







朴素贝叶斯法
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
换句话说,在已知条件概率和先验概率的情况下(即,在事件Bi发生条件下发生事件A的概率,和发生事件Bi的概率),求后验概率(即,在事件A发生条件下事件Bi发生的概率)。
先验概率:根据以往经验和分析得到的概率。
后验概率:基于新的信息,修正原来的先验概率后所获得更接近实际情况的概率估计。后验概率是条件概率,但并不是所有的条件概率都是后验概率。
条件概率:在发生A的条件下B发生的概率。
定理:
贝叶斯定理:

其中P=(Y=ck)是先验概率,根据数据集可以求得;P(Y=ck|X=x)是后验概率,也是条件概率,在已知输入的情况下求输出Y=ck的概率;P(X=x|Y=ck)是条件概率,即在Y=ck发生情况下,X=x的概率。
由于上式,分母项都相同,所以求分子项最大即可。

其中,X是特征向量,其有多个维度,即 X={x1,x2,x3...,xn}。假设各个特征取值是相互独立的,可得下式:

算法:
朴素贝叶斯算法

注意:
1.如果在计算条件概率时,一个概率值为0,那么最后的乘积也是0。这会影响后验概率的计算结果,使分类产生偏差。为了降低这种影响,可以采用贝叶斯估计。
具体的公式改动如下,
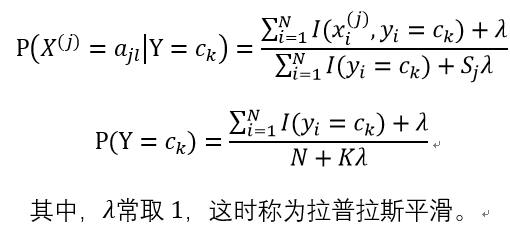
其思想就是,给每种情况初始值加1,使其概率不为0。
2.另外遇到一个问题就是下溢出,这是由于太多很小的数相乘造成的。
这种解决方法是对乘机取自然对数。在代数中,ln(a*b*c)=ln(a)+ln(b)+ln(c)。
所以,
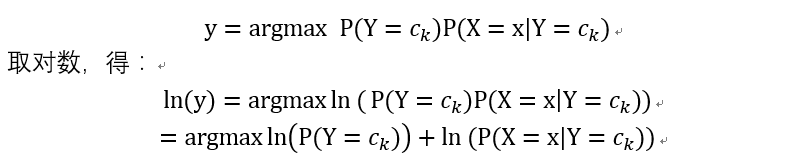
附python源码
#coding: utf-8 or # -*- coding: utf-8 -*-
# author=altman
import numpy as np
import copy as cp
#获得特征向量可能值
def createWordList(data):
wordSet = set([])
for document in data:
wordSet = wordSet | set(document)
return list(wordSet)
#将多维数据转化为一维向量,方便计算
def word2Vec(wordList,inputWord):
returnVec = [0]*len(wordList)
for word in inputWord:
if word in wordList:
returnVec[wordList.index(word)] = 1
return returnVec
#训练函数,根据给定数据和标签,计算概率
def train(trainMatrix,trainLabels):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = (sum(trainLabels)+1.0)/(float(numTrainDocs)+2.0*1.0)
p0Num = np.ones(numWords)
p1Num = np.ones(numWords)
p0Denom = 3.0 + len(trainLabels)-sum(trainLabels)
p1Denom = 3.0 + sum(trainLabels)
for i in range(numTrainDocs):
if trainLabels[i] == 1:
p1Num += trainMatrix[i]
else:
p0Num += trainMatrix[i]
p0Vect = np.log(p0Num/p0Denom)
p1Vect = np.log(p1Num/p1Denom)
return p0Vect,p1Vect,pAbusive
#分类函数
def classify(vec2Clssify,p0Vect,p1Vect,pClass1):
p1 = sum(vec2Clssify*p1Vect) + np.log(pClass1)
p0 = sum(vec2Clssify*p0Vect) + np.log(1-pClass1)
if p1>p0:
return 1
else:
return 0
def main():
data = [[1,'s'],[1,'m'],[1,'m'],[1,'s'],[1,'s'],[2,'s'],[2,'m'],[2,'m'],[2,'l'],[2,'l'],[3,'l'],[3,'m'],[3,'m'],[3,'l'],[3,'l']]
labels = [0,0,1,1,0,0,0,1,1,1,1,1,1,1,0]
wordList = createWordList(data)
dataMatrix = []
for item in data:
dataMatrix.append(word2Vec(wordList,item))
p0,p1,pAB = train(dataMatrix,labels)
goal = [3,'l']
wordVec = np.array(word2Vec(wordList,goal))
print(classify(wordVec,p0,p1,pAB))
if __name__ == '__main__':
main()















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









