







- 本节要从债券相关网站集思录上爬取可转债信息。在浏览器中打开网址https://www.jisilu.cn/data/cbnew/#cb,可看到可转债的各种信息,如下图所示。

- 首先用Selenium库访问网址并获取网页源代码,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.jisilu.cn/data/cbnew/#cb'
browser.get(url)
data = browser.page_source
- 虽然上面这个代码不能获取网页的源代码,但是仍能爬取网页上的表格。
- 然后在pandas库的read_html()函数提取网页中的所有表格,代码如下:
- 首先找到网页中的目标表格数据
import pandas as pd
tables = pd.read_html(data)
for i in range(len(tables)):
print(i)
print(tables[i])
第2行代码有时会jup中运行会报错,在pycharm运行一直报错。

- 其次将目标表格打印出来:
df = tables[0]
df

- 但是游客只能获取30条数据。
Selenium模拟登录获取所有数据
首先使用常用的模拟登录的源代码
import pandas as pd
from selenium import webdriver
import time
def get_browser():
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
return driver
browser = get_browser()
url = 'https://www.jisilu.cn/data/cbnew/#cb'
browser.get(url)
time.sleep(15)
data = browser.page_source
- 获取的是首页,而非目标页面:
用XPath表达式获取目标页的源代码
- 进入首页页面后,还需点击“实时数据”,进入实时数据页面后,在点击“可转债”按钮。
browser.find_element_by_xpath('//*[@id="nav_data"]').click()
time.sleep(3)
browser.find_element_by_xpath('//*[@id="app"]/div/div[2]/div[1]/div/div/div[2]/div/div[1]/a[5]').click()
time.sleep(3)
data = browser.page_source
获取所有的表格数据(存在MutiIndex问题)
tables = pd.read_html(data)
tables[0]
- 通过以下代码,将之导入到excel表中
df = tables[0]
df.to_excel('可转债(所有).xlsx')#如果加选择项index=False,会有如下报错
Writing to Excel with MultiIndex columns and no index ('index'=False) is not yet implemented.
- 打开excel表,发现列索引比较杂乱,原因是网页表格的表头中有合并单元格,形成了多重索引(MutiIndex)格式的列索引。
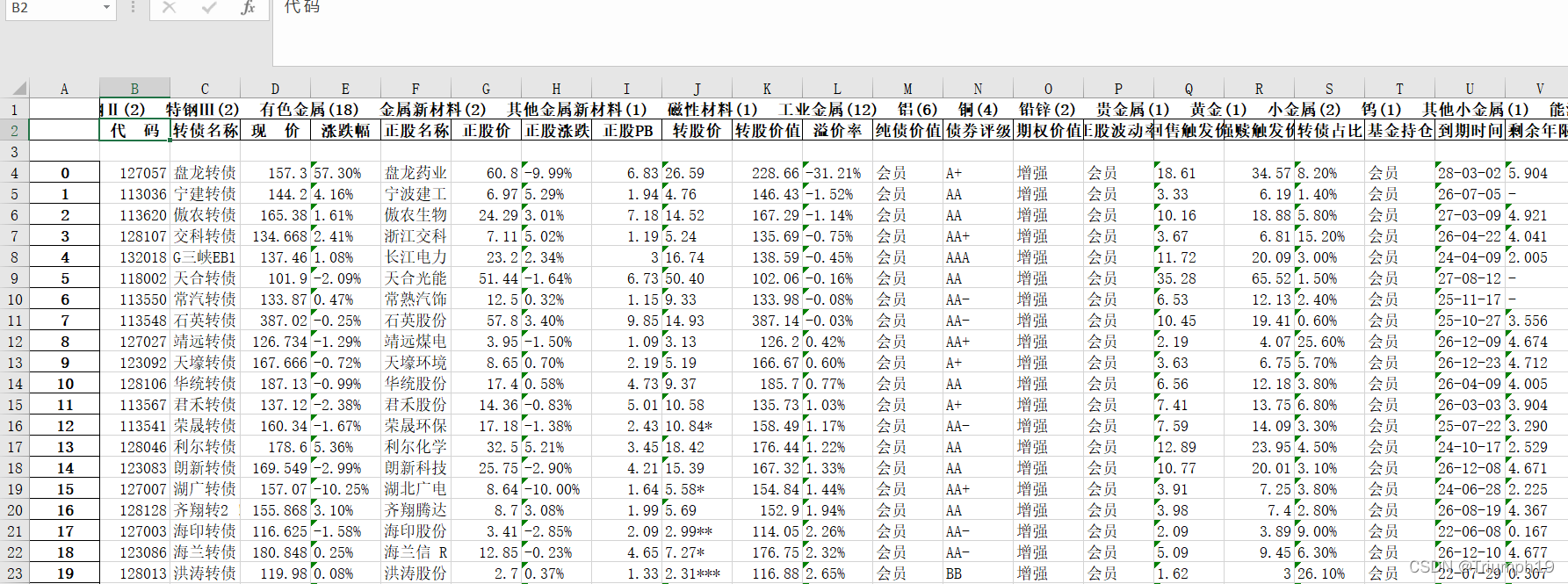
获取所有的表格数据(解决了MuniIndex问题)
- 此时,可通过read_html()函数的header参数指定以表格的第几行(从0开始计数)作为列索引。这里将header参数设置为1,代码如下:
tables = pd.read_html(data,header=1)
tables[0]

- 去除索引,并将之导入到Excel表中
#%%
df = tables[0]
df.to_excel('可转债(所有).xlsx',index=False)


















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









