(d))
r_resp_dict = json.loads(r_resp_txt.text)
response = r_resp_dict['responses'][0]['generation']['content']
# Display assistant response in chat message container
with st.chat_message("assistant"):
st.markdown(response)
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
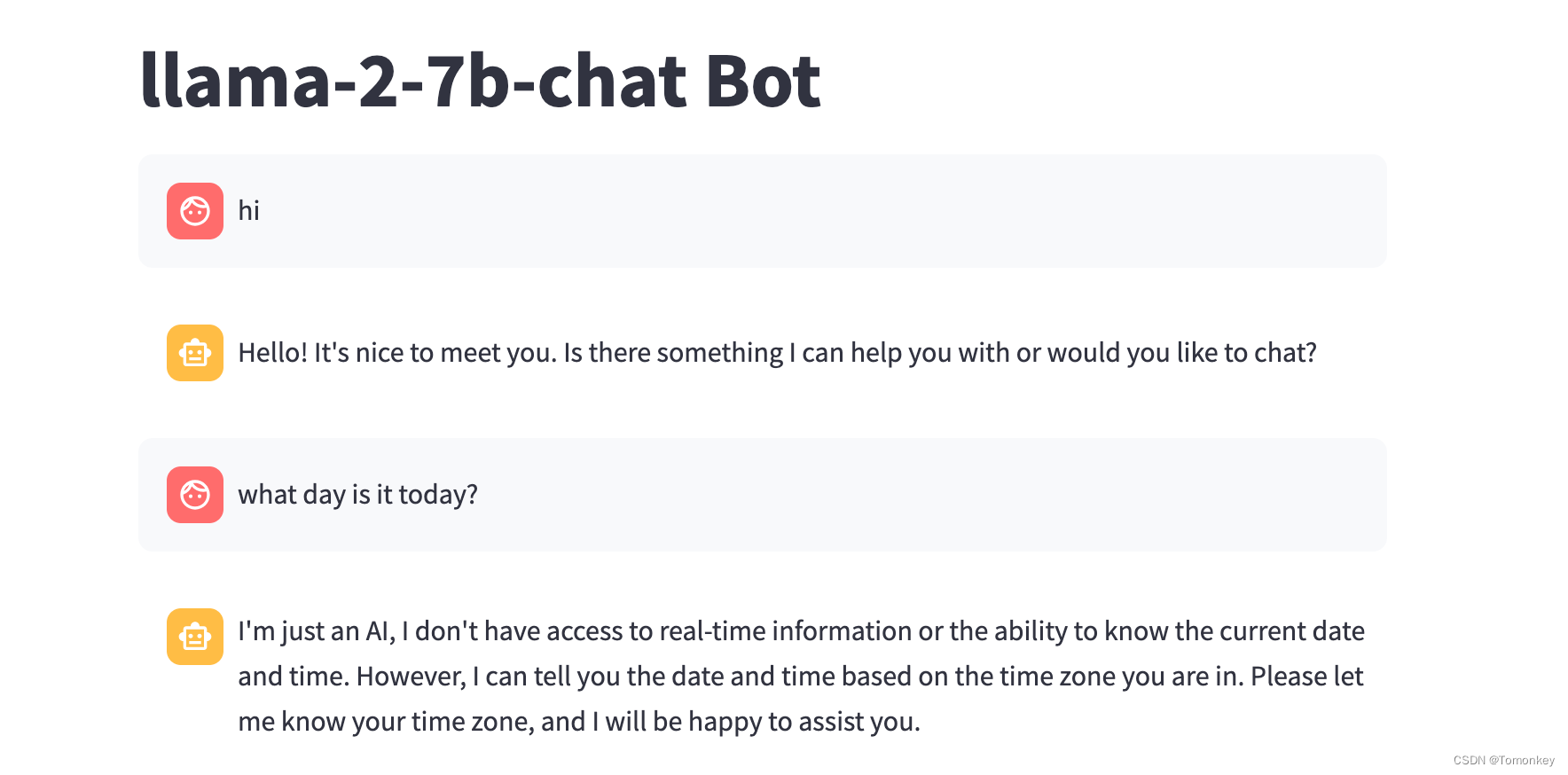
运行streamlit run chatbot.py,即可有如下效果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









