









- Seaborn 是一个基于Matplotlib的高级可视化效果图,偏向于统计图表。因此,针对的主要是数据挖掘和机器学习中的变量特征的选取。相比Matplotlib,Seaborn的语法相对简单,绘制图表不需要花很多功夫去修饰,但是它绘图方式比较局限,不够灵活。
6.1 Seaborn 图表概述
- Seaborn是基于Matplotlib的Python可视化库。它提供了一个高级界面来绘制有吸引力的统计图形。Seaborn其实是在Matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使图表变得非常精致。
- Seaborn主要包括以下功能。
– 计算多变量间关系的面向数据集接口。
– 可视化类别变量的观测与统计。
– 控制线性回归的不同因变量,并进行参数估计与作图。
– 对复杂数据进行整体结构可视化。
– 对多表统计图的制作高度抽象,并简化可视化过程。
– 提供多个主题渲染Matplotlib图表的样式。
– 提供调色板工具生动再现数据。 - Seaborn是基于Matplotlib的图形可视化Python包。它提供了一种高度交互式界面,便于用户能够绘制出各种有吸引力的统计图表,如图6.1所示。
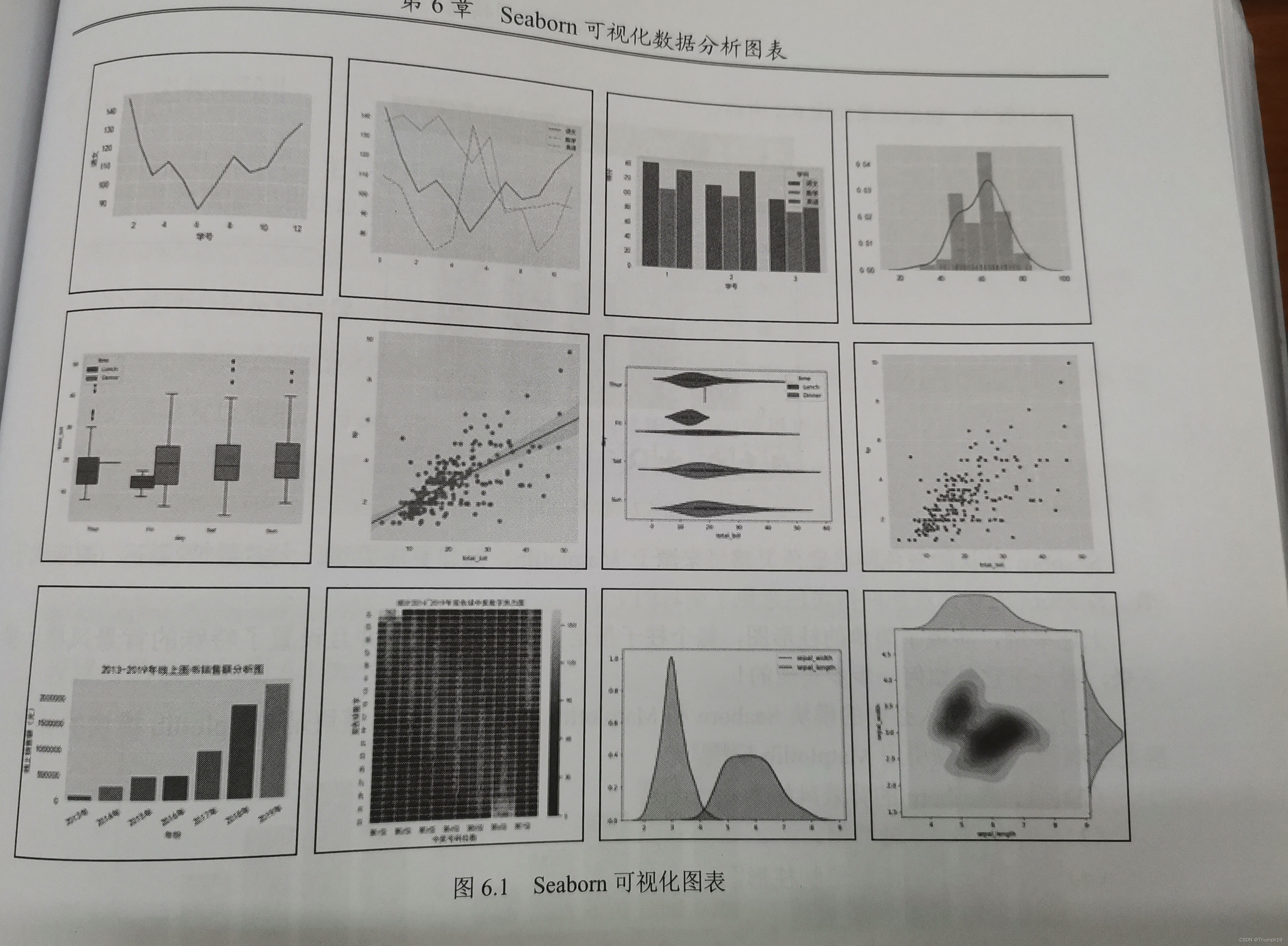
- 接下来进入安装环节,利用pip工具安装,命令如下:
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
- 或者,在Pytharm开发环境中安装。需要注意的是,如果安装报错,可能是读者尚未安装Scipy模块,因为Seaborn依赖于Scipy,所以需要先安装Scipy。
6.2 Seaborn图表之初体验
- 本节首先绘制一款简单的柱形图,让读者一睹Seaborn图表的风采,从而了解Seaborn绘制图表的基本过程。
- 安装好Seaborn模块后,开始绘制简单的柱形图,程序代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(4,3))
x=[1,2,3,4,5]
y=[10,20,30,40,50]
plt.bar(x,y)
plt.show()
sns.set_style('darkgrid')
sns.barplot(x,y)
plt.show() #形成预览模块,如果没有这行代码,则只能生成一种类型的图表
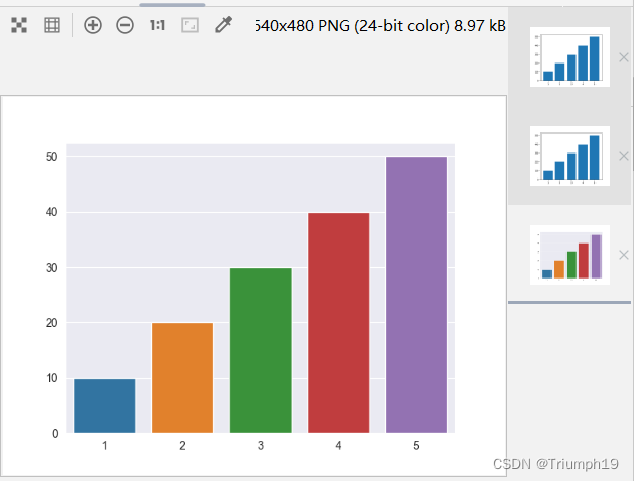
- Seaborn默认的灰色网格底色灵感虽来源于Matplotlib,却更加柔和。大多数情况下,图应优于表。Seaborn的默认灰色网格底色避免了刺目的干扰。
- 上述举例,实现了简单的柱形图,每个柱子指定了不同的颜色,并且设置了特殊的背景风格。接下来,看一下它是如何一步步实现的!
- (1)首先,导入必要的模块Seaborn和Matplotlib模块的补充,因此绘制图表前首先必须引用Matplotlib模块。
- (2)设置Seaborn的背景风格为darkgrid。
- (3)指定x轴,y轴数据。
- (4)使用barplot()函数绘制柱形图。
6.3 Seaborn图表的基本设置
6.3.1 背景风格
- 设置Seaborn背景风格,主要使用axes_style()函数和set_style()函数。Seaborn有5个主题,适用于不同的应用场景和人群偏好,具体如下。
- darkgrid:灰色网格(默认值)。
- whitegrid:白色网格。
- dark:灰色背景。
- white:白色背景。
- ticks:四周带刻度线的白色背景。
- 网格能够帮助我们查找图标中的定量信息,而灰色网格主题中的白线能避免影响数据的表现,白色网格主题更适合表达“重数据元素”。
6.3.2 边框控制
- 控制边框显示方式,主要使用despine()函数。
- (1)移除顶部和右边边框
sns.despine()
- (2)使两个坐标轴相隔一段距离。
sns.despine(offset=10,trim=True)
- (3)移除左边边框,与set_style()函数的白色网格配合使用效果更佳。
sns.set_style("whitegrid")
sns.despine(left=True)
- (4)移除指定边框,值设置为True即可。
sns.despine(fig=None,ax=None,top=True,right=True,left=True,bottom=False,offset=None,trim=False)
6.4 常用图表的绘制
6.4.1 绘制折线图(relplot()函数)
- 在Seaborn中实现折线图有两种方法:一是在replot()函数中通过设置kind参数为line绘制折线图;二是使用lineplot()函数直接绘制折线图。
1.使用relplot()函数
绘制学生语文成绩折线图(2)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
df1=pd.read_excel('data.xls') #导入Excel文件
#绘制折线图
sns.relplot(x="学号", y="语文", kind="line",data=df1)
# 关于subplots_adjust:https://blog.csdn.net/mighty13/article/details/116147658
plt.subplots_adjust(left=0.2, right=0.9, top=0.9, bottom=0.1)
plt.show()# 显示
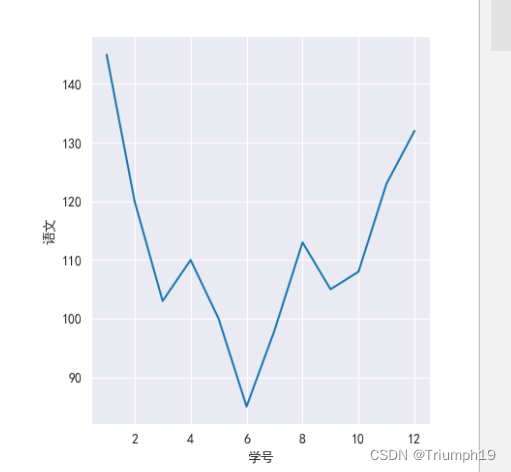
2.使用lineplot()函数
绘制学生语文成绩折线图2(3)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
df1=pd.read_excel('data.xls') #导入Excel文件
#绘制折线图
sns.lineplot(x="学号", y="语文",data=df1)
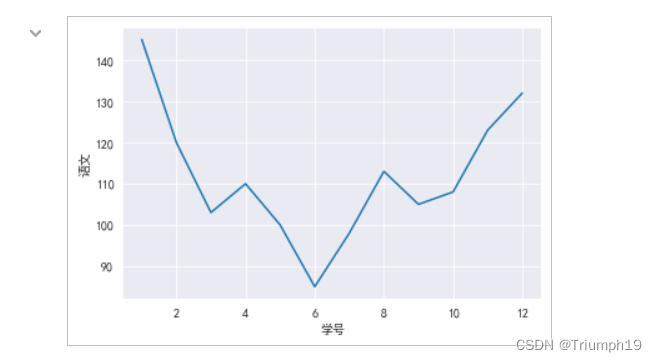
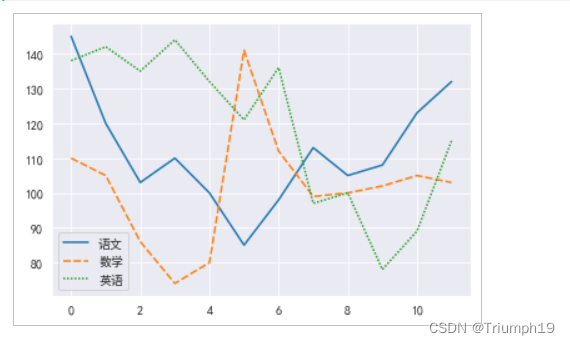
多折线图分析学生各科成绩(4)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
df1=pd.read_excel('data.xls') #导入Excel文件
#绘制多折线图
dfs=[df1['语文'],df1['数学'],df1['英语']]
sns.lineplot(data=dfs)
plt.show()# 显示
6.4.2 绘制直方图(displot()函数)
- Seaborn主要通过使用displot()函数绘制直方图,语法如下:
sns.displot(data,bins=None,hist=True,rug=False,fit=None,color=None,axlabel=None,ax=None)
- data:数据
- bins:设置矩形图数量。
- hist:是否显示条形图。
- kde:是否显示核密度估计图,默认值为True,显示核密度估计图。
- rug:是否在x轴上显示观测的小细条(边际毛毯)。
- fit:拟合的参数分布图形。
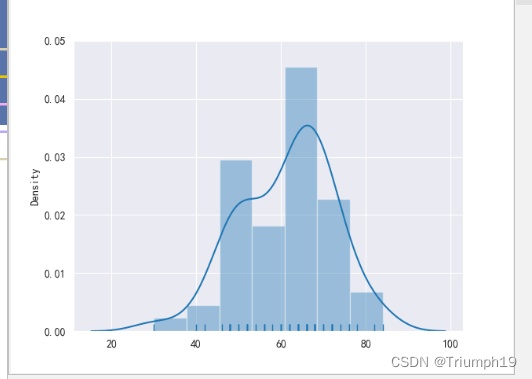
绘制简单直方图(5)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
df1=pd.read_excel('data2.xls') #导入Excel文件
data=df1[['得分']]
sns.distplot(data,rug=True) #直方图,显示观测的小细条
plt.show()# 显示
6.4.3 绘制条形图(barplot()函数)
- Seaborn主要通过使用barplot()函数绘制条形图,语法如下:
sns.barplot(x=None,y=None,hue=None,order=None,hue_order=None,orient=None,color=None,palette=None,capsize=None,estimator=mean)
- x,y:x轴、y轴数据。
- hue:分类字段。
- order、hue_order:变量绘图顺序。
- orient:条形图是水平显示还是竖直显示。
- capsize:误差线的宽度。
- estimator:每类变量的统计方式,默认值为平均值mean。
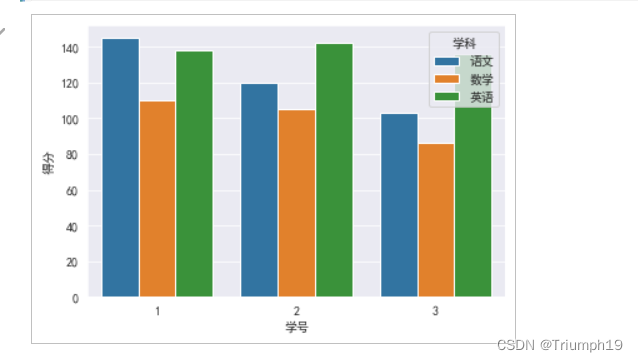
多条形图分析学生各科成绩(06)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
df1=pd.read_excel('data.xls',sheet_name='sheet2') #导入Excel文件
sns.barplot(x='学号',y='得分',hue='学科',data=df1) #条形图
plt.show()# 显示
6.4.4 绘制散点图(replot()函数)
- Seaborn主要通过使用replot()函数绘制散点图,相关语法可参考“绘制折线图”。
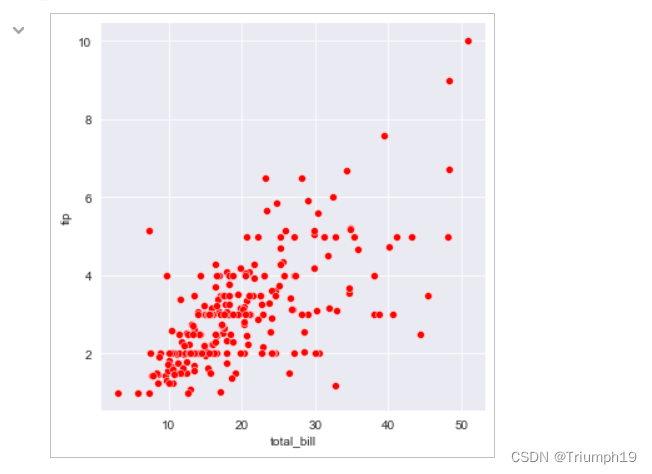
散点图分析“小费”(07)
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set_style('darkgrid')
#读取数据集tips(小费数据集),并对total_bill和tip字段绘制散点图
tips=pd.read_csv('tips.csv')
sns.relplot(x='total_bill',y='tip',data=tips,color='r')
plt.show()# 显示
6.4.5 绘制线性回归模型(Implot()函数)
- Seaborn 主要通过使用Implot()函数,可以直接绘制线性回归模型,用以描述线性关系,语法如下:
sns.lmplot(x,y,data,hue=None,col=None,row=None,palette=None,col_wrap=3,size=5,markers='o')
- hue:散点图中的分类字段。
- col:列分类变量,构成子集。
- row:行分类变量。
- col_wrap:控制每行子图数量。
- size:控制子图高度。
- markers:点的形状。
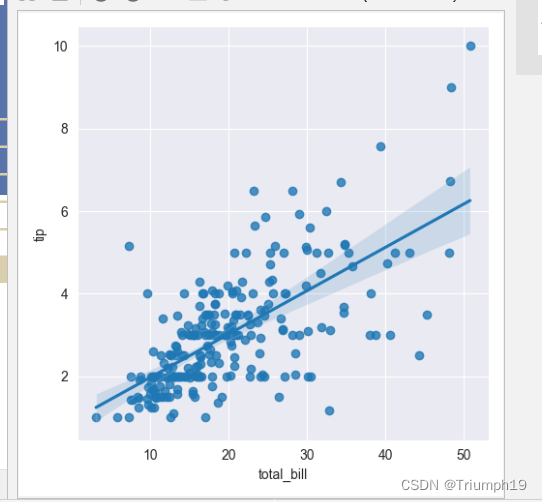
线性回归模型分析“小费”(08)
- 同样使用tips数据集,绘制线性回归模型,主要代码如下:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set_style('darkgrid')
#读取数据集tips
tips=pd.read_csv('tips.csv')
#绘制回归模型,描述线性关系
sns.lmplot(x='total_bill',y='tip',data=tips)
plt.show()# 显示
6.4.6 绘制箱型图(boxplot()函数)
- Seaborn主要通过使用boxplot()函数绘制箱型图,语法如下:
sns.boxplot(x=None,y=None,hue=None,data=None,order=None,hue_order=None,orient=None,color=None,palette=None,width=0.8,notch=False)
- hue:分类字段。
- width:箱型图宽度。
- notch:中间箱体是否缺口,默认值为False。
箱形图分析“小费”异常数据。(09)
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set_style('darkgrid')
#读取数据集tips
tips=pd.read_csv('tips.csv')
#绘制箱形图
sns.boxplot(x='day',y='total_bill',hue='time',data=tips)
plt.show()# 显示图表

- 从图6.11得知:数据存在异常值。箱形图实际上就是利用数据的分位数来识别数据的异常点,这一特点使得箱形图在学术界和工业界的应用非常广泛。
6.4.7 绘制核密度图(kdeplot()函数)
- 核密度图是概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度图可以比较直观地看出数据样本本身的分布特征。
- Seaborn主要通过使用kdeplot()函数绘制核密度图,语法如下:
sns.kdeplot(data,shade=True)
- data:数据。
- shade:是否带阴影,默认值为True,带阴影。
核密度图分析鸢尾花(10)
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set_style('darkgrid')
#读取数据集iris
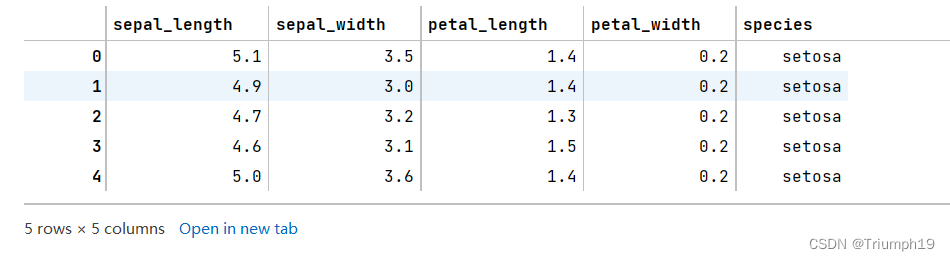
df=pd.read_csv('iris.csv')
#显示数据集
df.head()
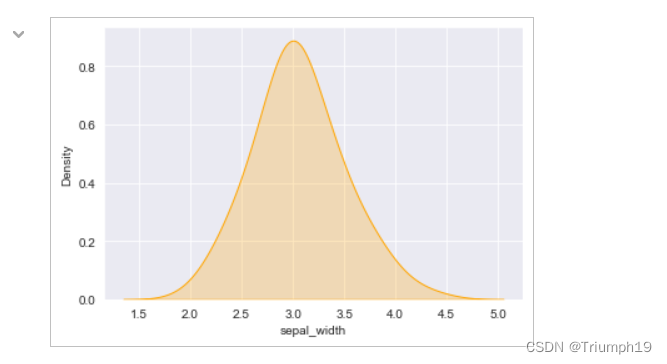
#绘制核密度图
# 关于参数kw,https://blog.csdn.net/Forrest97/article/details/113657125
sns.kdeplot(df['sepal_width'], shade=True, bw=.5, color="orange")
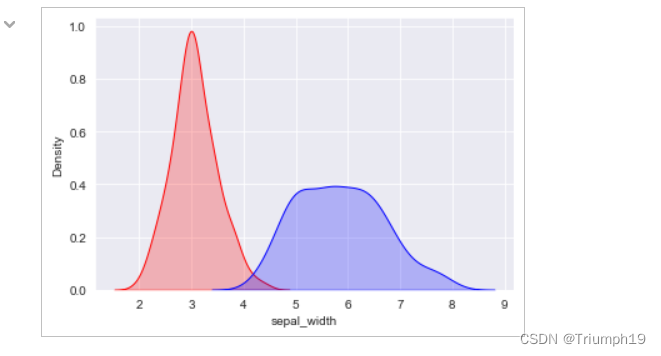
#绘制多个变量的核密度图
p1=sns.kdeplot(df['sepal_width'], shade=True, color="r")
p1=sns.kdeplot(df['sepal_length'], shade=True, color="b")
plt.show()
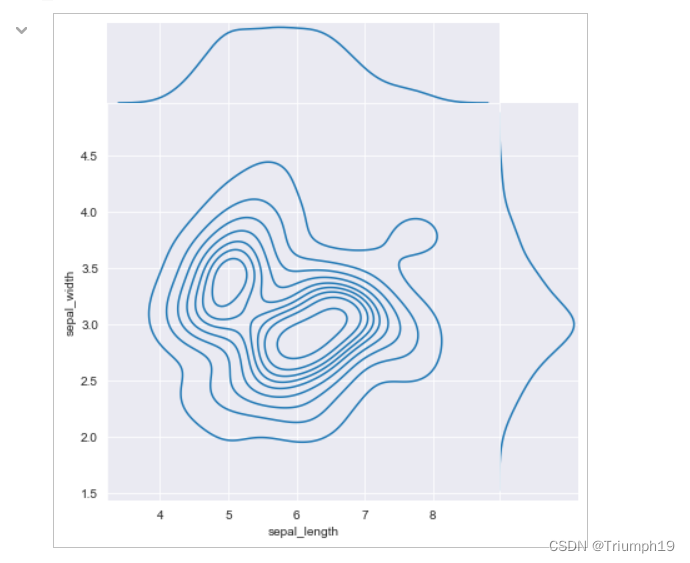
- 下面再介绍一种边际核密度图,该图可以更好地体现两个变量之间的关系。主要代码如下:
#边际核密度图
sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='kde',space=0)
plt.show()
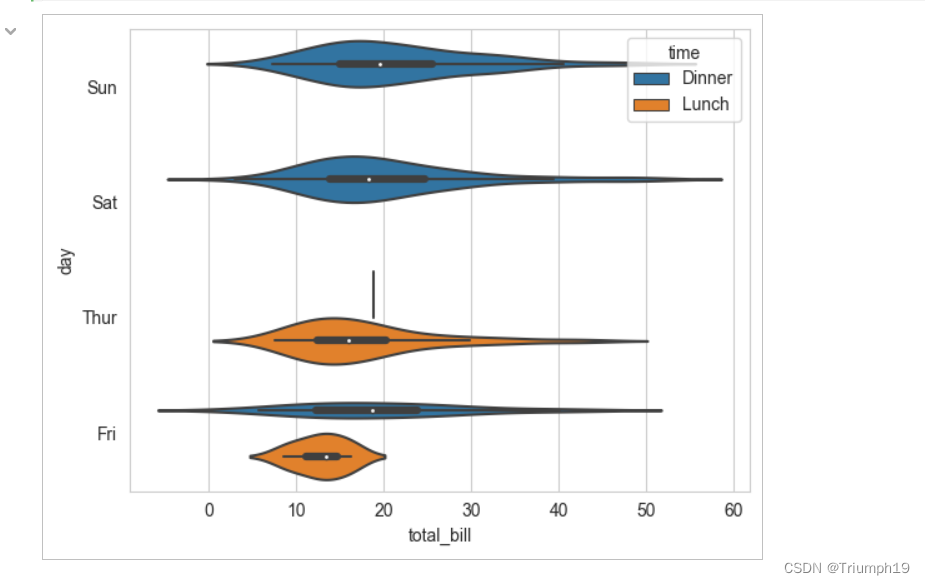
6.4.8 绘制提琴图(violinplot()函数)(11)
- 提琴图结合了箱形图和核密度图的特征,用于展示数据的分布形状。粗黑线表示四分位范围,延伸的细线表示95%的置信区间,白点为中位数,如图6.14所示。提琴图弥补了箱形图的不足,可以展示数据分布式双模还是多模。提琴图主要使用violinplot()函数绘制。
#%%
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
#读取数据集tips
tips =pd.read_csv('tips.csv')
sns.violinplot(x='total_bill',y='day',hue='time',data=tips)
plt.show()
6.5 综合应用
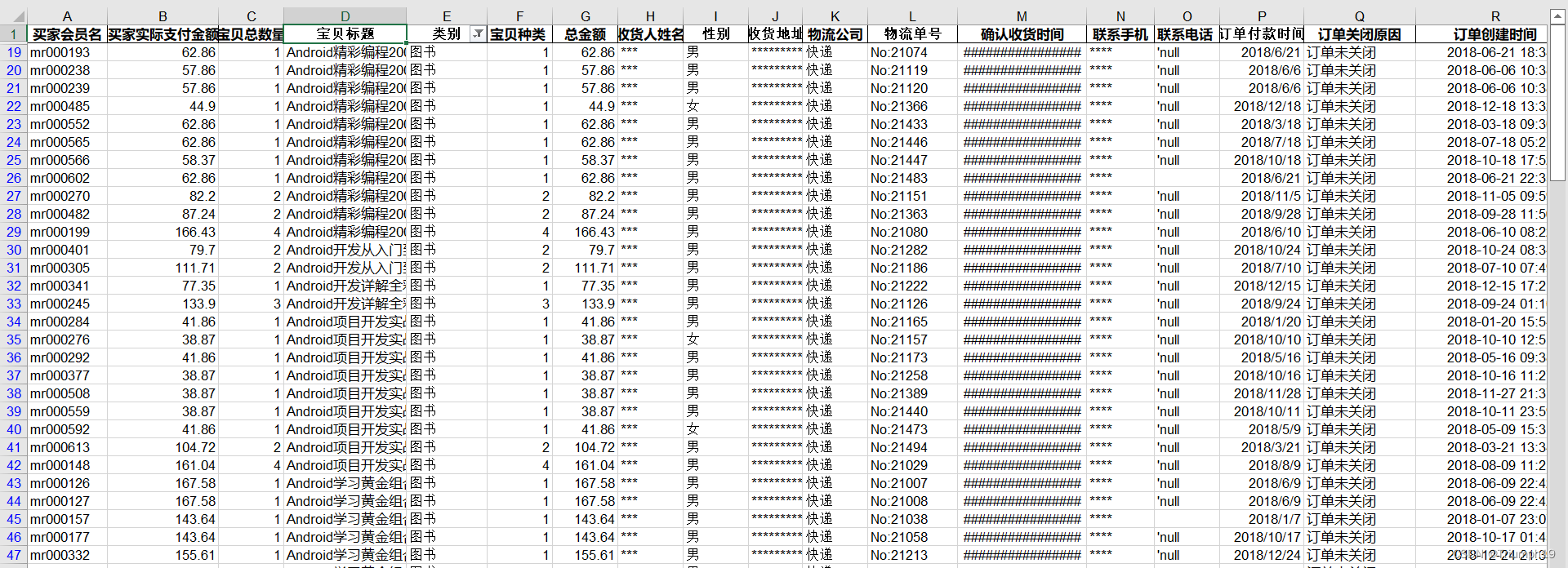
堆叠柱形图可视化数据分析图表的实现
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
sns.set_style('darkgrid')
file ='mrtb_data.xlsx'
df = pd.DataFrame(pd.read_excel(file))
plt.rc('font', family='SimHei', size=13)
df
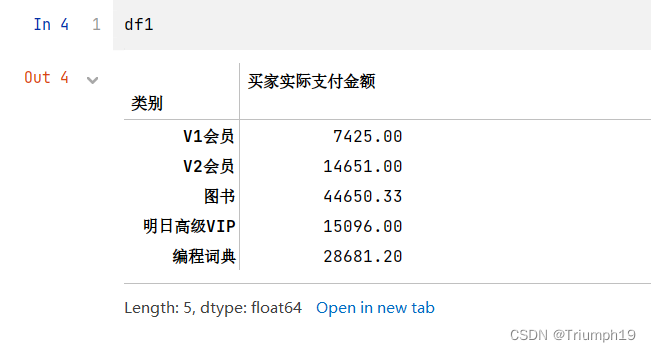
# 通过reset_index()函数将groupby()的分组结果重新设置索引
df1 = df.groupby(['类别'])['买家实际支付金额'].sum()
df2 = df.groupby(['类别','性别'])['买家会员名'].count().reset_index()
df1
df2
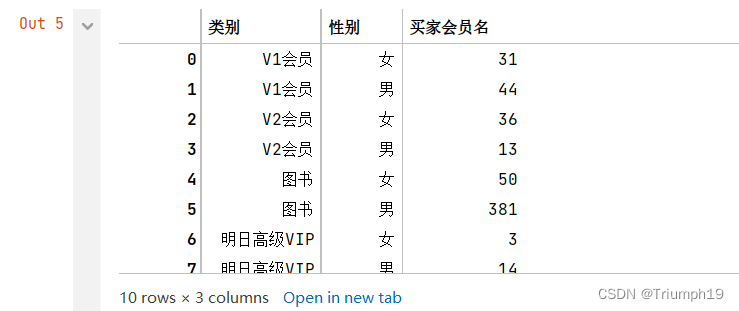
- 将df2中的男性和女性顾客分离出来:
men_df=df2[df2['性别']=='男']
women_df=df2[df2['性别']=='女']
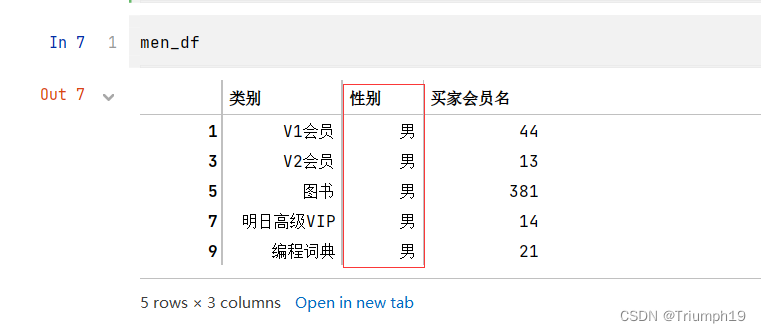
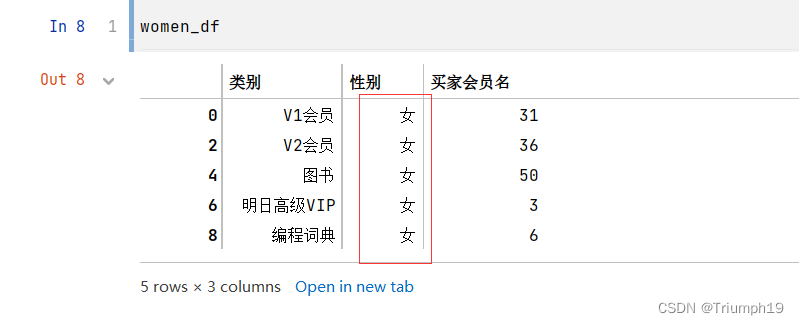
- 接下来把男性和女性买家数量变成一个列表:
men_list=list(men_df['买家会员名'])
women_list=list(women_df['买家会员名'])
num=np.array(list(df1)) #消费金额
##用np.array计算不同类别的男性用户比例
ratio=np.array(men_list)/(np.array(men_list)+np.array(women_list))
np.set_printoptions(precision=2) #使用set_printoptions设置输出的精度
#设置男生女生消费金额
men = num * ratio
women = num * (1-ratio)
df3=df2.drop_duplicates(['类别']) #去除类别重复的记录,这里只是为了获取x轴坐标的名称
name=(list(df3['类别']))
#生成图表
x = name
width = 0.5
idx = np.arange(len(x))
plt.bar(idx, men, width,color='slateblue', label='男性用户')
plt.bar(idx, women, width, bottom=men, color='orange', label='女性用户')
plt.xlabel('消费类别')
plt.ylabel('男女分布')
plt.xticks(idx+width/2, x, rotation=20)
#在图表上显示数字
for a,b in zip(idx,men):
plt.text(a, b, '%.0f' % b, ha='center', va='top',fontsize=12) #对齐方式'top', 'bottom', 'center', 'baseline', 'center_baseline'
for a,b,c in zip(idx,women,men):
plt.text(a, b+c+0.5, '%.0f' % b, ha='center', va= 'bottom',fontsize=12)
plt.legend()
plt.show()
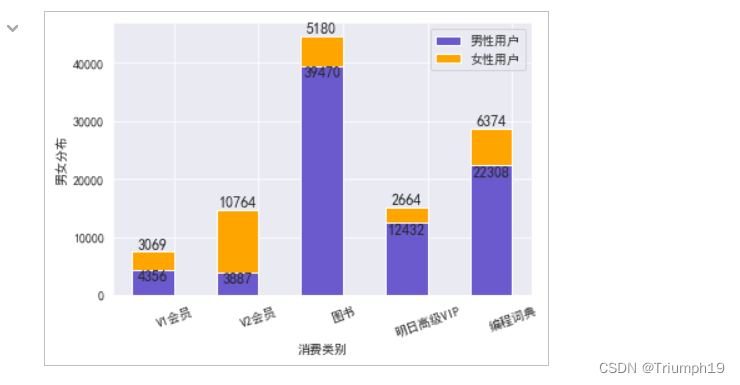
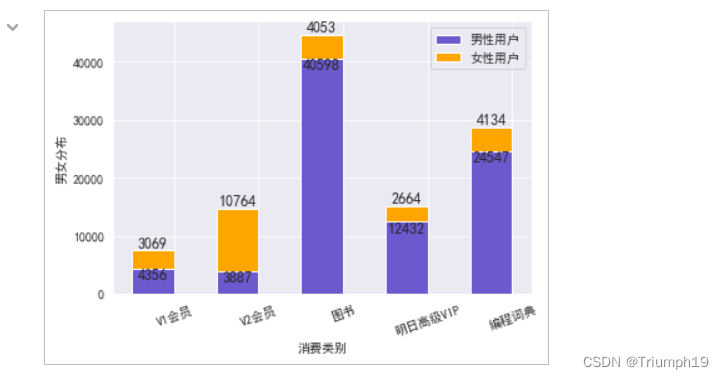
- 上述的数值结果式按照男性和女性买家的比例去分摊总金额,但是男性和女性实际支付的总金额和这种分摊方法计算出来的可能不一致(如果同一类别的男性和女性的购买数量不同),所以接下来直接计算男性和女性在每一类别上支付的总金额。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
sns.set_style('darkgrid')
file ='mrtb_data.xlsx'
df = pd.DataFrame(pd.read_excel(file))
plt.rc('font', family='SimHei', size=13)
df
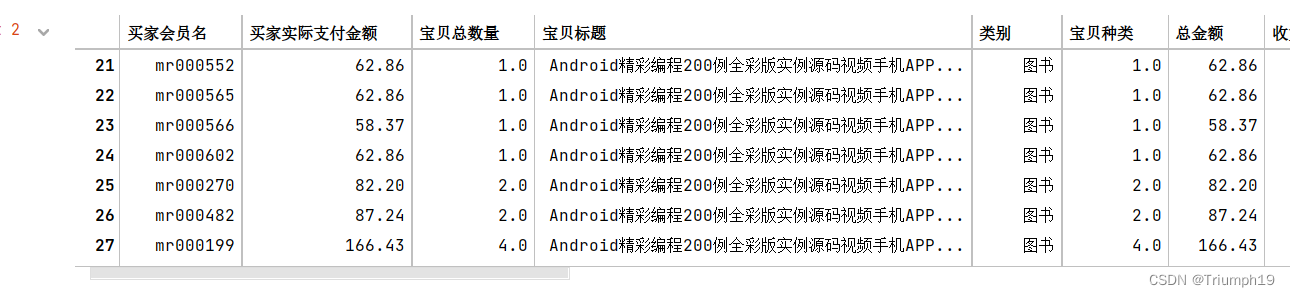
# 通过reset_index()函数将groupby()的分组结果重新设置索引
df2 = df.groupby(['类别','性别'])['买家实际支付金额'].sum().reset_index()
df2
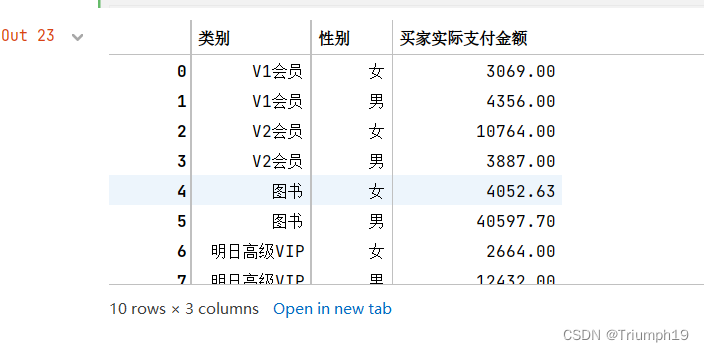
# 将男性和女性分离出来
men_df=df2[df2['性别']=='男']
women_df=df2[df2['性别']=='女']
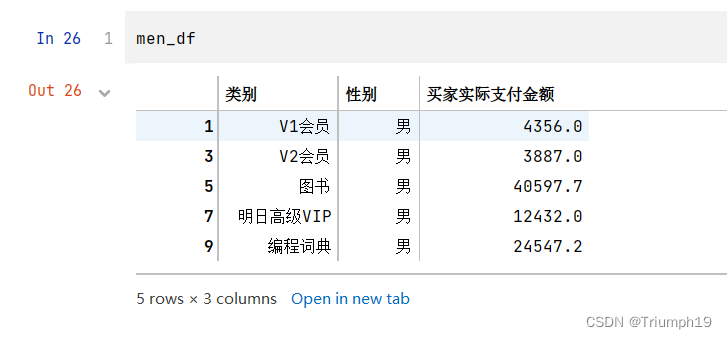
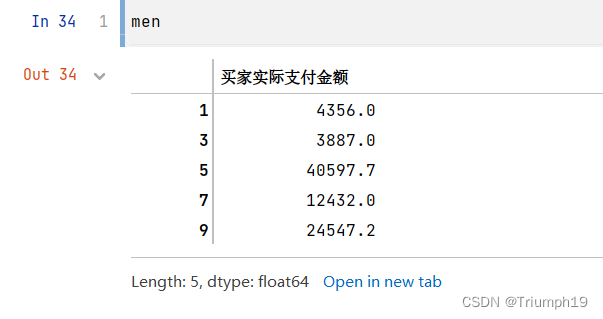
# 获取每一类别的男性和女性的实际支付金额
men = men_df['买家实际支付金额']
women= women_df['买家实际支付金额']
df3=df2.drop_duplicates(['类别']) #去除类别重复的记录,这里只是为了获取x轴坐标的名称
name=(list(df3['类别']))
#生成图表
x = name
width = 0.5
idx = np.arange(len(x))
plt.bar(idx, men, width,color='slateblue', label='男性用户')
plt.bar(idx, women, width, bottom=men, color='orange', label='女性用户')
plt.xlabel('消费类别')
plt.ylabel('男女分布')
plt.xticks(idx+width/2, x, rotation=20)
#在图表上显示数字
for a,b in zip(idx,men):
plt.text(a, b, '%.0f' % b, ha='center', va='top',fontsize=12) #对齐方式'top', 'bottom', 'center', 'baseline', 'center_baseline'
for a,b,c in zip(idx,women,men):
plt.text(a, b+c+0.5, '%.0f' % b, ha='center', va= 'bottom',fontsize=12)
plt.legend()
plt.show()
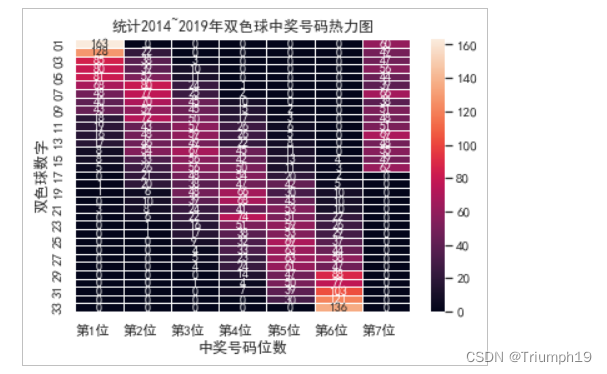
统计双色球中奖号码热力图
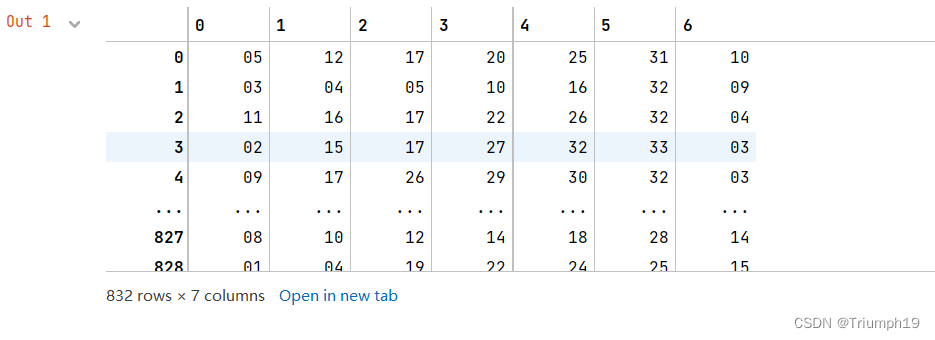
- 下面通过Seaborn热力图统计我们抓取到的2014-2019年双色球中奖金数据中,每一位中奖号码出现的次数的分布情况如下所示:
#%%
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set() # 使用默认设置
plt.figure(figsize=(6,6))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
df=pd.read_csv('data.csv',encoding='gb2312') #导入Excel文件
series=df['中奖号码'].str.split(' ',expand=True) #提取每一位中奖号码
series
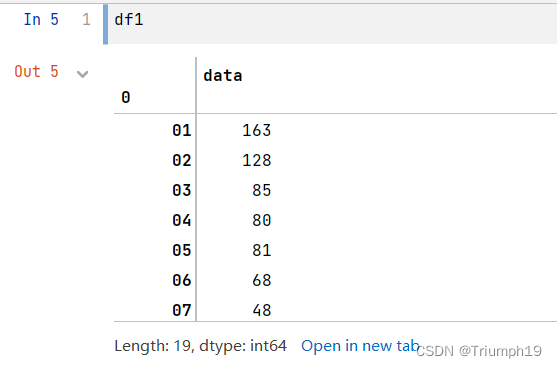
#对每一位中奖号码统计出现次数
df1=df.groupby(series[0]).size()
df2=df.groupby(series[1]).size()
df3=df.groupby(series[2]).size()
df4=df.groupby(series[3]).size()
df5=df.groupby(series[4]).size()
df6=df.groupby(series[5]).size()
df7=df.groupby(series[6]).size()
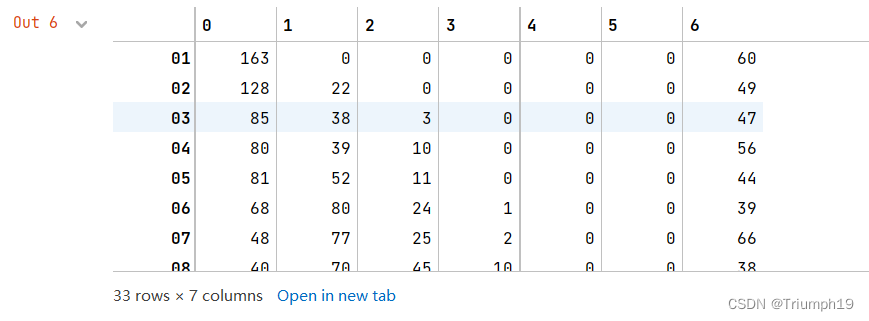
#横向表合并(行对齐)
data = pd.concat([df1,df2,df3,df4,df5,df6,df7], axis=1,sort=True)
data=data.fillna(0) #空值NaN替换为0
data=data.round(0).astype(int)#浮点数转换为整数\
data
plt.title('统计2014~2019年双色球中奖号码热力图')
sns.heatmap(data,annot=True, fmt='d', lw=0.5)#绘制热力图
plt.xlabel('中奖号码位数')
plt.ylabel('双色球数字')
x=['第1位','第2位','第3位','第4位','第5位','第6位','第7位']
plt.xticks(range(0,7,1),x,ha='left')
plt.show()















 3349
3349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









