







参考资料:http://dblab.xmu.edu.cn/blog/1233/
注:本篇博文的实验需要一个具有Hadoop集群环境的Docker镜像。
运行环境
Ubuntu20.04
Hadoop3.3.1
JDK8
1. 使用Docker开启三个容器
本次测试的节点介绍
| 节点名称 | 作用 |
|---|---|
| master | 主节点 |
| slave1 | 副节点 |
| slave2 | 副节点 |
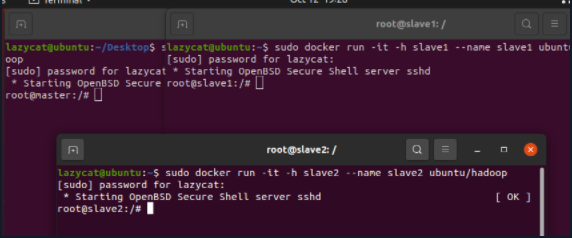
使用已具有Hadoop集群环境的镜像创建容器、一个终端负责控制一个容器
主节点
sudo docker run -it -h master --name master ubuntu/hadoop
副节点1
sudo docker run -it -h slave1 --name slave1 ubuntu/hadoop
副节点2
sudo docker run -it -h slave2 --name slave2 ubuntu/hadoop
*2. 配置ip映射 测试ssh
接下来的操作需对三个节点同时进行
每次容器重新启动后都需要配置hosts
vim etc/hosts
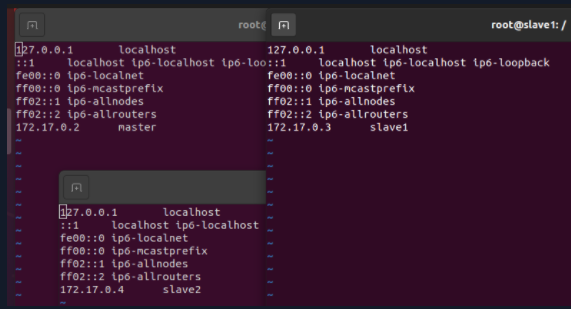
根据查询可知,三个节点的IP信息如下表所示:
| 节点名称 | 映射的IP |
|---|---|
| master | 172.17.0.2 |
| slave1 | 172.17.0.3 |
| slave2 | 172.17.0.4 |
为了使他们三个节点能互相连接,需要在每个的配置文件里加上另外两个的IP,如下图所示
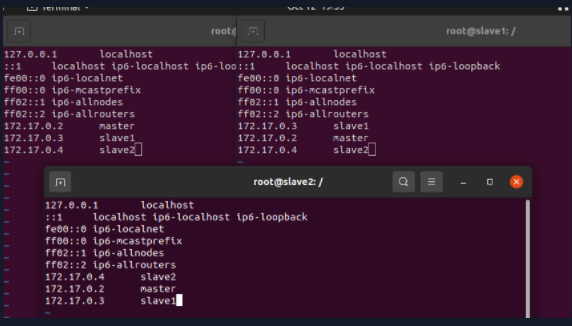
修改好后保存退出
测试SSH
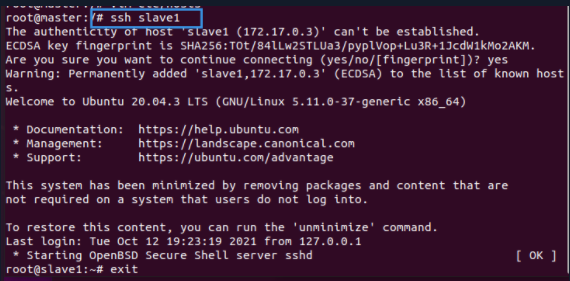
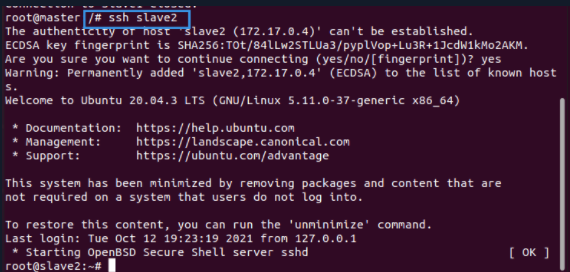
以Master节点为例,如果它能连接slave1和slave2,说明ssh功能完好(对slave1、slave2执行同样的操作,这里略过)
ssh slave1
exit
ssh slave2
exit
3. 修改Hadoop的配置文件
搭建Hadoop集群需要修改的配置文件有如下3个。因为已经开启了3个节点,这里采取的策略是先在master节点修改好配置文件,接着将该所有配置文件使用 cp命令复制到其他两个节点的对应目录下。注:表示集群节点的配置文件(workers) 需要单独修改
文件都在 ./etc/hadoop 的位置
hadoop-env.sh配置Hadoop运行相关的环境变量,比如设置JDK路径、集群各个进程的用户等等core-site.xml设置hadoop临时目录、HDFS的远程地址hdfs-site.xml对于HDFS,名称/数据节点存放位置、文件副本个数等mapred-site.xml设置MapReduce参数yarn-site.xml配置集群资源管理系统参数workers指定集群中工作的副节点
修改配置时,只添加内容,其他内容原封不变。
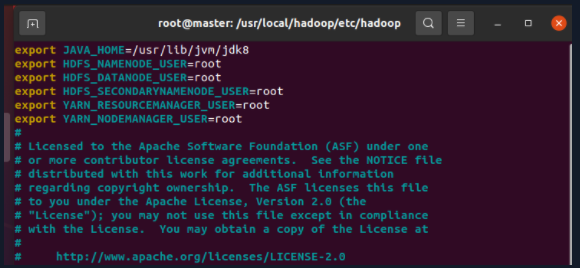
3.1 hadoop-env.sh
export JAVA_HOME=/usr/local/jdk8
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.2 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









