






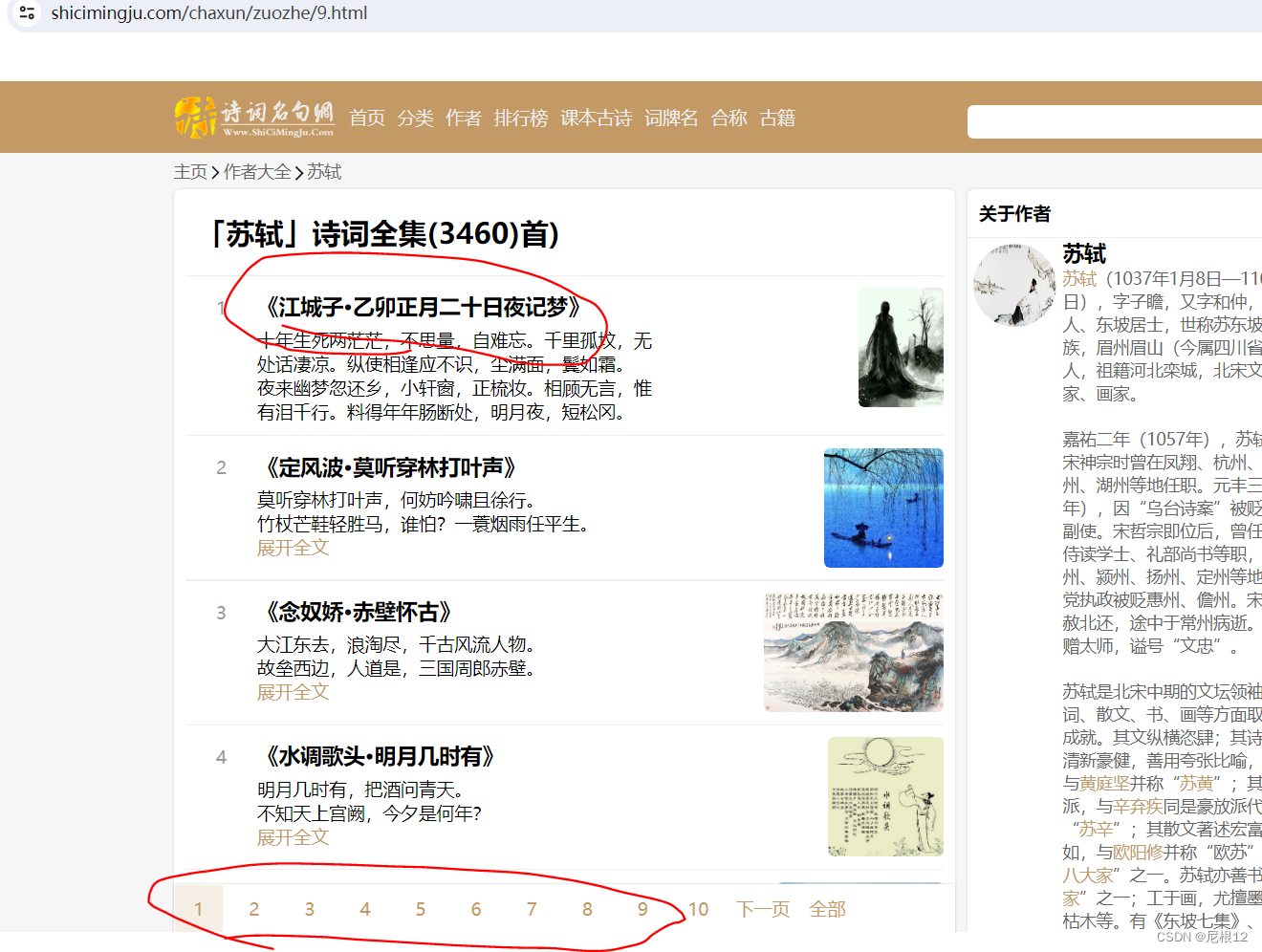
!!跳转到子页面爬取具体内容

import re
import requests
import os
from lxml import etree
headers={
'Cookie':'Hm_lvt_649f268280b553df1f778477ee743752=1716304979,1716338288,1716339809; Hm_lpvt_649f268280b553df1f778477ee743752=1716339954',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
def get_code(page):
if page == 1:
url = "https://www.shicimingju.com/chaxun/zuozhe/9_1.html"
else:
url = "https://www.shicimingju.com/chaxun/zuozhe/9_"+str(page)+".html"
response = requests.get(url=url,headers=headers)
response.encoding="utf-8"
content = response.text
return content
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath('//div[@class="card shici_card"]//div[@class="shici_list_main"]//h3/a/text()')
src_list = tree.xpath('//div[@class="card shici_card"]//div[@class="shici_list_main"]//h3/a/@href')
path = os.getcwd()
for i in range(len(name_list)):
name=name_list[i]
src = "https://www.shicimingju.com"+src_list[i]
print(name+src)
down_shi(src,name)
def down_shi(src,name):
# 题目// div[ @ id = "item_div"] / h1
response = requests.get(url=src, headers=headers)
response.encoding = "utf-8"
content = response.text
tree = etree.HTML(content)
neirong = tree.xpath('//div[@class="item_content"]//text()')
neirong_str = ''.join(neirong) # 列表变成字符串
neirong_str1 = neirong_str.replace("\n", "")
neirong_str1 = neirong_str1.replace(" ", "")
text = str(neirong_str1)
chinese_punctuation_pattern = r"[,。;!?……]"
lines = re.split(chinese_punctuation_pattern, text)
formatted_lines = [line + punct for line, punct in zip(lines[:-1], re.findall(chinese_punctuation_pattern, text))]
formatted_lines.append(lines[-1])
with open("古诗.txt", "a", encoding="utf-8") as fp:
fp.write(name+"\n")
fp.close()
for line in formatted_lines:
with open("古诗.txt", "a", encoding="utf-8") as fp:
fp.write(line+"\n")
fp.close()
if __name__ == "__main__":
start_page = 1
end_page = 2
for page in range(start_page, end_page+1):
content = get_code(page)
down_load(content)
爬取结果如下

















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









