







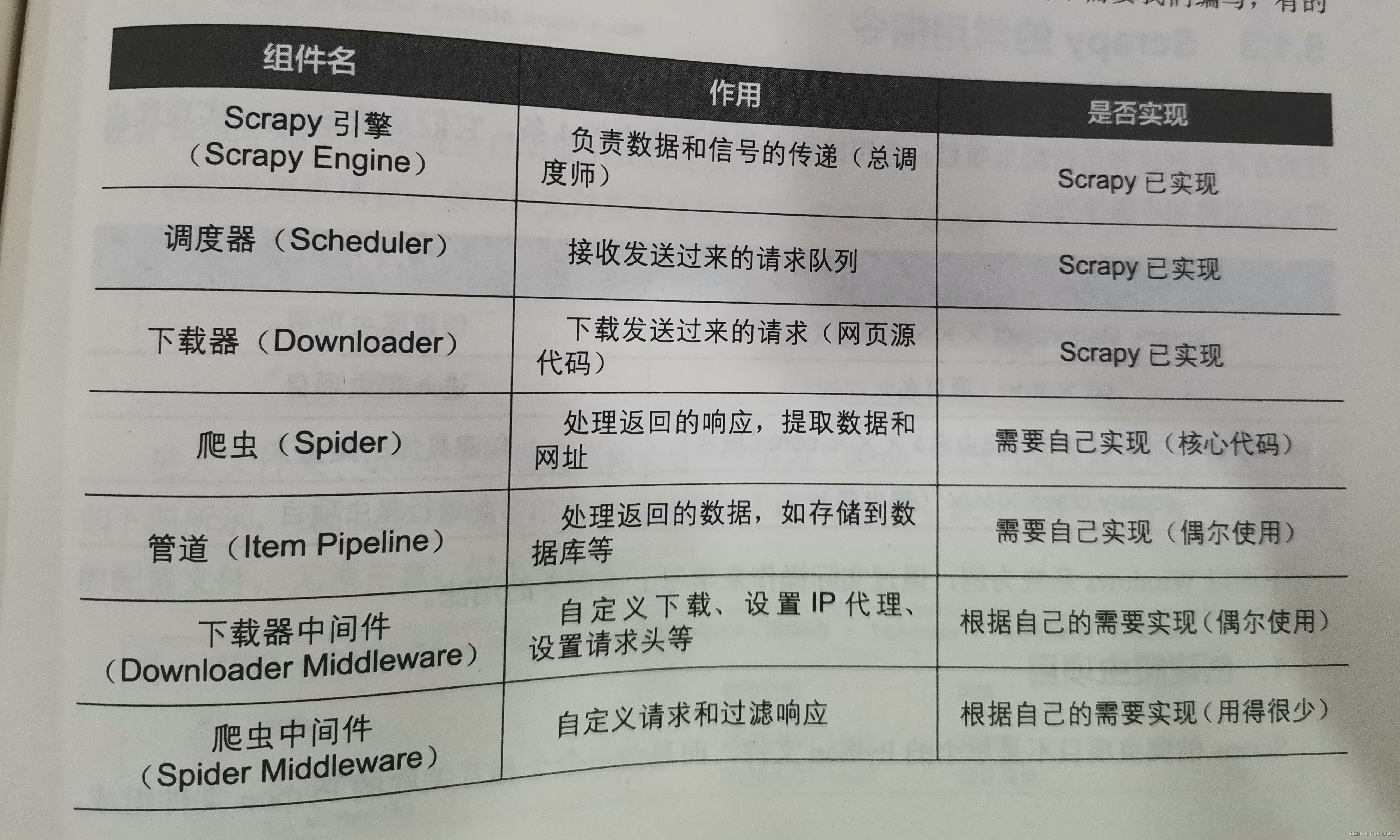
- Scrapy是一个高级Web爬虫框架,用于爬取网站并从页面中提取结构化数据。它可以用于数据挖掘、数据监控和自动化测试等多个方面。与之前讲过的Requests库和Selenium库不同,Scrapy更适合进行大批量的数据采集(类似于百度搜索引擎),其内容相对复杂。对于普通的爬虫学习者来说,如果只是做一些小规模的数据爬取(不超过10万条数据),而不是做类似百度搜索引擎那样超大规模的数据爬取,那么简单了解本章内容即可。
5.1 Scrapy 框架基础
- 前面说过,Scrapy 是一个爬虫框架。 所谓框架,可以理解成一个特殊的工具, 它集成了许多事先编写好的常规代码,并做好了这些代码文件的连接,这样用户就可以专注于编写自己的任务中个性化部分的代码,无须自己编写常规代码。
- Scrapy的优缺点也很明显:优点是异步、高并发(速度快),且易于进行项目维护,在大规模数据爬取任务中有较大的优势;缺点是与传统的Requests库和Selenium库相比,由于涉及多个Python文件的交互,其代码编写较为复杂,且在小规模数据爬取任务中优势不大。
- Scrapy官方文档英文版网址为htst:cs.crarp.org/e/atest.如果阅读英文有困难,可借助浏览器的翻译功能将其翻译成中文。
5.1.1 Scrapy的安装方法
- 如果应安装了Anaconda,那么通常可以直接使用命令“pip install scrapy”即可安装Scrapy。
5.1.2 Scrapy的整体框架
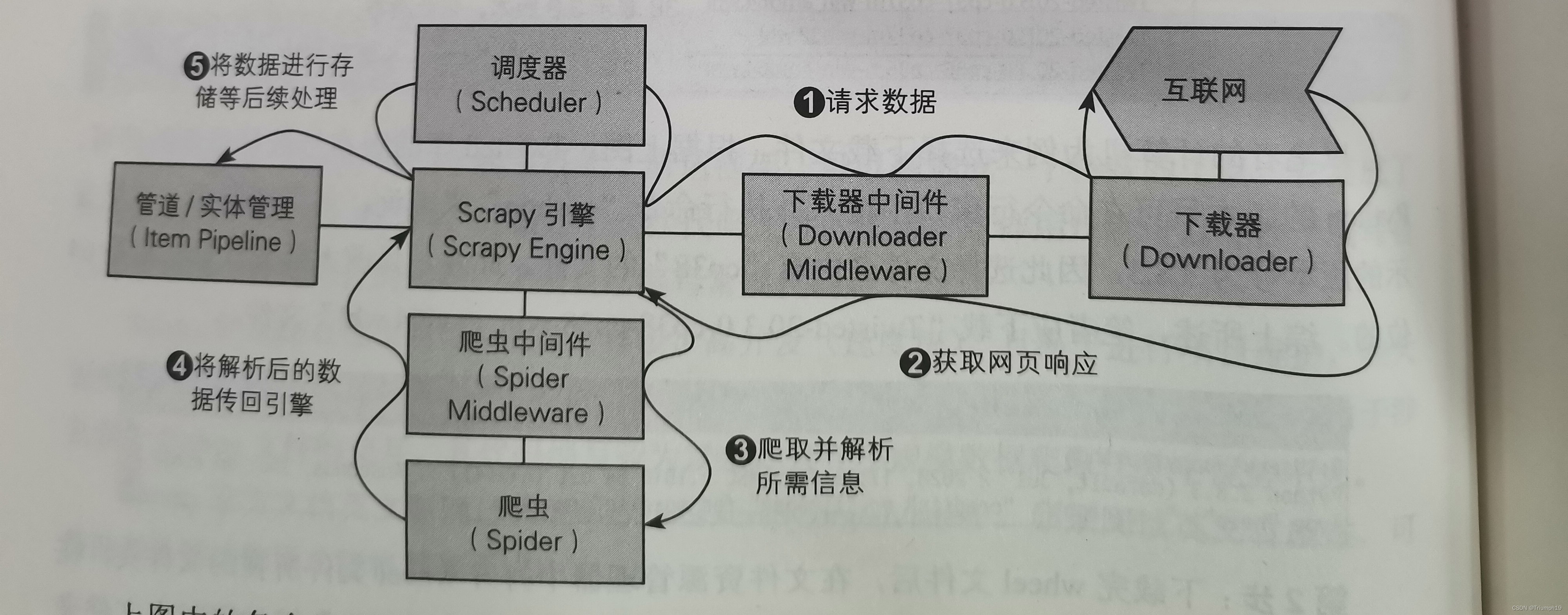
- Scrapy的整体架构和数据流向如下图所示(箭头表示各组件之间的数据流向)。初学者看到下图往往会因为有很多新名词而产生畏难情绪,其实如果抛开专业术语,透过现象看本质,Scrapy的核心逻辑与Requests库或Selenium库的爬虫逻辑并无区别,还是“请求数据、获取数据一解析数据一分析或处理数据”这一系 列操作。
- 如果暂时看不懂下图也没有关系,可以直接跳到5.1.3 节。接下来的案例实战会由简人繁地逐步讲解每一个组件, 在实战中能更形象地体会各个组件的功能及关联性。


5.1.3 Scrapy的常用指令
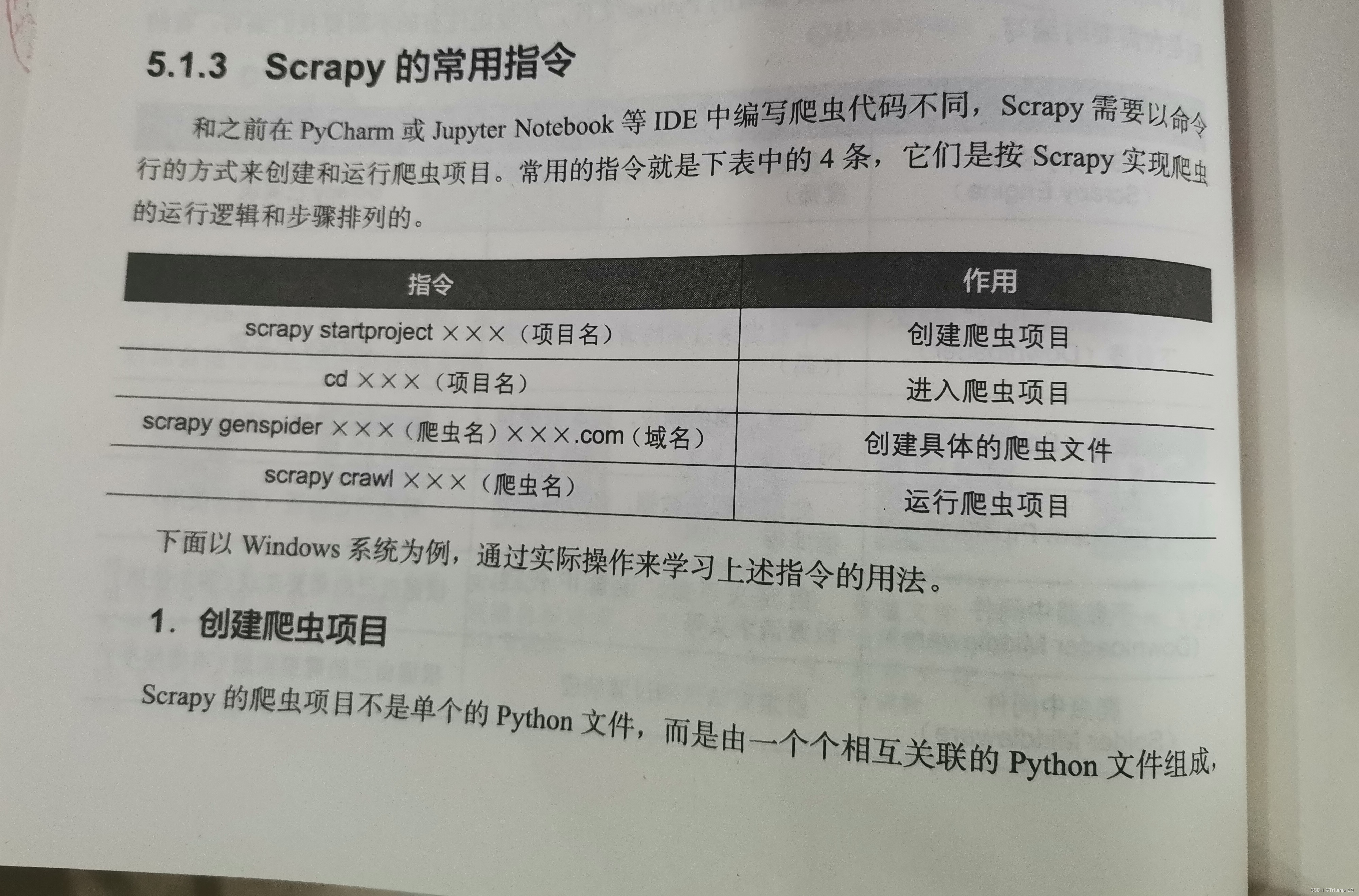
1.创建爬虫项目
- Scrapy的爬虫项目不是单个的Python文件,而是由一个个相互关联的Python文件组成。每个Python文件各司其职,发挥着不同的作用。因此,使用Scrapy框架的第一步就是创建爬虫项目。
- 假设要在文件夹“D:\works\python_crawl1\python爬虫(提高)\第五章 Scrapy爬虫框架”下创建爬虫项目。在文件资源管理器中进入该文件夹,在路径栏中输入“cmd”,如下图所示,按enter键,在该文件夹路径中打开命令行窗口。或者按住shift键的同时在文件夹中右击,然后选择“在此处打开Powershell窗口”命令。
D:\works\python_crawl1\python爬虫(提高)\第五章 Scrapy爬虫框架>scrapy startproject demo
New Scrapy project 'demo', using template directory 'C:\Users\***\AppData\Roaming\Python\Python39\site-packages\scrapy\templates\project', created in:
D:\works\python_crawl1\python爬虫(提高)\第五章 Scrapy爬虫框架\demo
You can start your first spider with:
cd demo
scrapy genspider example example.com
2. 进入爬虫项目
D:\works\python_crawl1\python爬虫(提高)\第五章 Scrapy爬虫框架>cd demo
3.创建具体的爬虫文件
- 进入项目后,我们可以创建具体的爬虫文件。以爬取百度为例,在上面代码后,输入并执行命令“scrapy genspider bai baidu.com”,创建具体的爬虫文件。“genspider”后的“baidu”为爬虫文件名,也可以换成其他名称,而“baidu.com”中的“baidu”则是百度的域名,不能换成其他内容,并且注意这里的爬虫文件不能和项目文件名相同。
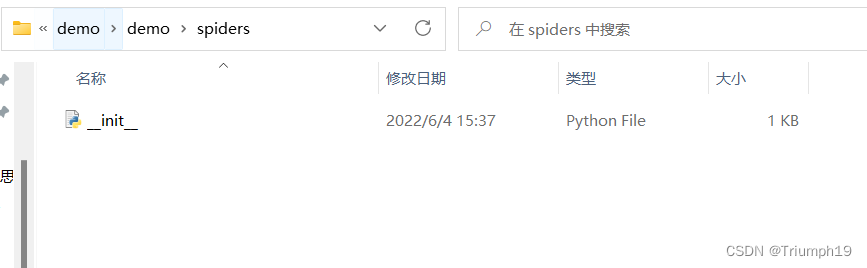
- 注意在没有创建具体的爬虫文件时,spider下面只有一个
__init__文件。
D:\works\python_crawl1\python爬虫(提高)\第五章 Scrapy爬虫框架\demo>scrapy genspider baidu baidu.com
Created spider 'baidu' using template 'basic' in module:
demo.spiders.bai #这里是具体路径
-
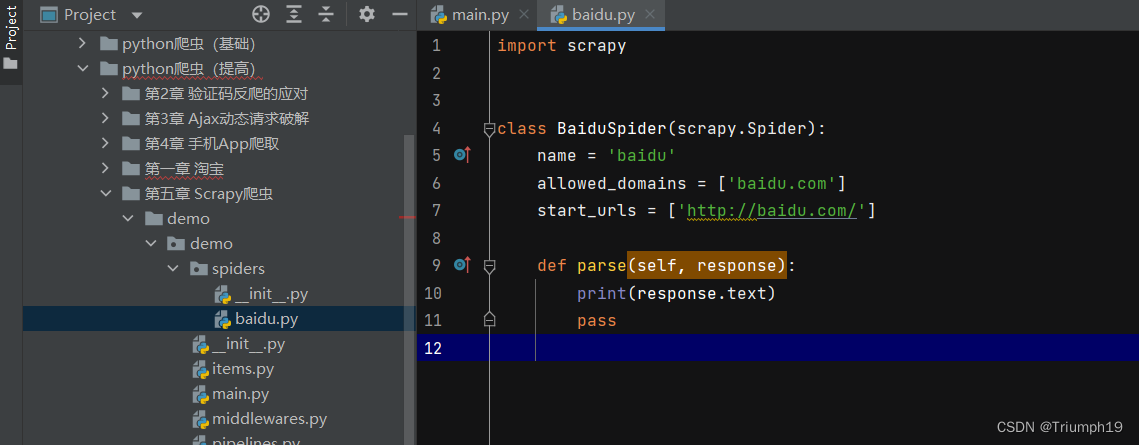
执行完上图中的指令后,在项目的文件夹“spiders”下就生成了一个名为“baidu.py”的python文件,如下图所示。
-
打开“baidu.py”,可以看到Scrapy框架自动生成的代码。其中定义了一个类BaiSpider,类中有一些属性和方法(类中的函数成为方法,两种略有些区别,不过无须深究)。

4.运行爬虫项目
- 接下来要做的就是运行爬虫项目。如果像在Pycharm中运行单个代码文件那样,(1)右击文件“baidu.py”,(2)在弹出的快捷菜单中执行“Run ‘baidu’”命令,(3)那么打印输出结果会是空白的。
- 这是因为Scrapy爬虫项目是由多个Python文件组成的,这里的“baidu.py”其实和其他Python文件有关联。如果只运行这一个文件,并不能真正启动爬虫项目。在Scrapy中,应该使用指定“scrapy crawl xxx(爬虫名)”来执行爬虫项目。这里的爬虫名为“baidu”,那么对应的指令为“scrapy crawl baidu”。
- 有两种方法来执行指令:在之前打开的命令行窗口中执行;在Pycharm的终端(Terminal)中执行。首先来演示在命令行窗口中执行。如下图所示,在命令行窗口中输入并执行指令“scrapy crawl baidu”。
D:\works\python_crawl1\python爬虫(提高)\第五章 Scrapy爬虫\demo>scrapy crawl baidu
-
运行结果如下,可以看到打印输出了一些内容,说明爬虫项目运行成功。在此次运行出现404,即没有找到网页(因为输入网址有误),但是也可以出现“DEBUG: Forbidden by robots txt <GET http://bai.com”(即百度的Robots协议进制直接通过Scrapy框架爬取。)对于Robots协议,将在5.2节讲解。

-
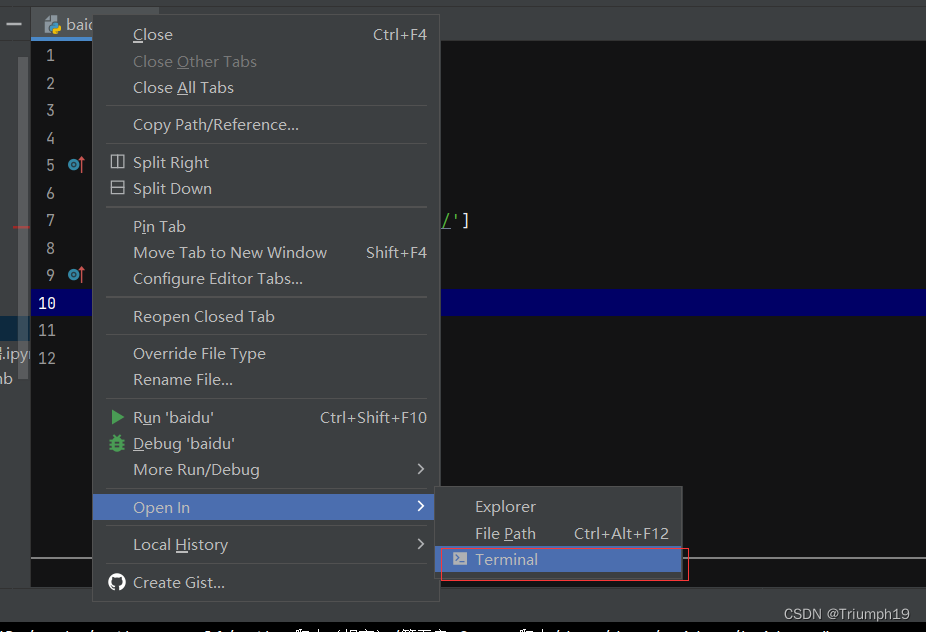
在PyCharm的终端中运行爬虫项目的操作更加简单,如下图所示:
-
然后在Terminal中输入指令“Scrapy crawl baidu”,如下图所示。

-
在PyCharm的终端中运行的结果和在命令行窗口中运行的结果一样。因为在Pytharm的终端中运行爬虫项目不仅操作简单,而且输出形式美观,所以之后都会以这种方式运行爬虫项目。
from scrapy import cmdline #这个本质也是在Terminal 终端运行
cmdline.execute("scrapy crawl baidu".split())
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









