






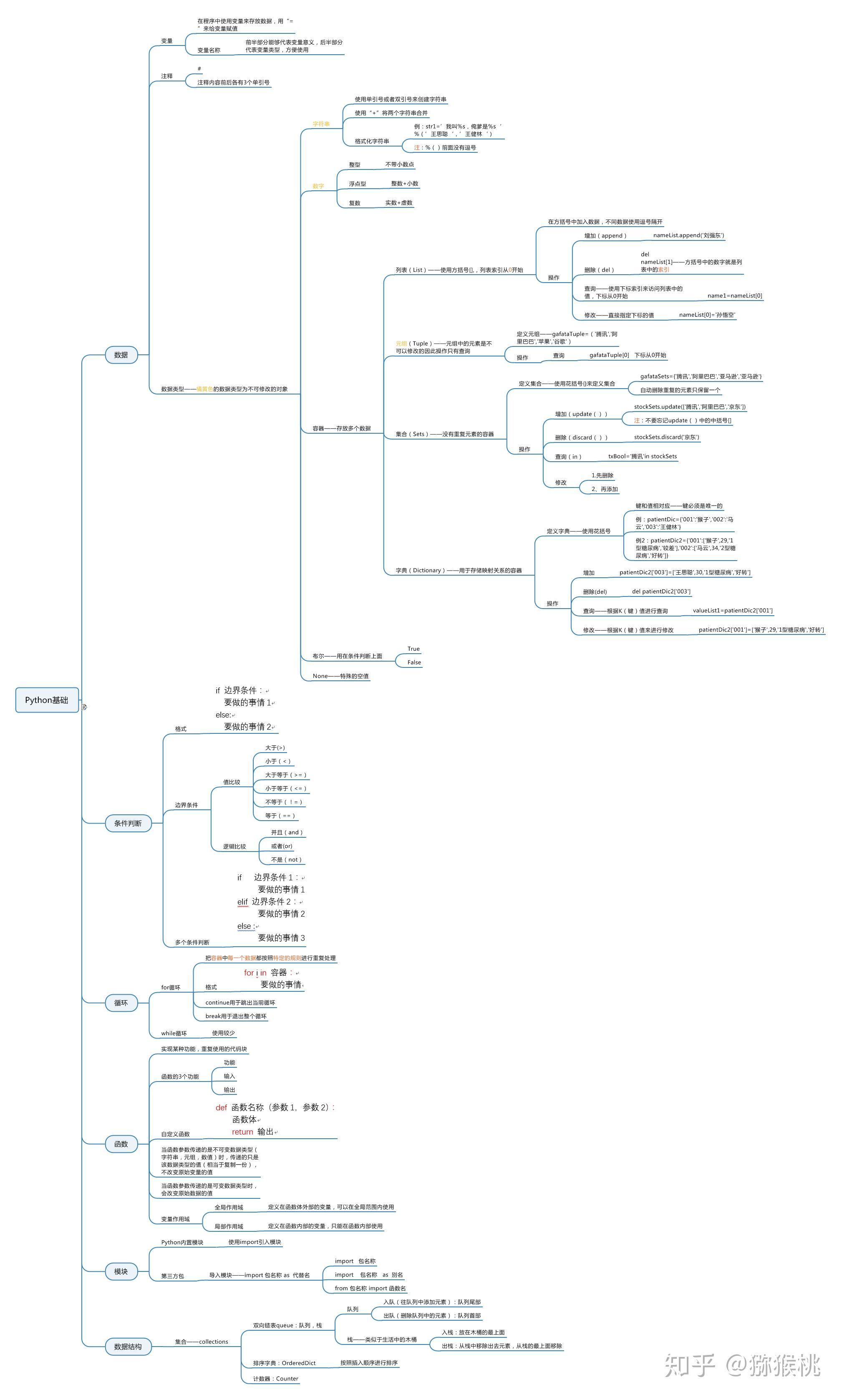
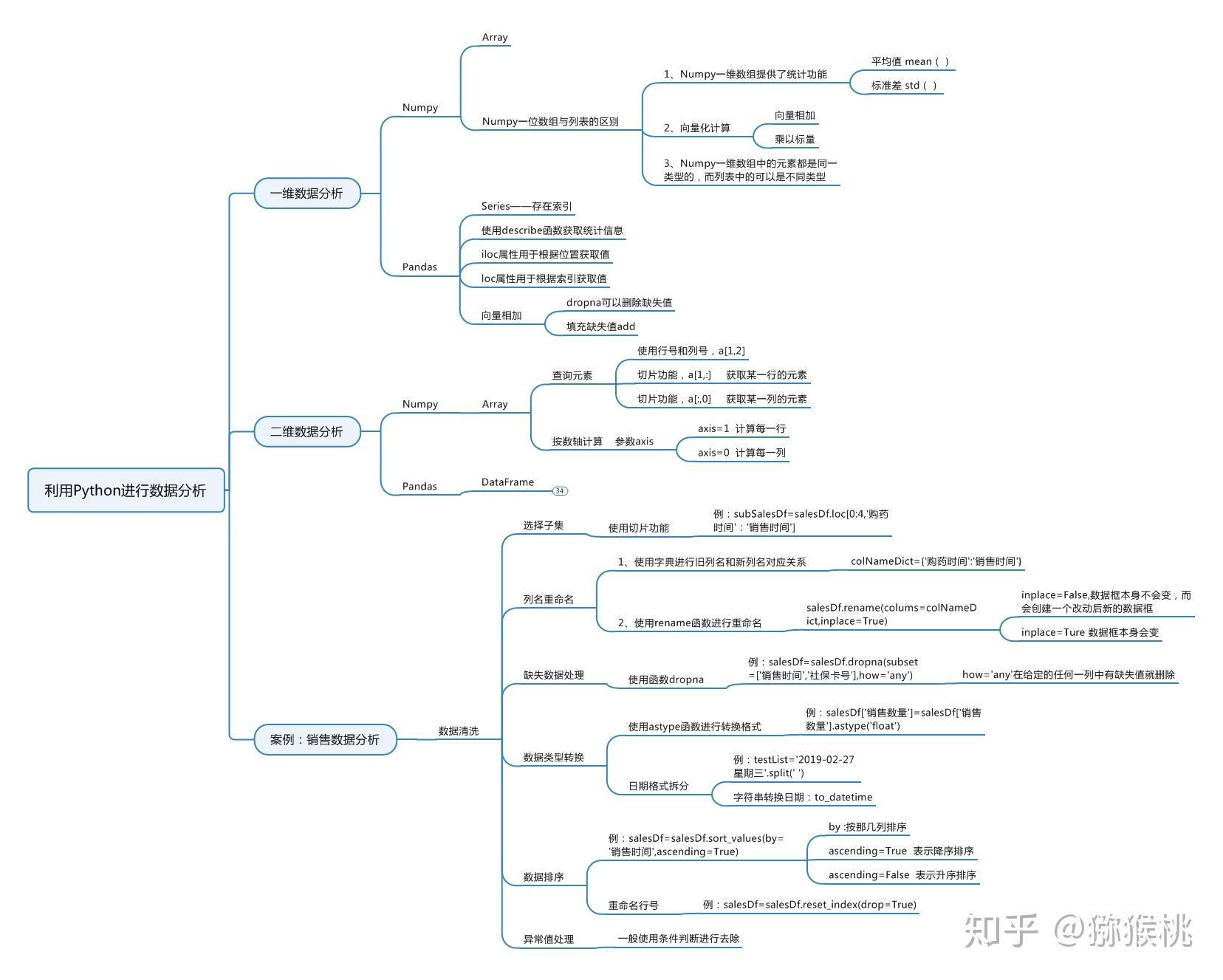
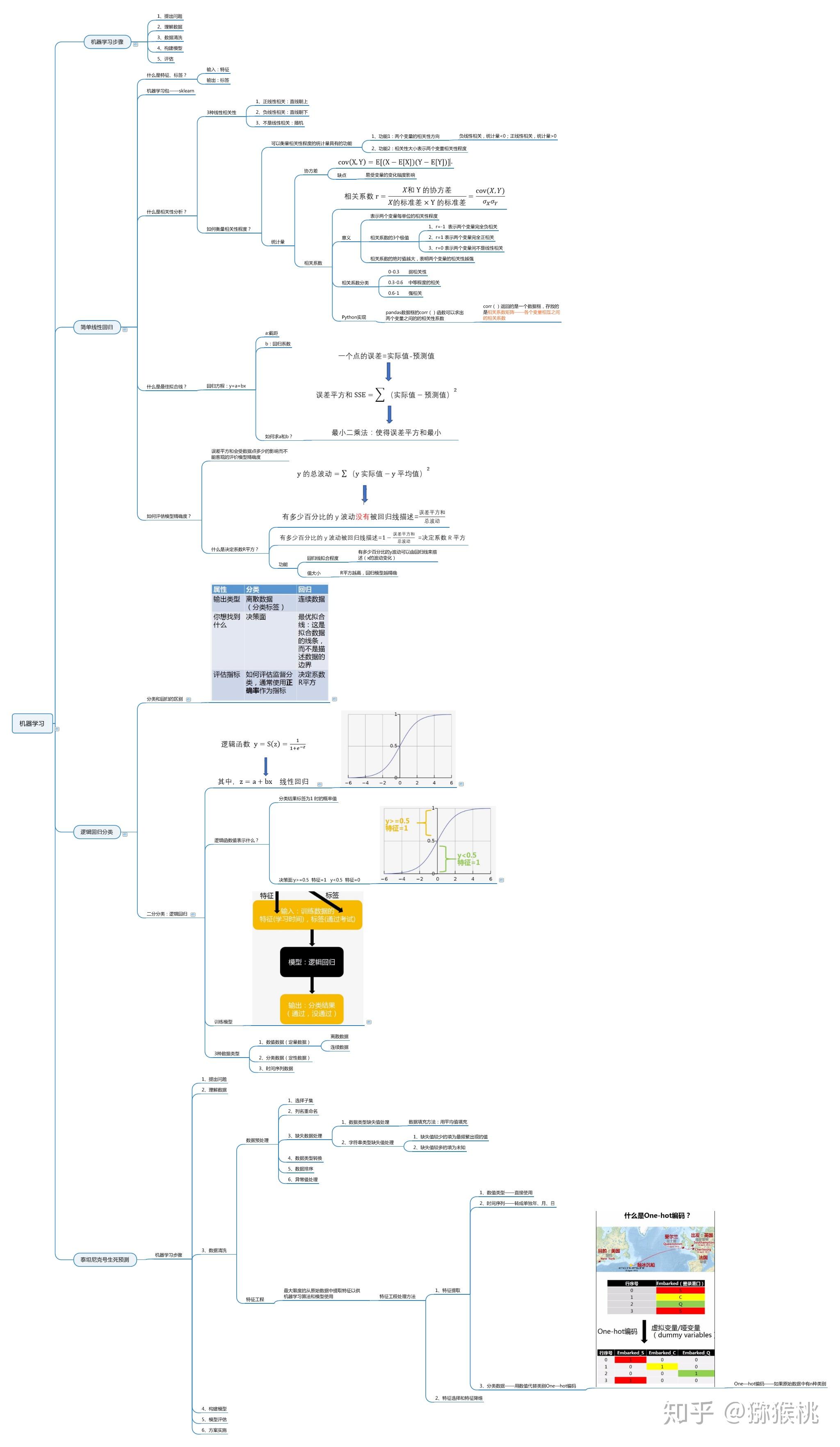
9本人Python小白一枚,为了可以快速的学习的Python,先通过做项目的过程中逐步积累知识,期望能慢慢形成自己的体系,下面是一些做项目之前自己学习的Python的基础知识。
一、知识点1——pd.to_numeric
to_numeric:将参数转换为数值类型。根据提供的数据,默认返回的dtype是float64或int64。使用**downcast参数获取其他dtype**。
参数(arg)可以为:列表(list),元组( tuple),一维数组( 1-d array或者Series)
errors:{‘raise’,‘ignore’,‘coerce’},errors参数包含3种值,
如果errors=‘raise’,则无效的解析将引发异常
如果errors=‘ignore’,则无效的解析将返回输入
如果errors=‘coerce’,则无效的解析将会设置为NAN
例子1:
s = pd.Series(['1.0', '2', -3])
pd.to_numeric(s)

pd.to_numeric(s, downcast='float')

pd.to_numeric(s, downcast='signed')

例子2:
s = pd.Series(['apple', '1.0', '2', -3])
pd.to_numeric(s, errors='ignore')

pd.to_numeric(s, errors='coerce')

二、知识点2——时间转换
to_datetime:
(1)获取指定的时间和日期
pd.to_datetime('2017/01/08',format='%Y/%m/%d')

(2)将时间戳转换为时间格式
#时间戳变为时间
def convertTime(timeColList):
timeList=[]
for value in timeColList:
dateSer=time.localtime(value)
timeList.append(time.strftime('%Y-%m-%d %H:%M:%S',dateSer))
dateSer=pd.Series(timeList)
return dateSer
三、知识点3——pandas文本数据转整数分类编码
数据集中通常包含分类变量,这些变量中通常存储为表示各种特征的文本值。在进行数据分析时,我们需要对分类产量进行特征提取,以便后续建立模型。
1、替换字符串——map函数
查找列中所有的字符串,然后给不同字符串一个编号(映射为数字),然后用编号替换字符串
import pandas as pd
df = pd.DataFrame([
['green', '男', 10.1, 'class1'],
['red', '女', 13.5, 'class2'],
['blue', '女', 15.3, 'class1']])
df.columns = ['color', 'sex', 'prize', 'class label']
'''
对于性别进行映射
'''
sex_mapping = {
'男': 0,
'女': 1}
df['sex'] = df['sex'].map(sex_mapping)
结果:

2、标签编码——astype(‘category’)
标签编码只是将列中的每个值转换为数字。
bs=df['class label'].astype('category')

然后你只需要使用标签的编码作为真正的数据就可以了:
bs.cat.codes.head()

标签编码的优点是它很简单,但它的缺点是数值可能被算法“误解”。
3、转换成哑变量,或者叫one-hot编码——pandas get_dummies()函数
df=pd.get_dummies(要进行转换的列,prefix='列名')
get_dummies的第一个参数为要转换为哑变量的列,第二个参数为要生成的哑变量的名称的前缀。
四、知识点4——列名重命名
1、导入数据无列名时
在导入数据时,添加参数header=None
lianjiaData = pd.read_excel('rlianjia.xlsx')
df = lianjiaData.copy()
display(df.head(5))

#导入数据
lianjiaData = pd.read_excel('rlianjia.xlsx',header=None)
#备份数据
df = lianjiaData.copy()
#列名重命名的第一种方法
df.colunms=['TotalPrice','PerPrice','Floor','Message','Popularity']
display(df.head(5))

2、第1种方法
import pandas as pd
a = pd.DataFrame({'A':[1,2,3], 'B':[4,5,6], 'C':[7,8,9]})
a

a.columns=['a','b','c']
a

3、第2种方法
a.rename(columns={'A':'a', 'B':'b', 'C':'c'}, inplace = True)
a

五、知识点5——删除缺失值
data = data[data['SALE PRICE'].notnull()]
六、知识点6——异常值处理
1、异常值的检测方法
- 简单统计
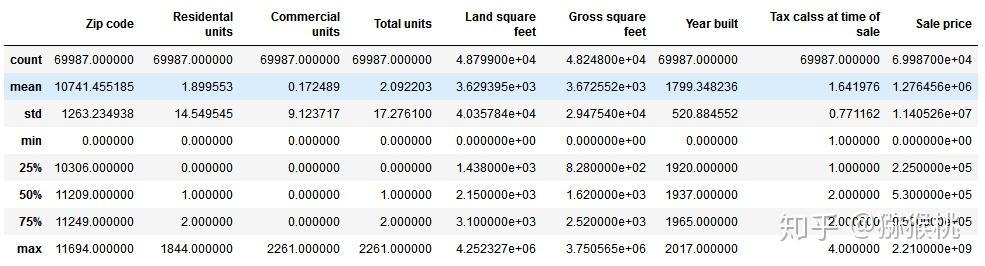
如果使用pandas,我们可以直接使用describe()来观察数据的统计性描述(只是粗略的观察一些统计量),不过统计数据为连续型的,如下:
import pandas as pd
import numpy as np
#导入数据集
nycData=pd.read_csv('F:/nyc-property-sales/nyc-rolling-sales.csv')
#查看数据集
nycData.describe()
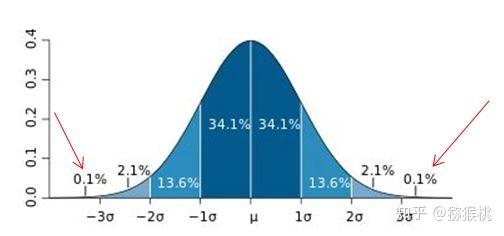
- 3∂原则
使用条件:数据需要服从正态分布。在3∂原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
- 箱型图
利用箱型图的四分位距(IQR)对异常值进行检测,也叫Tukey‘s test。箱型图的定义如下:

以四分位距的的1.5倍为标准,超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。
以上三种方法为比较简单的判断异常值的方法,较为复杂的异常值检测方法后续用到并深入了解后再进行添加。
2、异常值处理方法
- 删除含有异常值的记录:直接将含有异常值的记录删除;(具体操作见知识点7)
- 视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理;
- 平均值修正:可用前后两个观测值的平均值修正该异常值;
- 不处理:直接在具有异常值的数据集上进行数据挖掘;
七、知识点7——pandas.DataFrame删除/选取含有特定数值的行或列
1、删除/选取某列含有特殊数值的行
import pandas as pd
import numpy as np
a=np.array([[1,2,3],[4,5,6],[7,8,9]])
df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC'))
print(df1)
df2=df1.copy()
#删除/选取某列含有特定数值的行
#df1=df1[df1['A'].isin([1])]
#df1[df1['A'].isin([1])] 选取df1中A列包含数字1的行
df1=df1[~df1['A'].isin([1])]
#通过~取反,选取不包含数字1的行
print(df1)

2、删除/选取某行含有特殊数值的列
import pandas as pd
import numpy as np
#删除/选取某行含有特定数值的列
cols=[x for i,x in enumerate(df2.columns) if df2.iat[0,i]==3]
#利用enumerate对row0进行遍历,将含有数字3的列放入cols中
print(cols)
#df2=df2[cols] 选取含有特定数值的列
df2=df2.drop(cols,axis=1) #利用drop方法将含有特定数值的列删除
print(df2)
八、知识点8——pandas DataFrame获取索引
df.index.values
以上就是“Python知识点整理(持续更新)”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









