






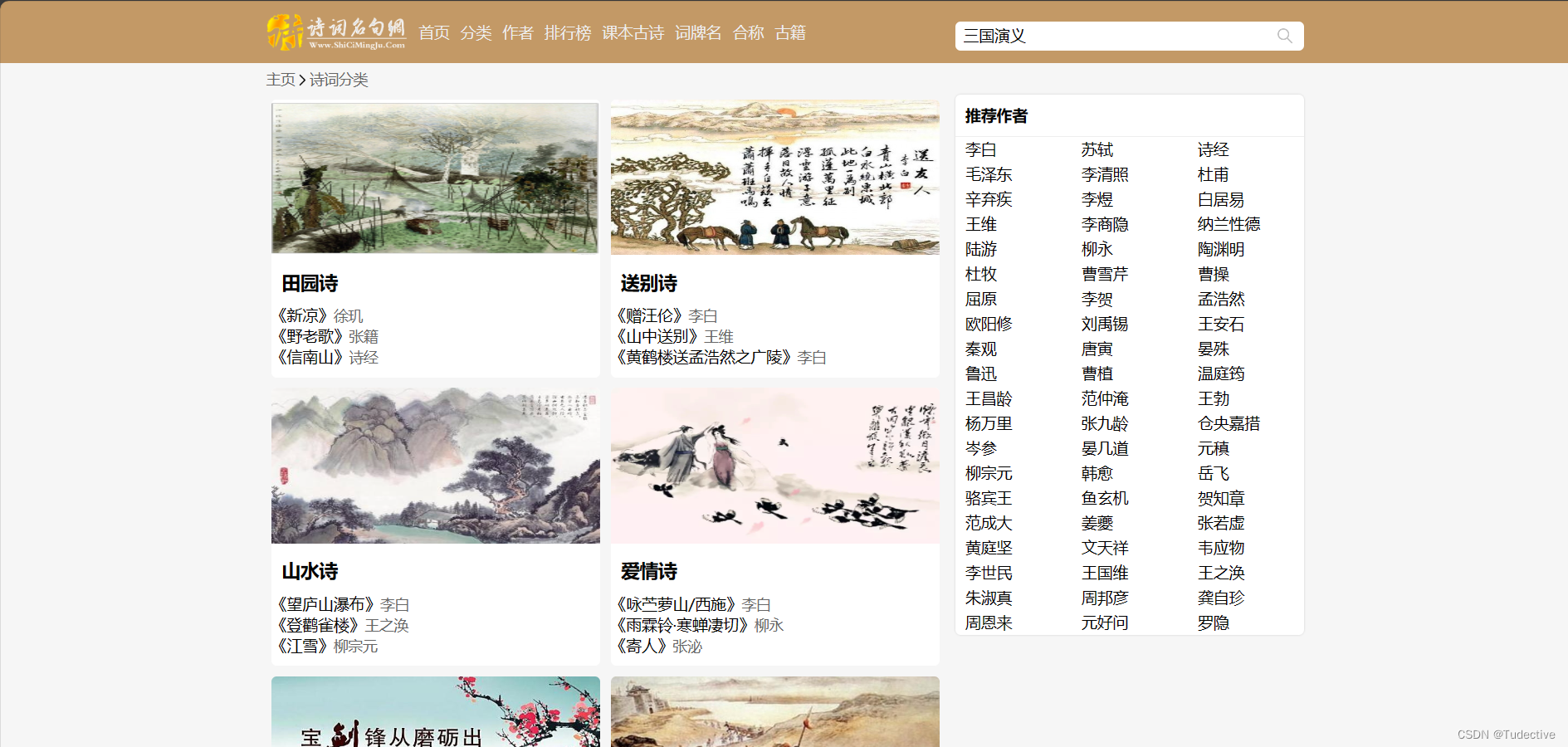
爬取的网站页面

使用Beautiful Soup
相比于正则表达式,此次爬取基于Python的BeautifulSoul来实现,Beautiful Soup是一个可以从HTML或XML中提取数据的Python库,结合lxml解析器能够快速定位到我们想要的元素和标签
准备工作
在开始之前,确保已经安装好Beautiful Soup和lxml。如果没有安装,请参考下面的安装教程。
pip install bs4
pip install lxml还有所需要的导入的库,以及指定要请求的URL和UA检测
if __name__=="__main__":
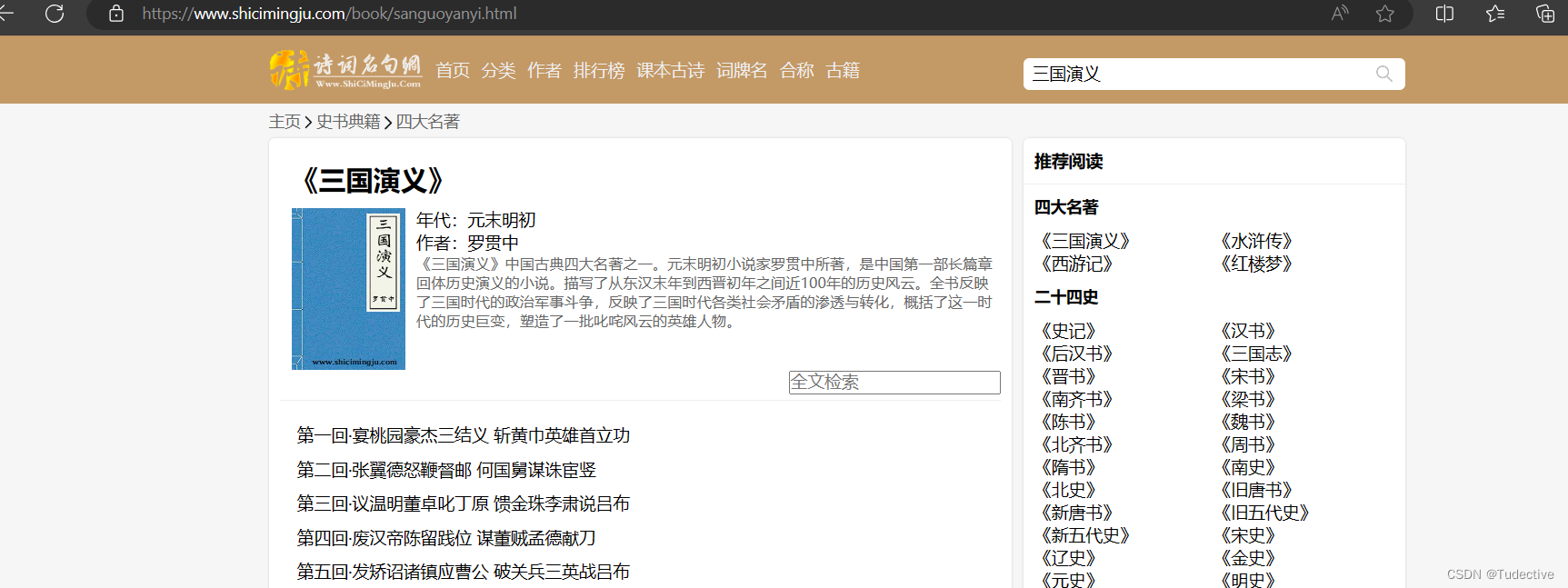
url="https://www.shicimingju.com/book/sanguoyanyi.html"
headers = {
'User-Agent': "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Mobile Safari/537.36 Edg/122.0.0.0"
}
page_text=requests.get(url=url,headers=headers).content
我选择先爬取一本三国演义的,如有其他需求的小伙伴可以copy一下其他书籍的URL
# BeautifulSoup()方法返回的是一个bs4.BeautifulSoup对象(该对象表示整个HTML数据),我们可以根据这个对象来使用不同的方法来获得HTML中我们需要的数据
将请求的数据放入到BeautifulSoup中,通过lxml进行解析
soup=BeautifulSoup(page_text,'lxml')
通过按F12使用开发者工具会发现,每一个章节的标题都嵌套在ul标签的li标签里边
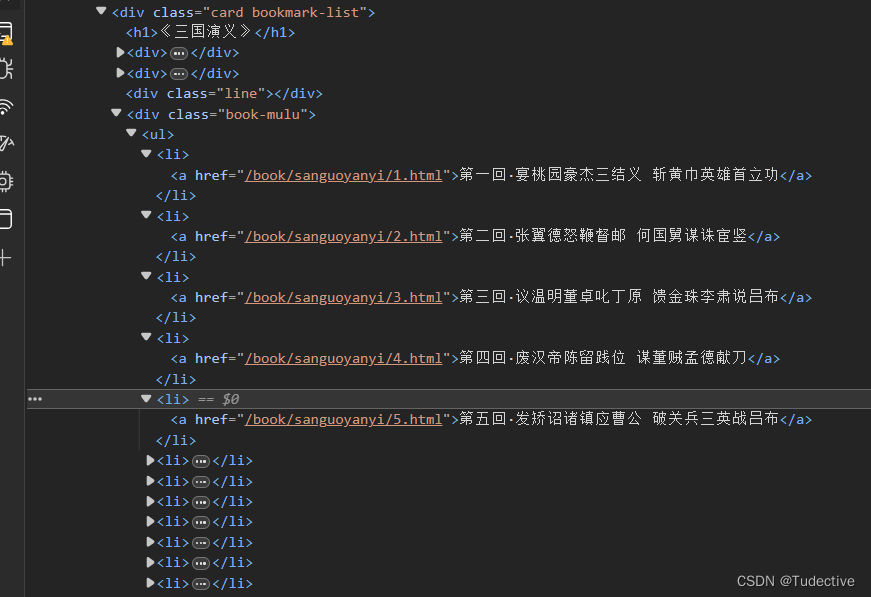
那么就可以使用刚刚返回一个bs4.BeautifulSoup对象调用select方法去定位它
#返回一个li的列表
li_list=soup.select('.book-mulu > ul > li')将这个li的列表进行循环遍历这样再去拿到每一个li标签里边的内容,获取详情页href然后在将其拼接成一个完整的URL,再次重新发起一个有关详情页的请求,并保存到BeautifulSoup进行解析
for li in li_list:
#获取标题
title=li.a.string
#获取详情页的url,并保存里边的内容
detail_url="https://www.shicimingju.com"+li.a['href']
detail_page_text=requests.get(url=detail_url,headers=headers).content
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
#获取div标签内所有的内容
div_tag=detail_soup.find('div', class_ ='chapter_content')
fp.write(title+":"+content+"\n")我们可以创建一个目录来保存我爬取的数据
fp=open('./book.txt','w',encoding='utf-8')
for li in li_list:
#获取标题
title=li.a.string
#获取详情页的url,并保存里边的内容
detail_url="https://www.shicimingju.com"+li.a['href']
detail_page_text=requests.get(url=detail_url,headers=headers).content
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
#获取div标签内所有的内容
div_tag=detail_soup.find('div', class_ ='chapter_content')
fp.write(title+":"+content+"\n")
print(title+"爬取成功")但是我们点击运行查看结果的时候可能会发现结果是存在乱码和一些NBSP,要解决这个问题可以
往里边加入指定编码格式为UTF-8和调用替换NBSP的方法
fp=open('./book.txt','w',encoding='utf-8')
for li in li_list:
#获取标题
title=li.a.string
#获取详情页的url,并保存里边的内容
detail_url="https://www.shicimingju.com"+li.a['href']
detail_page_text=requests.get(url=detail_url,headers=headers).content.decode('utf-8')
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
#获取div标签内所有的内容
div_tag=detail_soup.find('div', class_ ='chapter_content')
#获取文本内容去除文本内容里的NBSP
content=div_tag.text.replace(u'\xa0', '')
fp.write(title+":"+content+"\n")
print(title+"爬取成功")最后就可以直接点击运行了,可以看到批量的下载相应的详情页章节内容
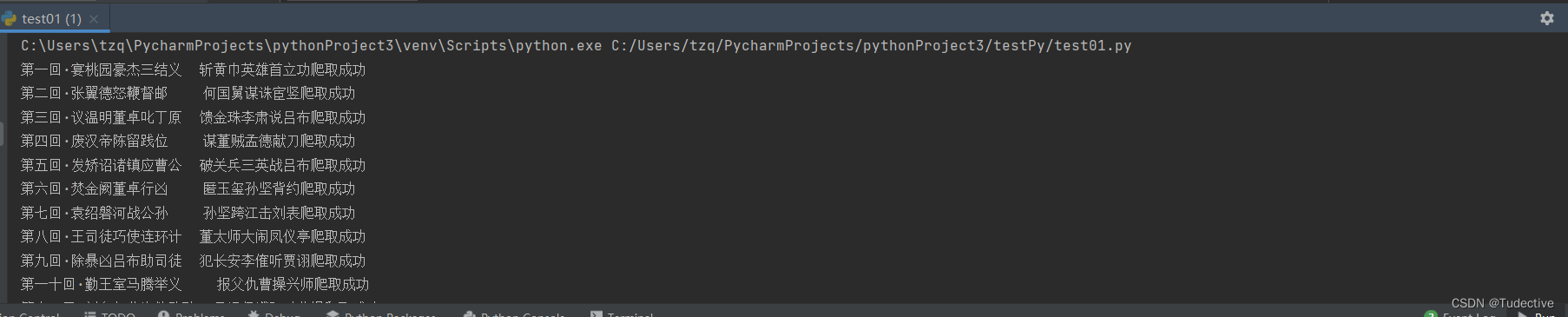
以下是完整的源代码,有兴趣的小伙伴们可以尝试爬取其他书籍哦
import requests
from bs4 import BeautifulSoup
if __name__=="__main__":
url="https://www.shicimingju.com/book/sanguoyanyi.html"
headers = {
'User-Agent': "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Mobile Safari/537.36 Edg/122.0.0.0"
}
page_text=requests.get(url=url,headers=headers).content
soup=BeautifulSoup(page_text,'lxml')
#返回一个li的列表
li_list=soup.select('.book-mulu > ul > li')
fp=open('./book.txt','w',encoding='utf-8')
for li in li_list:
#获取标题
title=li.a.string
#获取详情页的url,并保存里边的内容
detail_url="https://www.shicimingju.com"+li.a['href']
detail_page_text=requests.get(url=detail_url,headers=headers).content.decode('utf-8')
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
#获取div标签内所有的内容
div_tag=detail_soup.find('div', class_ ='chapter_content')
#获取文本内容去除文本内容里的NBSP
content=div_tag.text.replace(u'\xa0', '')
fp.write(title+":"+content+"\n")
print(title+"爬取成功")














 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









