







注:借鉴整理,仅供自学,侵删
1 动机
既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能
一般认为,网络越稀疏则越不容易过拟合,但过于稀疏性能又容易下降同时计算性价比又不高。GoogLeNet采用了多个小分支的结合,每个分支可以看作较为稀疏,但合并之后又成为一个大的密集矩阵。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构
把可能用到的不同大小(既可以提取不同特征)的卷积核都用上,让网络自己学习,有用的权值大,无用的权值小(趋于0?)
2 产生
网络更深更宽的缺点:
- 当训练集有限时,参数过多,模型会出现过拟合;
- 网络越大,计算复杂度越大,设计起来越困难;
- 当层数增多时,梯度越往后越容易消失,难以优化模型。(策略:抵抗梯度消失的策略就是网络前部再给予一部分梯度,这部分梯度就来自于两个辅助softmax loss)
针对上述缺点,我们考虑到一味的追求准确率而增加网络规模有一部分原因就是特征提取模块的设计没有能很好提取出图像的特征,如果能在基本的特征提取单元上做一些优化,然后用优化后的特征提取模块去构建网络,可能会有利于最后的识别效果。由此,Inception 模型孕育而生。
3 网络结构
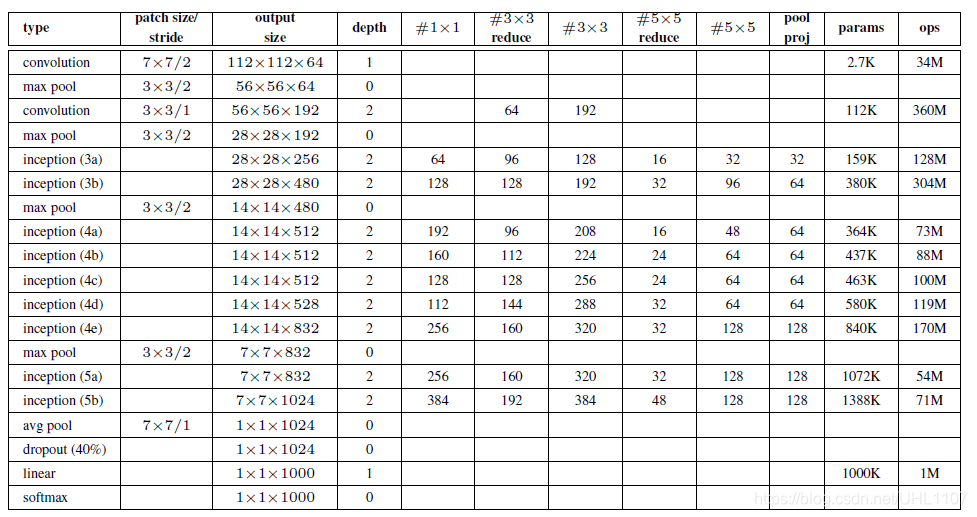
 对上图说明如下:
对上图说明如下:
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,加快训练。网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,提高模型的判别力。同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。

4 Inception结构
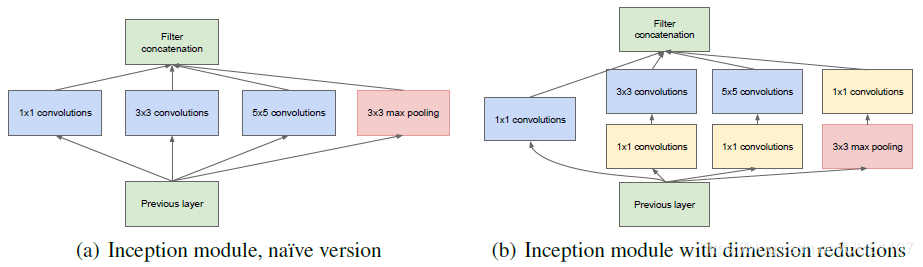
1*1卷积降维。
那么传统的卷积神经网络的做法,当有pooling时(pooling层会大量的损失信息),会在之前增加特征图的厚度(就是双倍增加滤波器的个数),通过这种方式来保持网络的表达能力,但是计算量会大大增加????
个人理解:所以更不能先1*1卷积再最大池化???















 6533
6533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









