






方法:
软梯度增强机(sGBM)
:是
第一个可以
同时对所有基础学习者进行训练
的
可微
分梯度增强系统,极大地提高了训练效率。——>sGBM将
多个可微基础学习器连接在一起,并注入了来自梯度提升的局部和全局目标。由于整个结构是可微的,所有基础学习器可以联合优化,与原始的GBM相比,实现线性加速。当使用可微决策树作为基础学习器时,这种设备可以被视为(
硬)梯度决策树(GBDT)的替代版本,具有额外的好处,特别是在处理流数据方面。
目的:提升处理流数据的效率
结论:
实验验证了该方法的有效性
流数据
:指由数千个数据源持续生成的数据,通常也同时以数据记录的形式发送,规模较小(约几千字节)。流数据包括多种数据,例如客户使用您的移动或 Web 应用程序生成的日志文件、网购数据、游戏内玩家活动、社交网站信息、金融交易大厅或地理空间服务,以及来自数据中心内所连接设备或仪器的遥测数据。
点击率预测
:是对每次广告的点击情况做出预测,可以判定这次为点击或不点击,也可以给出点击的概率,有时也称pClick
。
协同过滤
:简单来说是利用某兴趣
相投、
拥有共同经验之群体的喜好
来推荐用户感兴趣的信息
,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选
信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
因为存储在每个参与者中的数据往往会随时间而变化——>适用于流数据的联邦学习模型受到关注——>基于软梯度提升机的最新进展,提出了适用于流数据的联邦软梯度提升机框架:与传统的梯度增强方法中基学习器的
顺序训练
相比,该框架中的每个基学习器都能以
并行和分布式
的方式进行有效训练——>实验验证了该方法的有效性
梯度提升机(GBM)已被证明是离散数据建模的最佳工具之一——>它的有效实现如:XGBoost、Light GBM、Cat Boost仍然是现实世界中 点击率(CTR)预测、协同过滤、粒子发现等的 主要工具——>将梯度提升和深度学习相结合的相关研究:
多层梯度提升决策树
是第一个具有学习分布式表示能力的不可微系统,这被认为只有通过神经网络才能实现——>然而,就像其他GMBs(梯度提升机)一样,每个基础学习者都必须在前一个基础学习者之后进行训练,这使得整个系统在并行计算方面效率较低。
软梯度增强机(sGBM)
:是
第一个可以
同时对所有基础学习者进行训练
的可微分梯度增强系统,极大地提高了训练效率。——>sGBM将
多个可微基础学习器连接在一起,并注入了来自梯度提升的局部和全局目标。由于整个结构是可微的,所有基础学习器可以联合优化,与原始的GBM相比,实现
线性加速
。当使用可微决策树作为基础学习器时,这种设备可以被视为(
硬)梯度决策树(GBDT)的替代版本,具有额外的好处,特别是在处理流数据方面。
相关工作:
聚焦于水平联邦学习
梯度提升机
是一种
顺序集成算法
,可用于优化任何可微损失函数。GBM中的基础学习器采用迭代的方式进行拟合,在每次迭代中,拟合一个新的基础学习器,以弥补GBM中拟合基础学习器的输出与ground-truth之间的差距。GBM的整个学习过程是在函数空间中进行梯度下降。
梯度提升决策树是目前应用最广泛的集成算法之一,有效的应用如XGBoost,Light GBM,Cat Boost,实现了出色的预测性能。
提出GBDT也可以用来学习分布式表示,这原本被认为是神经网络的特殊性质。由于GBM中基础学习器是顺序拟合的,最初GMB遭受了巨大的培训成本。此外,它不能直接应用于流数据,因为基础学习器一旦拟合就不能修改。
将GBM扩展到联邦学习框架:Secure Boost是一种开创性的基于树的梯度提升算法,解决了垂直联邦学习问题,可以达到和非联邦版本基于GBM的决策树相同的性能。Secure GBM关注联邦学习中的场景,参与者可能有不同的特性,并且只有一个参与者拥有基本事实。提出了一种新的水平联邦学习梯度提升决策树模型,通过对隐私约束的放松来实现更高的训练效率。——>还没有适用于流数据的GBM联邦工作
相关话题介绍:
①水平联邦学习
②梯度提升机GBM和软梯度提升机sGBM
流数据:
随着数据集容量的快速增长,在传统离线环境下部署学习模型变得越来越困难。
例如:在许多情况下,计算机设备的计算能力和存储空间非常有限。
同时,这些方法不能很好的处理概念漂移。
如:训练数据上的分布变化
关注流数据的算法:可以将处于离线状态的模型与模型重用结合起来处理流数据。可以使用一些在线优化技术的变体直接拟合的模型可以自然地适应流数据,如:深度神经网络。
方法:
①问题设置:
假设协调器可信,利用加密算法;
每个本地数据集都会随着时间而变化。当一个新的本地数据集在时间t上运行时,旧的数据集将立即被丢弃,不再用于训练阶段。
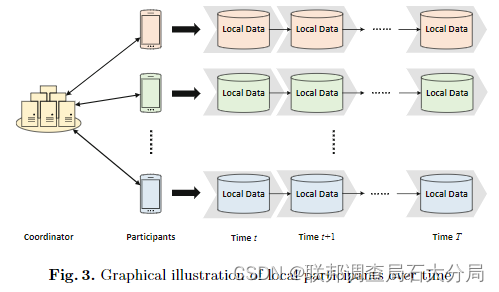
②Fed-sGBM:
GBM
其固有的顺序训练过程,它不能直接应用于上面所示的问题设置:一个基础学习者需要在适应下一个基础学习者之前进行固定。
算法如下:

-
-sGB决策树:
决策树模型,如分类和回归树(CART),被广泛用作梯度提升的基础学习器。最先进的梯度提升决策树(GBDT)库,如XGBoost、LightGBM和CatBoost在各种实际任务中都能实现出色的预测性能。
在sGBDT中使用一个新的软决策树模型,以确保仍然可以使用
反向传播更新整个模型
。
与将每个样本分配给单个叶节点的经典基于树的模型相比,软决策树将每个样本分配给具有不同概率的所有叶节点。为此,软决策树中的每个内部节点都配备了
逻辑回归模型
,该模型将每个样本拆分为具有不同概率的子节点。样本上
整个模型的输出是所有叶节点预测的加权平均值,其中权重对应于分配给每个叶节点的概率
。
由于整个SGBDT模型仍然可以使用在线优化技术(如随机梯度下降)进行训练,因此它能够快速适应流数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









