







学习2-3篇论文:
① Adversarial Learning for Semi-Supervised Semantic Segmentation 下载
② Semantic Segmentation using Adversarial Networks 下载
③ Semi-Supervised Semantic Segmentation With High- and Low-Level Consistency
Adversarial Learning for Semi-Supervised Semantic Segmentation
1.1 introduction
在这项工作中,作者结合了两个半监督损失项来利用未标记的数据。首先,利用鉴别器网络生成的置信图作为监控信号,以自学的方式引导交叉熵损失。置信度图指示预测分布的哪些区域接近地面真相标签分布,从而这些预测可以通过掩蔽的交叉熵损失被分割网络信任和训练。其次,将对抗性损失应用于监督设置中采用的未标记数据,这鼓励模型预测接近地面真实分布的未标记的数据的分割输出。
这项工作的贡献总结如下。首先,开发了一个对抗性框架,该框架可以提高语义分割的准确性,而不需要在推理过程中额外的计算负载。其次,提出了一个半监督框架,并表明通过添加图像而无需任何注释,可以进一步提高分割精度。第三,作者通过利用未标记图像的鉴别器网络响应来发现有助于分割训练过程的可信区域,从而促进半监督学习。在PASCAL VOC 2012和Cityscape数据集上的实验结果验证了所提出的对抗性框架用于半监督语义分割的有效性。
1.2 算法概述
个人理解:分割网络作为生成器,后面的卷积网络作为鉴别器,先说有监督的影像,首先经过分割网络,这里的输出和真实标签计算损失(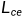 ),分割网络的输出的结果或者原真实标签作为鉴别器的输入,让鉴别器进行判定,最小化该损失(
),分割网络的输出的结果或者原真实标签作为鉴别器的输入,让鉴别器进行判定,最小化该损失(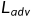 ),以达到使分割结果和真值尽可能有相同的分布。再说无标签的影像,对于无标签影像,首先是没有监督的,也就是没有,先经过分割网络,再将分割结果输入鉴别器中,此时,必然也有一个,但是这里的给一个更小一点的权重系数,防止过度矫正,由于经过鉴别器之后,会生成一个置信图,以这个置信图为基准,找到置信度较高的区域,以此分割结果作为无标签影像的标签。
),以达到使分割结果和真值尽可能有相同的分布。再说无标签的影像,对于无标签影像,首先是没有监督的,也就是没有,先经过分割网络,再将分割结果输入鉴别器中,此时,必然也有一个,但是这里的给一个更小一点的权重系数,防止过度矫正,由于经过鉴别器之后,会生成一个置信图,以这个置信图为基准,找到置信度较高的区域,以此分割结果作为无标签影像的标签。
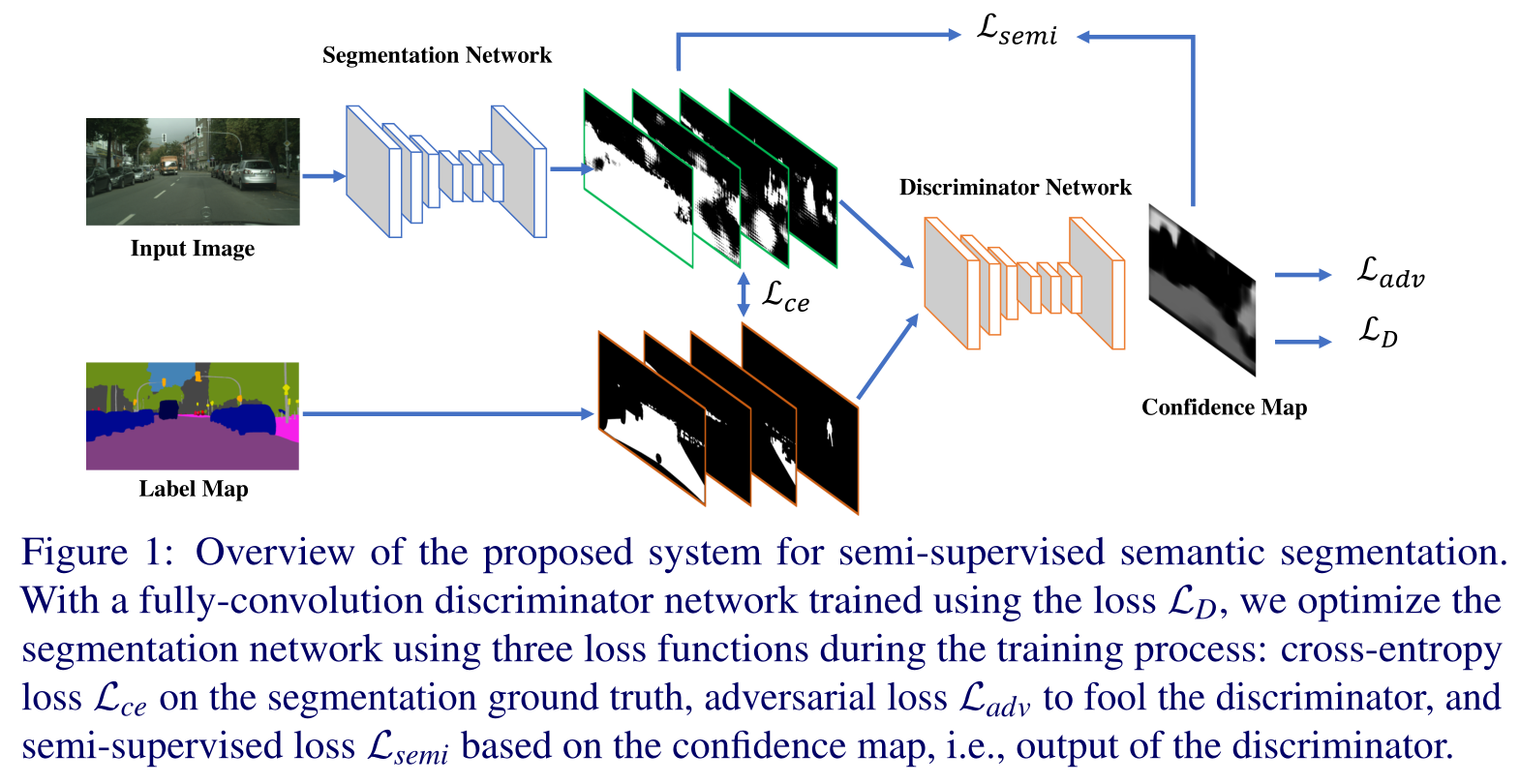
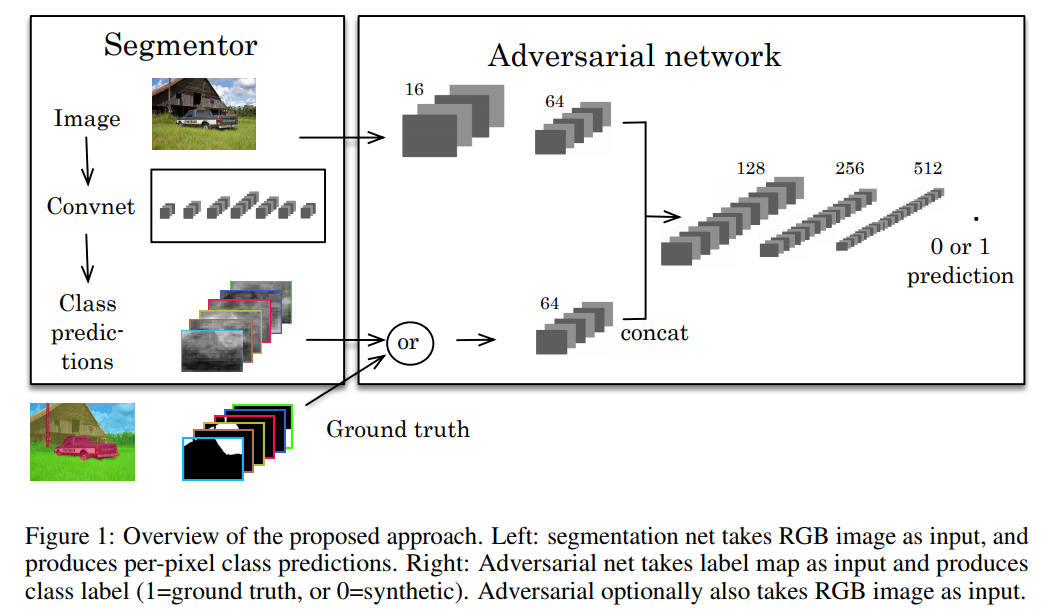
图1显示了所提出算法的概述。该模型由两个模块组成:分割和鉴别器网络。前者可以是为语义分割而设计的任何网络,例如FCN、DeepLab和DilatedNet。给定维数为H×W×3的输入图像,分割网络输出大小为H×W×C的类概率图,其中C是语义类别的数量。
作者的鉴别器网络基于一个FCN,该网络将类概率图作为输入,无论是来自分割网络还是地面真值标签图,然后输出大小为H×W×1的空间概率图。鉴别器输出图的每个像素p表示该像素是从地面真值标签(p=1)还是从分割网络(p=0)采样的。与采用固定大小输入图像(大多数情况下为64×64)并输出单个概率值的典型GAN鉴别器不同,作者将鉴别器转换为可采用任意大小输入的全卷积网络。更重要的是,作者表明这种转换对于所提出的对抗性学习方案至关重要。
在训练过程中,作者在半监督设置下使用标记图像和未标记图像。当使用标记数据时,分割网络由具有地面真值标记图的标准交叉熵损失Lce和具有鉴别器网络的对抗性损失Ladv来监督。注意,作者仅使用标记的数据训练鉴别器网络。对于未标记的数据,作者使用所提出的半监督方法训练分割网络。在从分割网络获得未标记图像的初始分割预测之后,作者通过将分割预测传递给鉴别器网络来计算置信图。作者反过来将该置信图作为监控信号,使用自学方案来训练具有掩蔽交叉熵损失Lsemi的分割网络。该置信图指示预测的分割区域的质量,使得分割网络可以在训练期间信任。
1.3 损失函数
鉴别器网络
为了训练鉴别器网络,使用以下方法最小化两类的空间交叉熵损失LD:
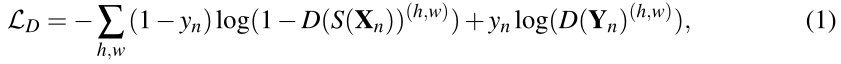
其中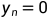 是从指样本是由分割网络中提取的,
是从指样本是由分割网络中提取的,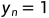 是指样本从GT标签中提取的。另外,
是指样本从GT标签中提取的。另外,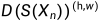 是X在位置(h,w)的置信度图,并且
是X在位置(h,w)的置信度图,并且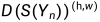 的定义与此类似。为了将带有离散标签的GT标签图转换为C通道概率图,作者将GT标签图使用单热编码方案,其中如果像素
的定义与此类似。为了将带有离散标签的GT标签图转换为C通道概率图,作者将GT标签图使用单热编码方案,其中如果像素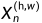 属于C类别,则
属于C类别,则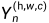 取值为1,否则为0。
取值为1,否则为0。
鉴别器网络的一个潜在性的问题就是:它可以通过检测one-hot概率来区别出概率图是否来自GT图。但是在训练阶段不会出现此问题,因为作者使用全卷积方法来预测空间置信度,这增加了学习判别器的难度。
分割网络
作者通过最小化多任务损失函数来训练分割网络:
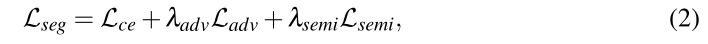
其中,Lce、Ladv和Lsemi分别表示空间多类交叉熵损失、对抗性损失和半监督损失。在(2)中,λadv和λsemi是最小化所提出的多任务损失函数的两个权重。交叉熵损失不用过多赘述,下面重点说一下剩下两个损失。
作者通过给定完全卷积鉴别器网络D(·)的损失Ladv使用对抗性学习过程
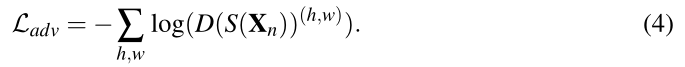
有了这种损失,就能最大程度地从GT分布生成预测结果的概率来训练分割网络,以欺骗鉴别器。
利用未标记的数据进行训练
在这项工作中,我们考虑了半监督环境下的对抗性训练。对于未标记的数据,我们不应用Lce,因为没有地面真实注释。对抗性损失Ladv仍然适用,因为它只需要鉴别器网络。然而,我们发现,选择比用于标记数据的λadv更小的λ是非常重要的。这是因为对抗性损失可能会过度校正预测以适合地面真实分布而没有交叉熵损失。
此外,我们在自学框架内使用经过训练的鉴别器和未标记的数据。主要思想是,经过训练的鉴别器可以生成置信度图D(S(Xn)),该置信度图可以用于推断与地面真值分布足够接近的区域。然后,我们将该置信图与阈值进行二值化,以突出显示可信区域。此外,如果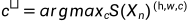 ,那么
,那么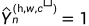 ,由此产生的半监督损失定义如下:
,由此产生的半监督损失定义如下:
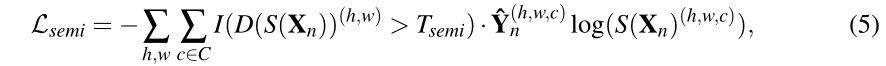
其中I(·)是指示函数,Tsemi是控制自学过程灵敏度的阈值。注意,在训练过程中,我们将自学目标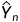 和指标函数的值视为常数,因此(5)可以简单地视为掩膜的空间交叉熵损失。在实践中,我们发现这种策略在Tsemi介于0.1和0.3之间时运行良好。
和指标函数的值视为常数,因此(5)可以简单地视为掩膜的空间交叉熵损失。在实践中,我们发现这种策略在Tsemi介于0.1和0.3之间时运行良好。
参考链接:https://www.jianshu.com/p/c6d019f5fc3b
Semantic Segmentation using Adversarial Networks
这篇文章是第一次将GAN网络应用到语义分割领域。
这篇文章的主要解读来自于另一位博主的文章:使用对抗网络进行语义分割


3. Semi-Supervised Semantic Segmentation With High- and Low-Level Consistency
一个写的挺好的博主,部分内容源自:论文解读
在introduction中,作者提到,本文网络的设计基于这样的观察:在有限的数据上训练的神经网络受到两种典型的故障模式的影响;见图1c和1d。第一种表现为低级细节的不准确,例如错误的物体形状、不准确的边界和不连贯的表面。第二种是对高级信息的误解,这导致将大图像区域分配给错误的类。

在这项工作中,作者提出了一种半监督语义分割的双分支方法,该方法可以有效地从给定非常小的一组完全注释样本的无注释样本中学习。网络如图3所示。上分支预测逐像素类标签,并称为半监督语义分割GAN(s4GAN)。下分支执行图像级分类,并被表示为多标签均值教师(MLMT)。
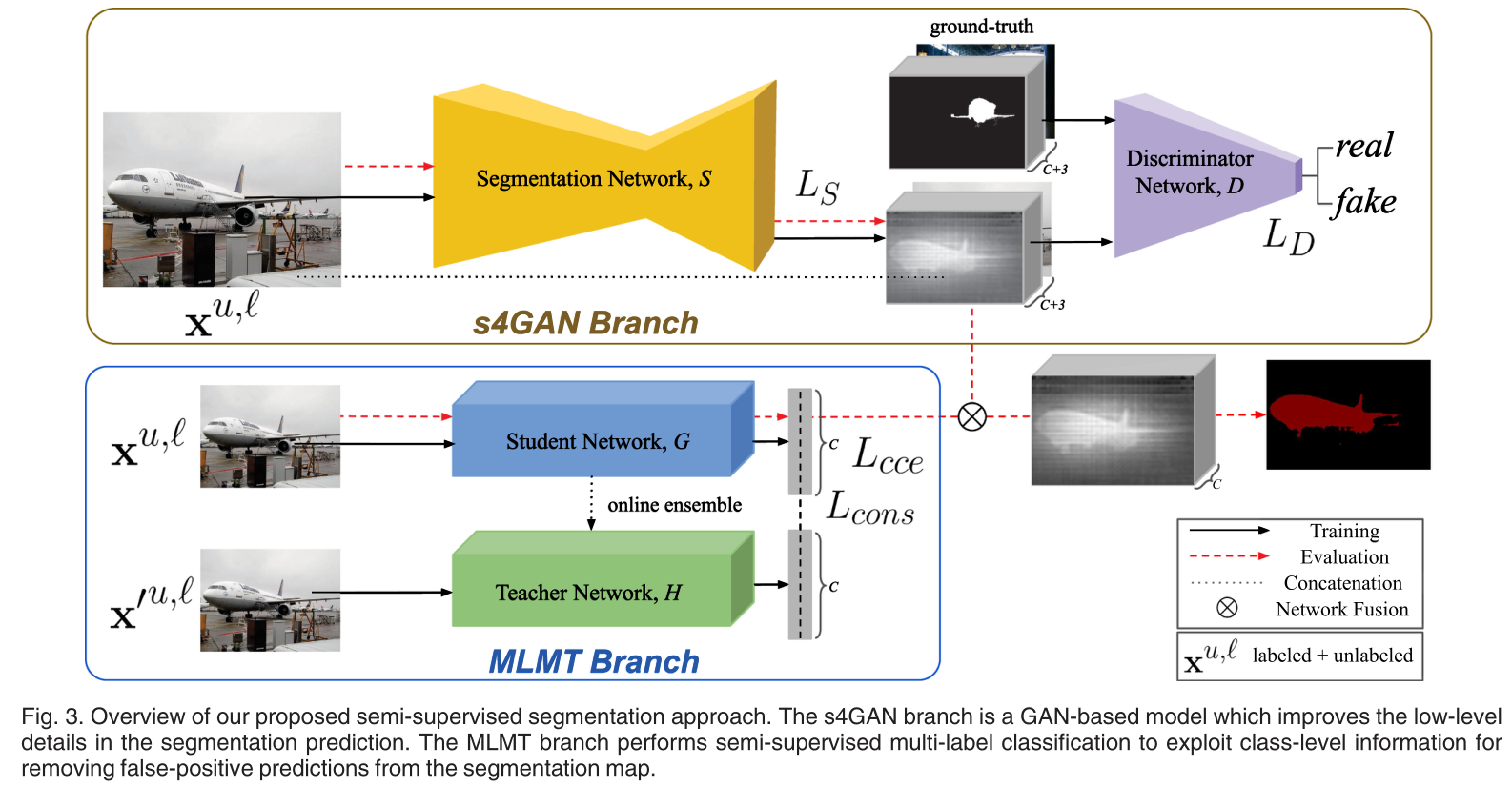
s4GAN分支的核心是一个标准分割网络,用于在给定输入图像的情况下生成每像素类标签。作者将传统的监督训练与对抗性训练相结合,这允许利用未标记的数据来提高预测质量。分割网络充当生成器,并与鉴别器一起训练,鉴别器负责将地面真相分割图与生成的地图区分开来。此外,作者还将鉴别器的输出作为质量度量,并使用它来识别最佳预测,这些预测将进一步用于自我训练。
MLMT分支预测用于过滤s4GAN输出的图像级类标签。它的核心是mean-teacher分类器,它有效地去除了分割网络的假阳性预测。这两个分支的贡献是相辅相成的。它们的输出被合并以产生最终结果。
自己的理解:s4GAN其实是主要的分割网络,segmentation作为生成器G,discrimination作为鉴别器D,加起来就是一个GAN网络,首先输入图像经过G网络之后,输出预测结果(C个通道),将这个结果与原图进行拼接,通道数变为(C+3),将其输入到鉴别器D网络中。第二个分支MLMT就起到一个mask的作用,但这里不是0、1的mask,而是权重,对于输入图像中,不存在的类别赋予一个很小的权重。
3.1 s4GAN for Semantic Segmentation
在作者的s4GAN模型中,分割网络S充当一个生成器网络,它将图像x作为输入并预测C个分割图,每个类一个通道。鉴别器D将原始图像与预测结果的级联作为输入。其任务是匹配预测的和真实的分割图的分布统计。
3.1.1 Training S
分割网络S使用损失LS进行训练,损失LS是三种损失的组合:标准交叉熵损失、特征匹配损失和自训练损失。
交叉熵损失。对有监督的数据的损失。这是一个标准的监督像素交叉熵损失项Lce。
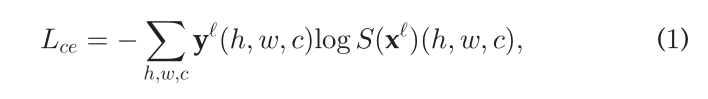
Feature matching loss
为了使得分割结果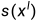 和标签
和标签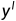 的特征分布尽可能一致,本文计算分割结果和标签的特征分布差异mean discrepancy,并设计Feature matching loss
的特征分布尽可能一致,本文计算分割结果和标签的特征分布差异mean discrepancy,并设计Feature matching loss
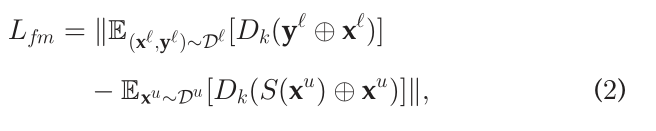
其中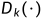 是第k层之后鉴别器网络的中间表示。地面真值和预测分割掩模都与其对应的输入图像连接。直观地,它鼓励生成器预测具有与地面真相相同的特征统计信息的分割地图,因此在质量上也与地面真相相似。这种损失被用于未标记的样本
是第k层之后鉴别器网络的中间表示。地面真值和预测分割掩模都与其对应的输入图像连接。直观地,它鼓励生成器预测具有与地面真相相同的特征统计信息的分割地图,因此在质量上也与地面真相相似。这种损失被用于未标记的样本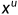 ,因此即使在密集标签不可用的情况下,也强制采用合理的解决方案。
,因此即使在密集标签不可用的情况下,也强制采用合理的解决方案。
自我训练损失。在GAN训练期间,需要平衡鉴别器(D)和生成器(G)网络。如果D开始时太强,它不会为G提供任何有用的学习信号。为了促进这种平衡的动力学,作者引入了自训练(ST)损失。其主要思想是选择最好的生成器输出(即那些能够愚弄D的输出),这些输出不具有相应的基本事实,并将它们重新用于监督训练。直觉上,这促使G产生了D无法与真实预测区分的预测。这阻碍了D的进步,不允许它变得太强。
从技术上讲,D的输出在0和1之间变化,其中0应分配给预测的分割图,1应分配给地面真相分割图。作者使用该分数作为预测分割质量的置信度度量。高质量预测用于监督训练,即,作者基于它们计算标准交叉熵损失。因此,自训练损失项Lst被定义为
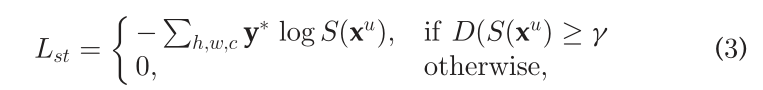
最终训练目标LS由三个描述的术语组成
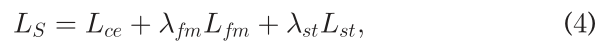
3.1.2训练discriminator
discriminator的输入包含原图image和对应标签,训练discriminator,希望discriminator能给真实标签打高分,给fake label打低分。具体损失函数和传统的GAN相同。
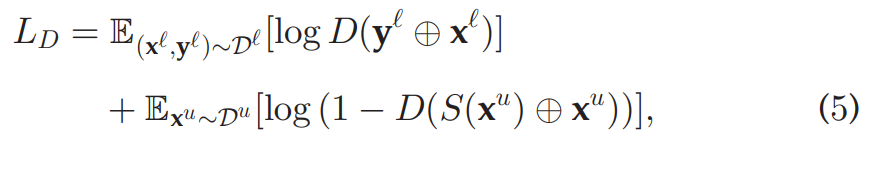
3.2 Multi-Label Semi-Supervised Classification
作者将基于集成的半监督分类方法(Mean Teacher)扩展到半监督多标签图像分类。该模型由两个网络组成:学生网络G和教师网络H。两个网络在不同的小扰动下接收相同的图像。教师网络的权重是学生网络权重的指数移动平均值。使用一致性损失,即两个预测之间的均方误差,鼓励学生模型做出的预测与教师模型的预测一致。
作者使用标记样本x’的分类交叉熵损失Lcce和所有可用样本的一致性损失Lcons来优化学生网络
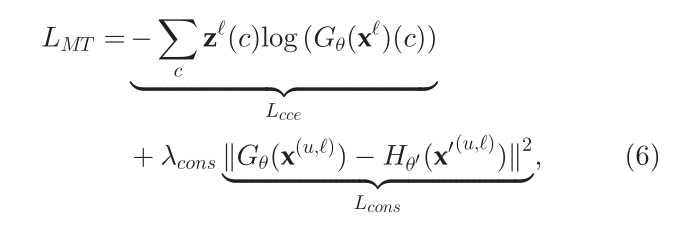
3.3 网络融合
上述两个分支分别进行训练。为了进行评估,分类分支的输出只需停用输入图像中不存在的那些类的分割图(就是设置一个阈值,用于去掉输入图像中没有的类就行)
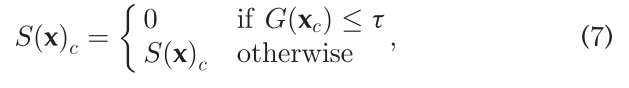















 6844
6844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









