







集思录网站中,提供了可转债的各类实时信息,本文记录下如何使用python自动从集思录获取到可转债的数据。
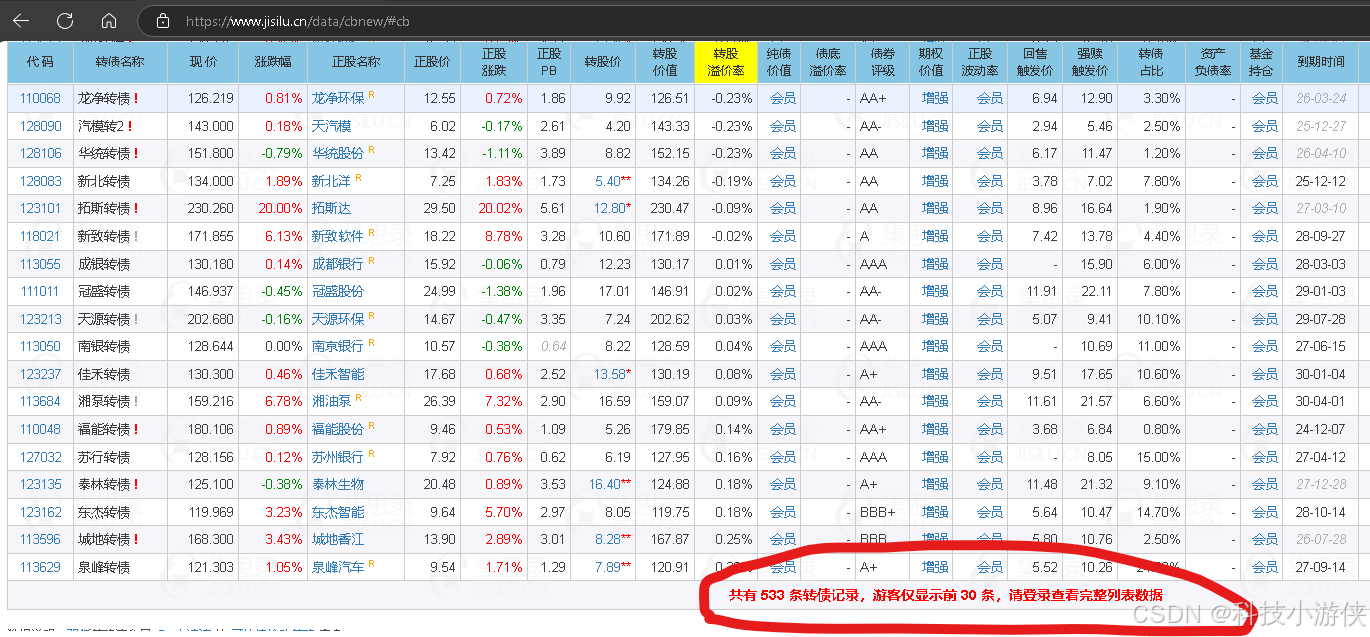
首先我们访问集思录的可转债链接,可以看到网页尾部提示游客仅显示前30条,所以这里需要先登录,而后访问数据链接。
方法一: 带用户缓存启动浏览器访问数据链接
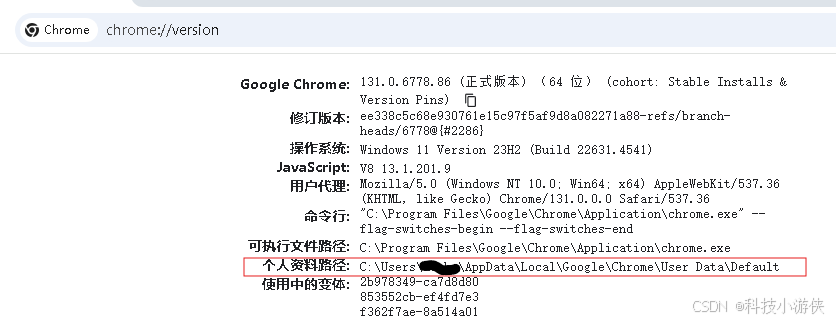
普通网站,当用户选择“记住我”或类似的选项时,网站通常会通过设置一个带有过期时间的Cookie来实现自动登录。这个Cookie的有效期可以是几天、几周甚至几个月,具体时间由网站开发者设定。利用这个自动登录就可以不需要写代码实现用户登录,对于简单的数据爬取,特别好用。实现也很简单,使用webdriver时,添加chrome的user data。
chrome_data_path = r'C:/Users/xxxx/AppData/Local/Google/Chrome/User Data' ###替换成自己的路径
options = webdriver.ChromeOptions()
options.add_argument('--user-data-dir=' + chrome_data_path)
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
使用webdriver_manager模块,可以自动匹配下载最新的chromedriver,十分方便。
其中,chrome_data_path可以在chrome中输入chrome://version/查看。
登录问题搞定后,后面就可以访问可转债数据页面,保存数据
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time
chrome_data_path = r'C:\Users\XXXXXX\AppData\Local\Google\Chrome\User Data' ###替换成自己的路径
options = webdriver.ChromeOptions()
options.add_argument('--user-data-dir=' + chrome_data_path)
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get('https://www.jisilu.cn/data/cbnew/#cb')
time.sleep(3)
tables = pd.read_html(driver.page_source,header=1)
all_talble = tables[0]
all_talble.to_excel('all_talble_方法1.xlsx',index=False)
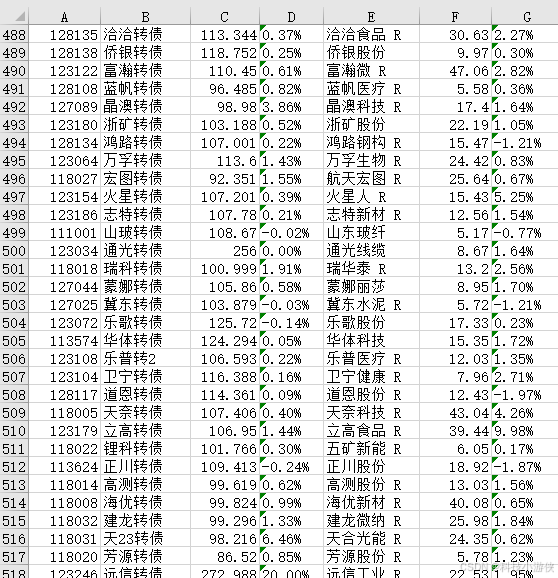
可以看到已经正确获取到所有的数据,同时,部分注释类的数据也被一同保存下来,需要另外处理下。
方法二 :增加自动登录
方法一中,使用用户缓存省去了部分登录代码,对于单次获取数据的小爬虫,或者调试都十分方便,如果需要每天自动获取数据,可以使用用户名、密码自动登录,这里只需要使用selenium 模拟登录即可。
以下为selenium 模拟登录的代码,同样很简单,剩下的就是对获取的数据进行二次加工即可。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time
user='XXXXX'
password='XXXXX'
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get('https://www.jisilu.cn/account/login/')
time.sleep(1)
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div/div/div[1]/div[1]/div[3]/form/div[2]/input").send_keys(user)
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div/div/div[1]/div[1]/div[3]/form/div[3]/input").send_keys(password)
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div/div/div[1]/div[1]/div[3]/form/div[5]/div[1]/input").send_keys(Keys.SPACE)
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div/div/div[1]/div[1]/div[3]/form/div[5]/div[2]/input").send_keys(Keys.SPACE)
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div/div/div[1]/div[1]/div[3]/form/div[6]/a").send_keys(Keys.ENTER)
driver.get('https://www.jisilu.cn/data/cbnew/#cb')
time.sleep(3)
tables = pd.read_html(driver.page_source,header=1)
all_talble = tables[0]
all_talble.to_excel('all_talble_方法2.xlsx',index=False)


















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









