






论文解读《带有交叉伪监督的半监督式语义分割法》
论文出处:CVPR2021
论文地址:论文地址
代码地址:代码地址
一 摘要:
(1) 本文通过研究有标签数据和无标签数据,研究了半监督语义分割问题。提出了一种新的一致性规则化方法——交叉伪监督(CPS)。
(2) 该方法将一致性强加于对同一输入图像进行不同初始化扰动的两个分割网络上。
(3) 实验结果表明,方法是有效的在cityscape和PASCAL VOC 2012上实现了最先进的半监督分割性能。
二 引言 :图像语义分割是计算机视觉中的一项基本识别任务。语义分割训练数据需要像素级的手动标记,这比其他视觉任务要昂贵得多,如图像分类和目标检测。这使得半监督分割成为一个重要问题通过使用标记数据和附加的未标记数据来学习分割模型。一致性正则化在半监督语义分割中得到了广泛的研究。它通过增加输入图像[11,19]、特征摄动[27]和网络摄动[18]来加强预测的一致性。自我训练也被用于半监督分割[6,43,42,9,13,25]。该方法对经过标记图像训练的分割模型得到的未标记图像进行伪分割映射,对训练数据进行扩展,并对分割模型进行再训练。
(1) 一种网络扰动一致性正则化方法,交叉伪监督。标记数据集上的输出分别由相应的分割标准图进行监督训练。
(2) 这两个网络在标记数据上的输出分别由相应的标准真实分割图监督。我们的主要观点在于交叉伪监督,它强制两个分割网络之间的一致性。每个输入图像的分割网络估计一个分割结果,称为伪分割图。伪分割图被用作监督其他分割网络的额外信号。
(3) 在cityscape和PASCAL VOC 2012两个基准上进行不同设置的实验结果表明提出的交叉伪监督分割方法优于现有的一致性半监督分割方法。我们的方法在两个基准上都实现了最先进的半监督分割性能。
三 相关工作:
3.1 语义分割 现代深度学习的语义分割方法大多基于全卷积网络(FCN)[23]。后续的研究主要从三个方面对模型进行了研究:
分辨率、上下文和边缘。提高分辨率的工作包括调解在分类网络,例如,使用编码器-解码器方案[5]或扩展卷积[36,4],并保持高分辨率,如HRNet[34,30]。
对语境的利用包括空间语境,如PSPNet[41]和ASPP[4],对象上下文[38,37],和自我注意的应用[33]。改善边缘区域分割质量的方法包括gate - scnn [31],PointRend[20]和SegFix[39]。本文主要研究了如何利用无标签数据,进行了实验研究使用DeepLabv3+,并在HRNet上报告结果。
3.2 半监督语义分割 人工像素级注释用于语义分割非常耗时和昂贵。对现有的无标记图像进行研究,有助于学习分割模型。一致性正则化在半监督分割中得到了广泛的研究。它在各种扰动下加强了预测/中间特征的一致性。
(1) 输入摄动法[11,19]对输入图像进行随机增广,并对增广图像的预测之间施加一致性约束,使决策函数位于低密度区域。
(2) 特征摄动提出了一种使用多个解码器的特征摄动方案,实现了解码器[27]输出之间的一致性。
(3) GCT[17]通过使用两个结构相同但初始化不同的分割网络进一步进行网络扰动,并加强扰动网络预测之间的一致性。论文方法不同于GCT,通过使用伪分割图来加强一致性,并具有扩展训练数据等额外好处。
(4) 除了加强一个图像的各种扰动之间的一致性,基于gan的方法[25]加强标记数据的标准分割映射和未标记数据的预测分割映射的统计特征之间的一致性。统计特征从鉴别器网络中提取,该鉴别器网络被用来区分标准真实分割和预测分割。
(5) 自我训练,又称自我学习、自我标记或决策导向学习,最初是为了在分类中使用未标记的数据而发展起来的[15,10,1,3,22]。最近它被应用于半监督分割[6,43,42,9,13,25,14,24]。它将从先前对标记数据进行训练的分割模型中获得的未标记数据合并为伪分割映射,用于对分割模型进行再训练。这个过程可以重复几次。
(6) 伪分割方案 基于GAN的方法[13,25,29]使用学习到的鉴别器来区分预测和标准真实分割,选择对未标记图像的高置信分割预测作为伪分割。与我们的工作并行的PseudoSeg[44]也探索了半监督分割的伪分割。与我们的方法至少有两个不同之处。
PseudoSeg遵循FixMatch方案[28],通过使用弱增强图像的伪分割来监督基于单一分割网络的强增强图像的分割。该方法采用具有相同输入图像的两个相同且独立初始化的分割网络,并使用每个网络的伪分割映射来监督另一个网络。另一方面,我们的方法在两个分割网络上都进行反向传播,而PseudoSeg只对强增强图像进行反向传播。
四、方法介绍:
Dl (N个标记图像)和一组Du (M个未标记图像)。
4.1 交叉伪监督
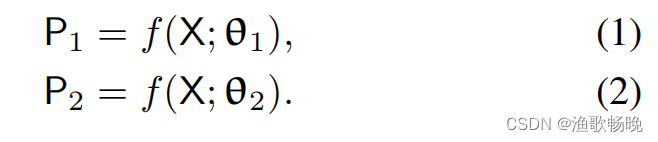
X→X( same augmentation)
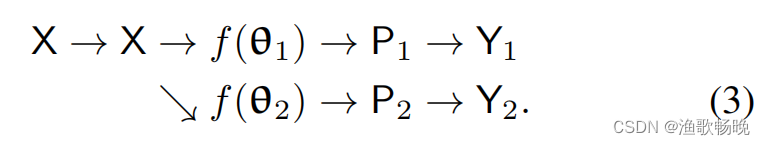
注:用f(θ)表示f(X;θ)为了方便,去掉X。
Network(
(branch1): SingleNetwork(
(backbone): ResNet(
...
)
(head): Head(
###空洞空间卷积池化金字塔(atrous spatial pyramid pooling (ASPP))对所给定的输入以不同采样率的空洞卷积并行采样。结合了空洞卷积可在不丢失分辨率(不进行下采样)的情况下扩大卷积核的感受野
(aspp): ASPP(
(map_convs): ModuleList(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6), bias=False)
(2): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(12, 12), dilation=(12, 12), bias=False)
(3): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(18, 18), dilation=(18, 18), bias=False)
)
(map_bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(global_pooling_conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(global_pooling_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(red_conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool_red_conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(red_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(leak_relu): LeakyReLU(negative_slope=0.01)
)
(reduce): Sequential(
(0): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(last_conv): Sequential(
(0): Conv2d(304, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(criterion): CrossEntropyLoss()
(classifier): Conv2d(256, 40, kernel_size=(1, 1), stride=(1, 1))
)
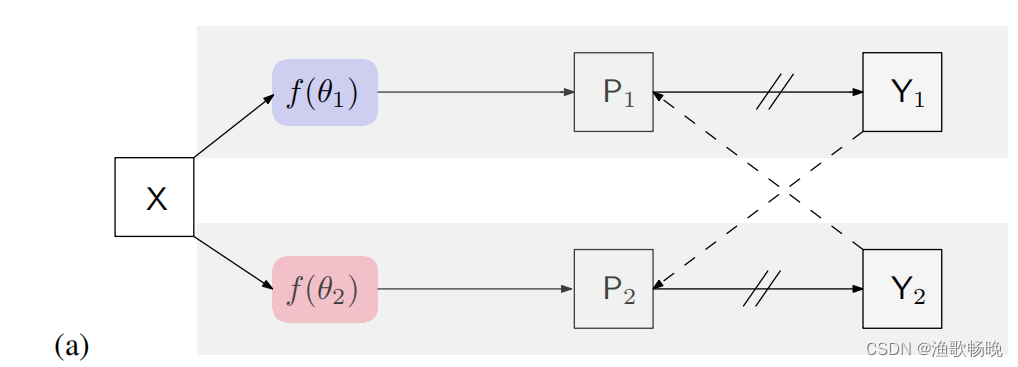
注:‘→’表示前向操作,’ 虚线箭头 ‘表示损失监督。’ // ’ 在 '→’中表示停止梯度计算。
(1) 监督损失Ls
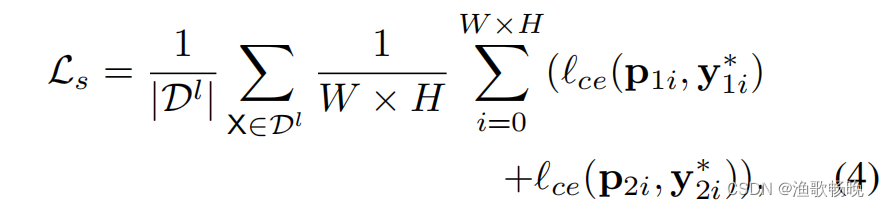
其中ce是交叉熵损失函数,y∗1i(y∗2i)是标准标签(ground truth)。W和H表示输入图像的宽度和高度。
(2) 无标签数据的交叉伪监督损失Lucps
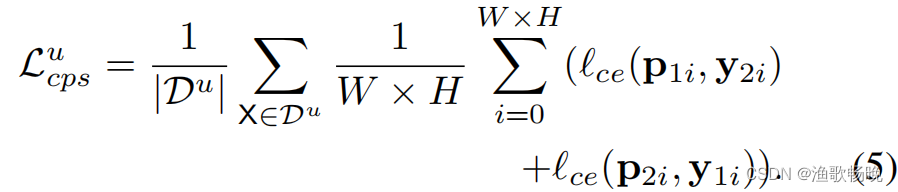
交叉伪监督损失Lcps
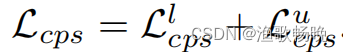
整个训练目标损失函数
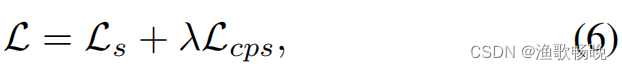
λ是权衡权重。
criterion = ProbOhemCrossEntropy2d(ignore_label=255, thresh=0.7,
min_kept=pixel_num, use_weight=False)
criterion_cps = nn.CrossEntropyLoss(reduction='mean', ignore_index=255)
imgs = minibatch['data']
unsup_imgs_0 = unsup_minibatch_0['data']
unsup_imgs_1 = unsup_minibatch_1['data']
mask_params = unsup_minibatch_0['mask_params']
# supervised loss on both models
sup_pred_l = model(imgs, step=1)
sup_pred_r = model(imgs, step=2)
with torch.no_grad():
# Estimate the pseudo-label with branch#1 & supervise branch#2
_, logits_u0_tea_1 = model(unsup_imgs_0, step=1)
_, logits_u1_tea_1 = model(unsup_imgs_1, step=1)
logits_u0_tea_1 = logits_u0_tea_1.detach()
logits_u1_tea_1 = logits_u1_tea_1.detach()
# Estimate the pseudo-label with branch#2 & supervise branch#1
_, logits_u0_tea_2 = model(unsup_imgs_0, step=2)
_, logits_u1_tea_2 = model(unsup_imgs_1, step=2)
logits_u0_tea_2 = logits_u0_tea_2.detach()
logits_u1_tea_2 = logits_u1_tea_2.detach()
#######################################################################################
#######################################################################################
pred_sup_l = model(imgs, step=1)
pred_unsup_l = model(unsup_imgs, step=1)
pred_sup_r = model(imgs, step=2)
pred_unsup_r = model(unsup_imgs, step=2)
### cps loss ###
pred_l = torch.cat([pred_sup_l, pred_unsup_l], dim=0)
pred_r = torch.cat([pred_sup_r, pred_unsup_r], dim=0)
max_l = torch.max(pred_l, dim=1)
max_r = torch.max(pred_r, dim=1)
max_l = max_l.long()
max_r = max_r.long()
cps_loss = criterion(pred_l, max_r) + criterion(pred_r, max_l)
########################################################################################
# supervised loss on both models
gts = minibatch['label']
sup_pred_r = model(imgs, step=2)
loss_sup_r = criterion(sup_pred_r, gts)
#######################################################################################
sup_pred_l = model(imgs, step=1)
loss_sup_l = criterion(sup_pred_l, gts)
loss = loss_sup_l + loss_sup_r + cps_loss
4.2 与CutMix增强的合并
将CutMix增强方案[40]应用于mean teacher框架,进行半监督分割[11]。
CutMix介绍链接:CutMix
注:CutMix就是将CutOut和Mixup结合。原理图如下:右图可知,CutMix相比于Cutout就是将区域删除操作变成截取另外一张图片一样大小的区域填充该区域,同时改变新图片的标签。

mixup将两张图片进行全图软融合,同时也将两张图片的标签进行软融合,因而利用了全图的信息。cutout仅仅对图片进行drop,因而无法利用全图信息,当然不会改变label。而cutmix则是对两张图片进行硬融合,并且采用了mixup的label软融合策略。这样的处理,使得CutMix不会改变整个数据集的分布。
五、讨论
讨论了我们的方法与几个相关工作的关系如下。
5.1 交叉概率一致性(Cross probability consistency)
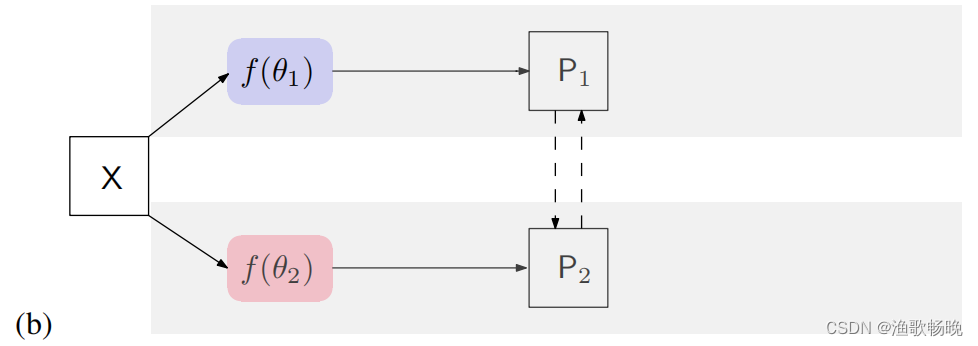
注:置信向量p1 (p2)
( 如图1 (b)所示 )。损失函数为:
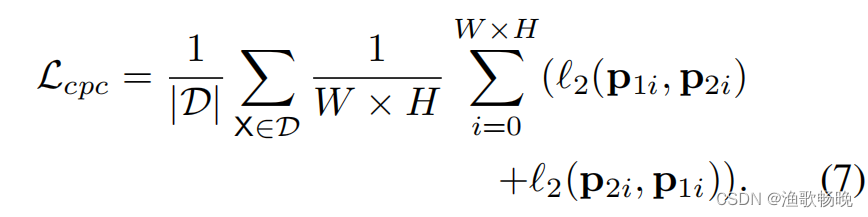
示例loss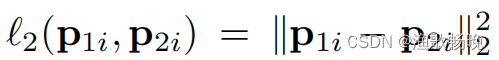
用D表示标记集Dl和未标记集Du的并集
5.2 Mean teacher
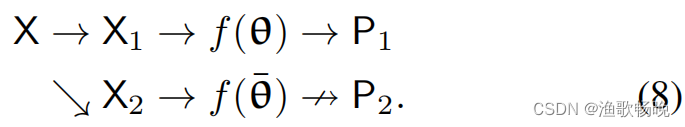
注:一个是学生f(θ),另一个是平均老师(Mean teacher) f(θ¯)
在图中,用
表示“无反向传播”。
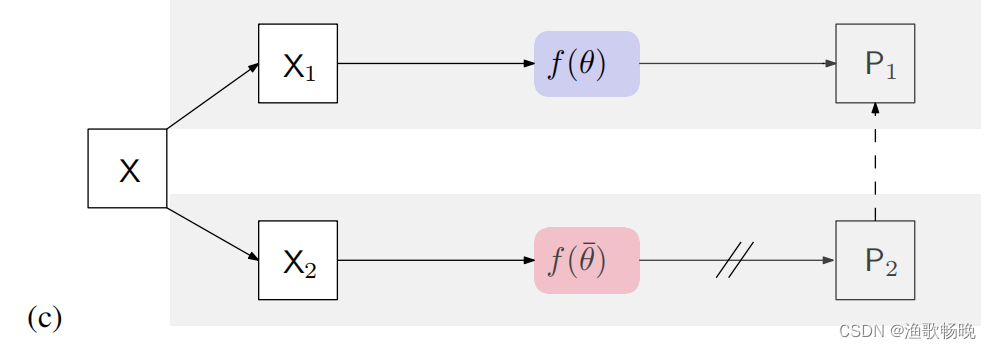

5.3 单独的网络伪监督(Single-network pseudo supervision)
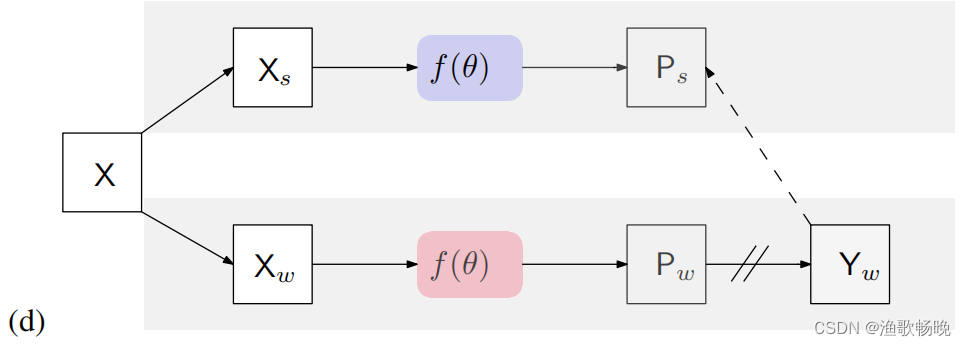
六 实验
6.1数据集
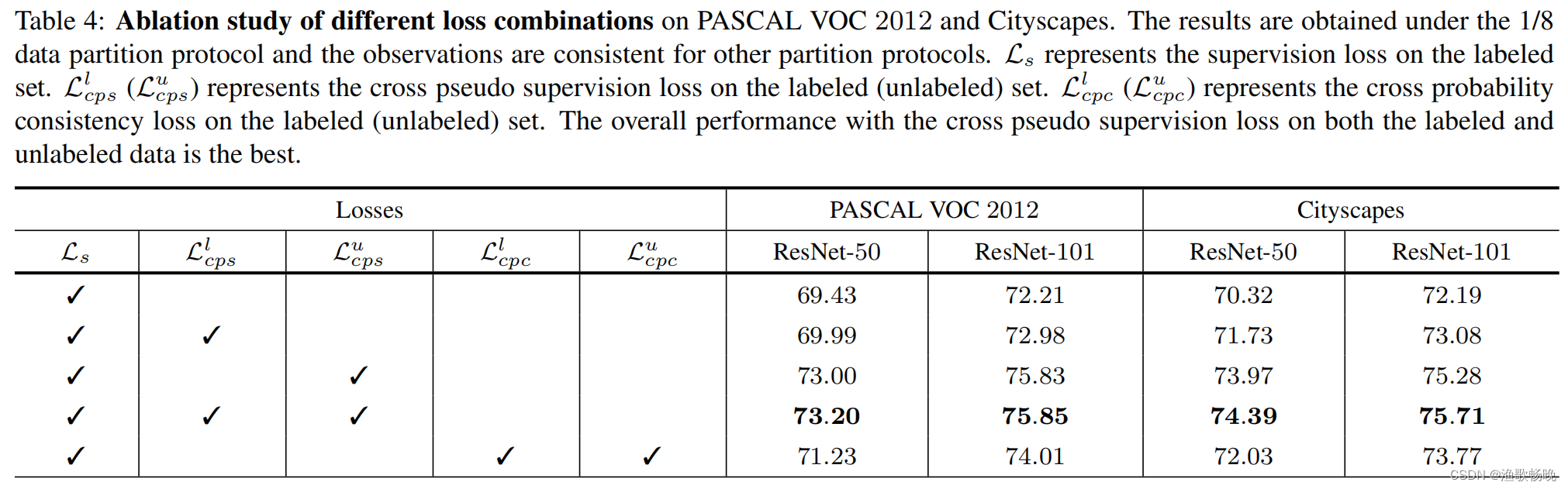
PASCAL VOC 2012是一个标准的以对象为中心的语义分割数据集,它由超过13000张图像组成,包含20个对象类和1个背景类。标准的训练集、验证集和测试集分别由1464、1449和1456张图像组成。我们遵循之前的工作,使用增强集(10,582张图像)作为完整的训练集。[7]主要用于城市场景的理解。官方划分有2975张图像用于训练,500张用于验证,1525张用于测试。每个图像的分辨率为2048 × 1024,并由19个语义类的像素级别标签进行精细标注。遵循GCT[17]的划分协议,通过随机子采样整个训练集的1/2、1/4、1/8和1/16将整个训练集划分为两组,将其余图像作为无标签集。
6.2 评估
我们使用平均交并比(mIoU)度量来评估分割性能。对于所有分区协议,我们仅通过单尺度测试报告了1456 PASCAL VOC 2012 val集(或500 Cityscapes val集)的结果。在方法中,只使用一个网络来生成评估的结果。
6.3 实现细节
我们基于PyTorch框架实现了我们的方法。我们使用在ImageNet上预训练的相同权重和两个(DeepLabv3+)分割头的权重随机初始化两个分割网络中的两个主干的权重。采用带动量的小批量SGD方法,使用Sync-BN[16]训练模型。动量被固定为0.9,权重衰减被设置为0.0005。我们采用多学习率策略,其中初始学习率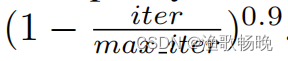
对于在整个训练集上训练的监督基线,如果未指定,则使用随机水平翻转和多尺度作为数据增强。我们对PASCAL VOC 2012进行了60个epoch的训练,基本学习率设置为0.01,并对Cityscapes进行了240个epoch的训练,基本学习率设置为0.04。OHEM loss用于城市景观。
七 结果分析
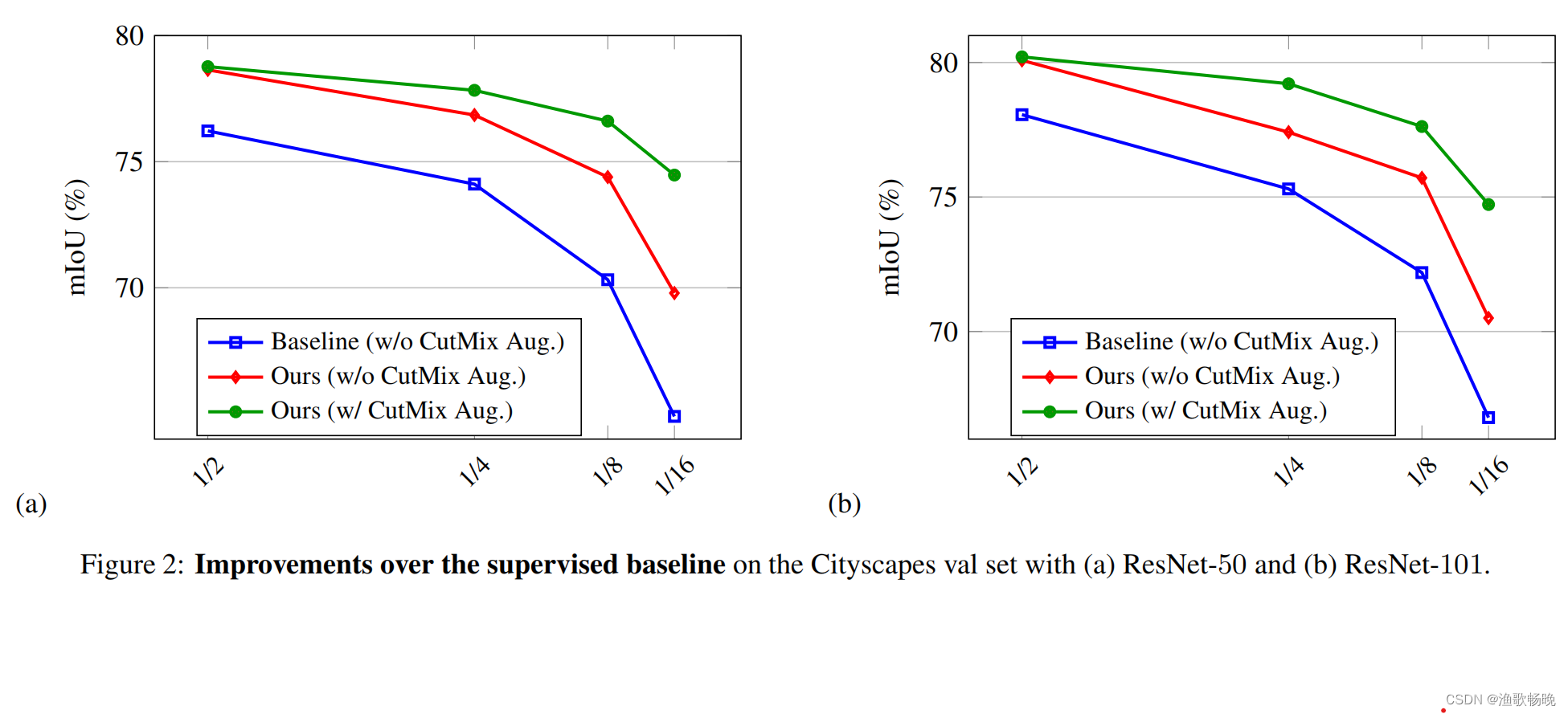
7.1 基于baseline的提升
带有ResNet-50或ResNet-101骨干网络
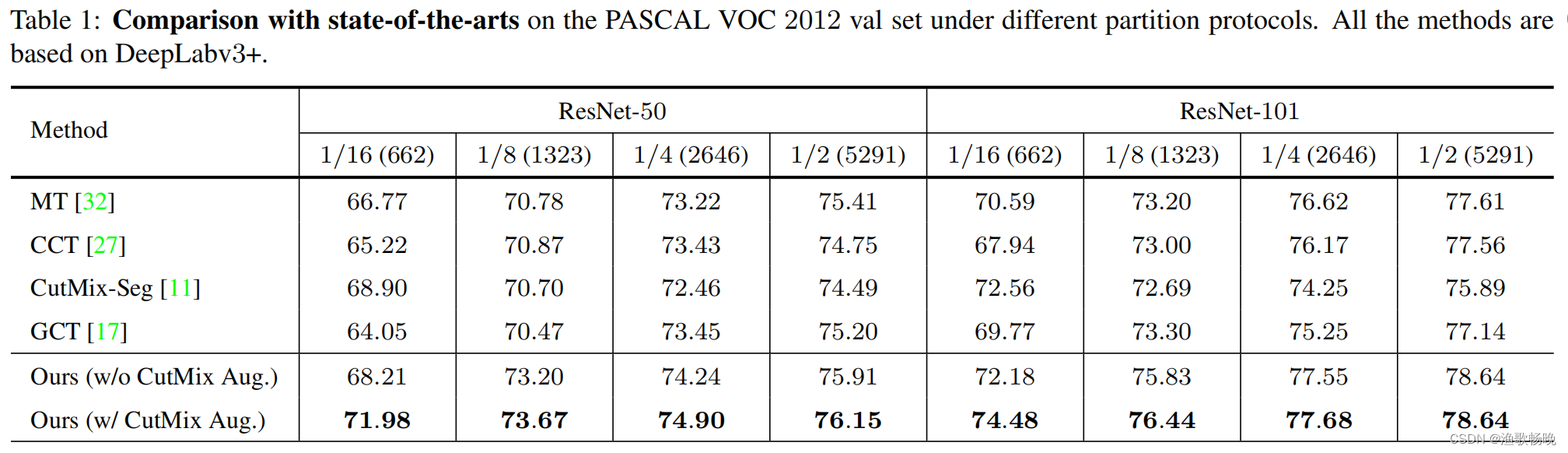
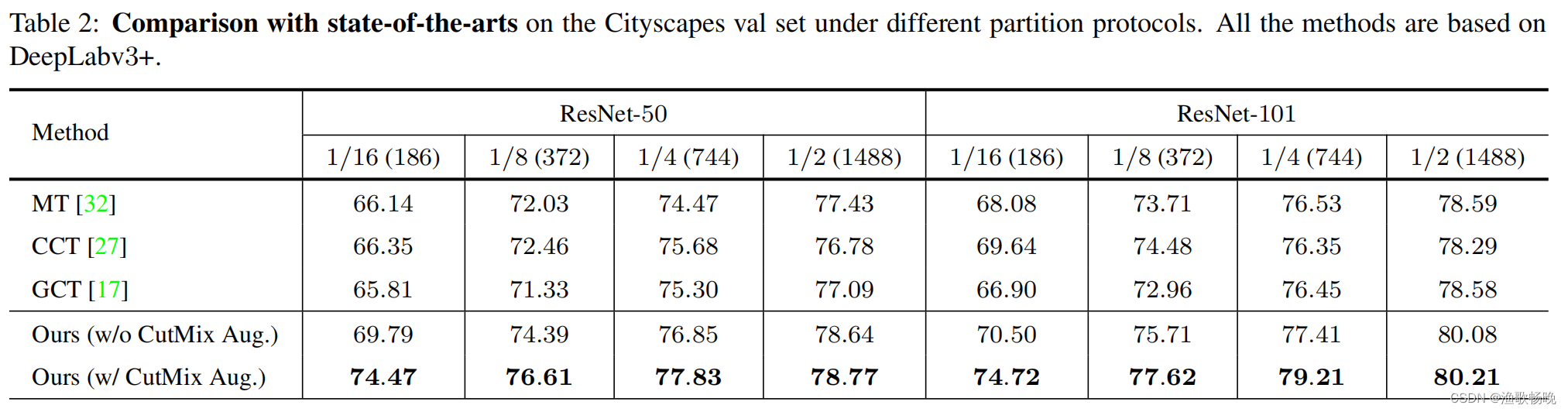
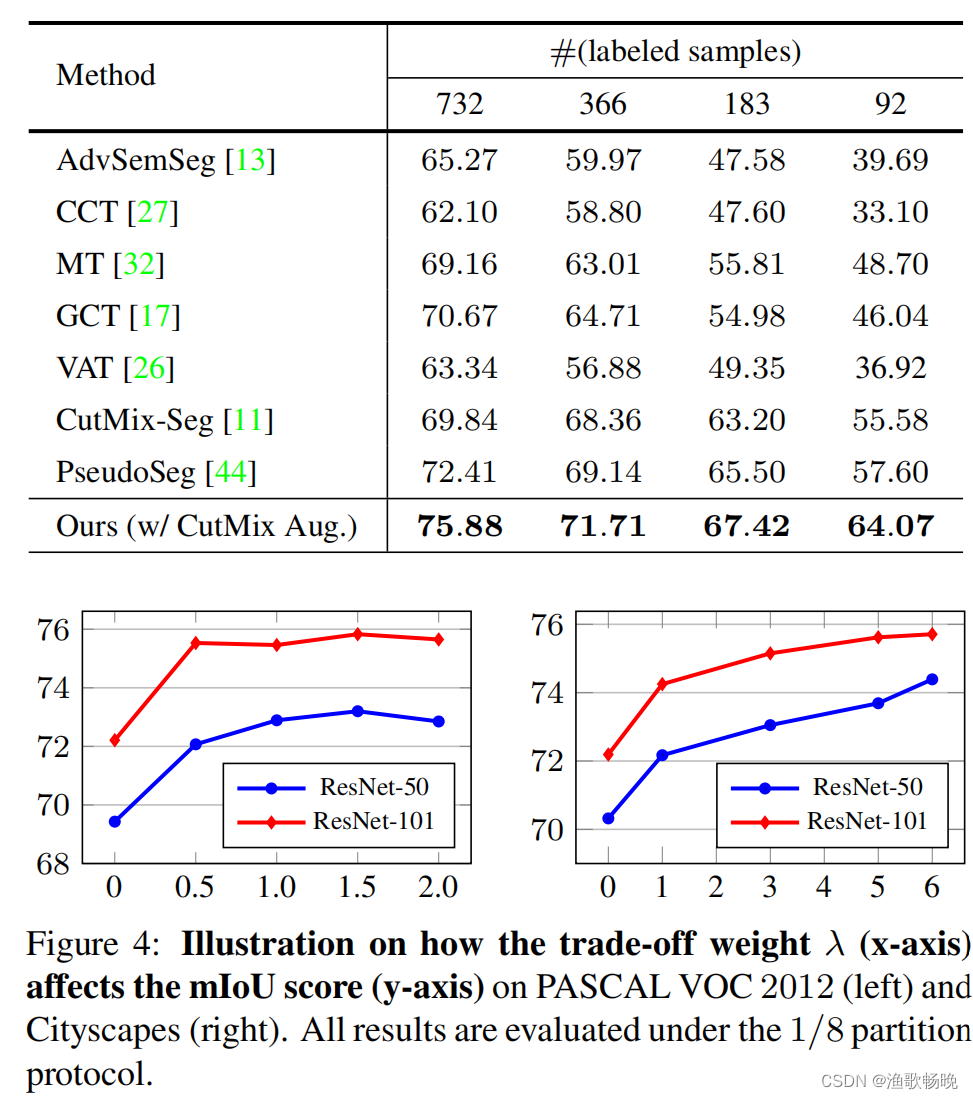
7.2与SOTA对比
不同分割协议下的Meat-Teacher (MT)、交叉一致性训练(CCT) 、引导式协作训练(GCT) 和CutMix-Seg。为了公平起见,使用相同的架构和标签数据集比例对它们进行了比较。
PASCAL VOC 2012:
Cityscapes:
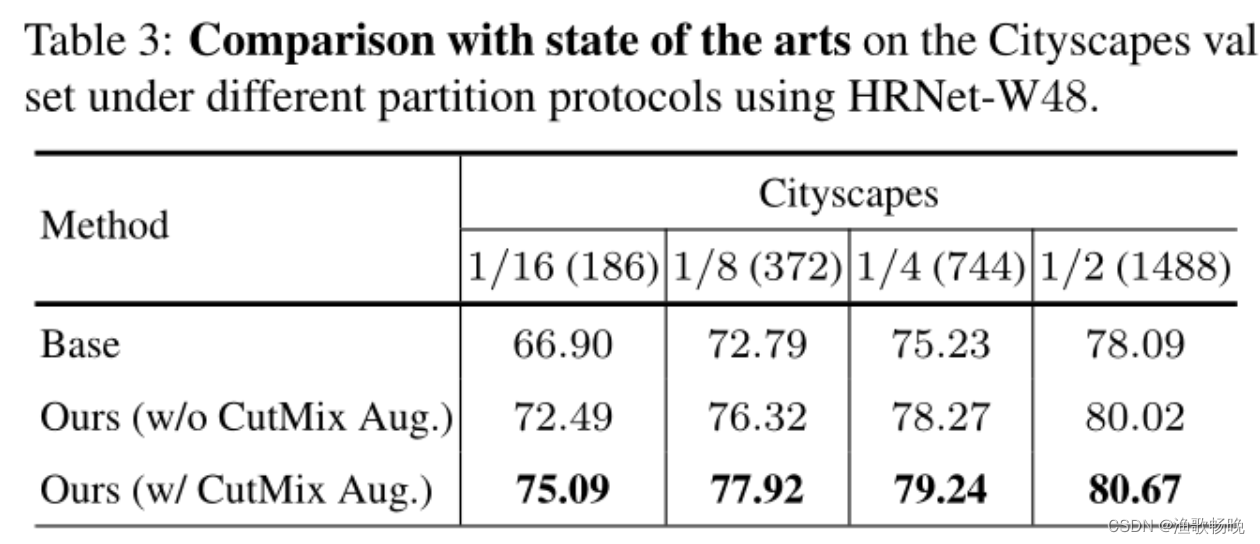
7.4 实证研究
交叉伪监督
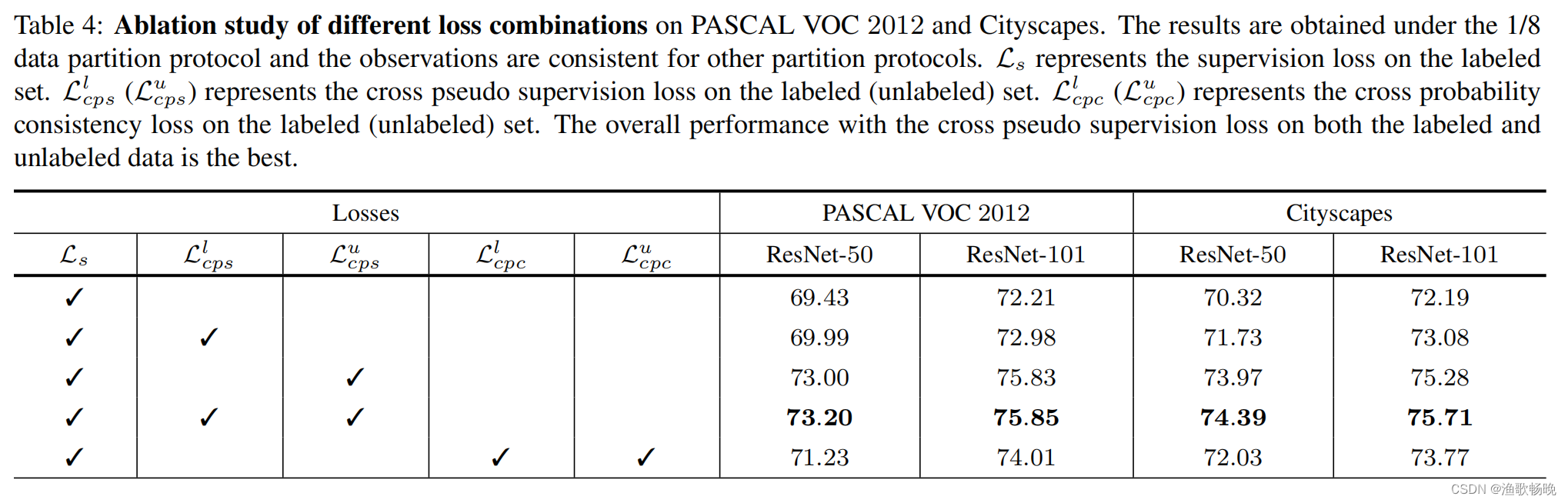
权衡权重λ
我们研究了用于平衡监督损失和交叉伪监督损失的不同λ的影响,如方程6所示。从图4中,我们可以看到λ = 1.5在PASCAL VOC 2012上表现最好,而λ = 6在Cityscapes上表现最好。在我们的方法中,对所有实验使用λ = 1.5和λ = 6。
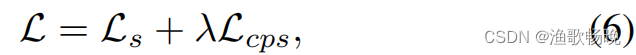
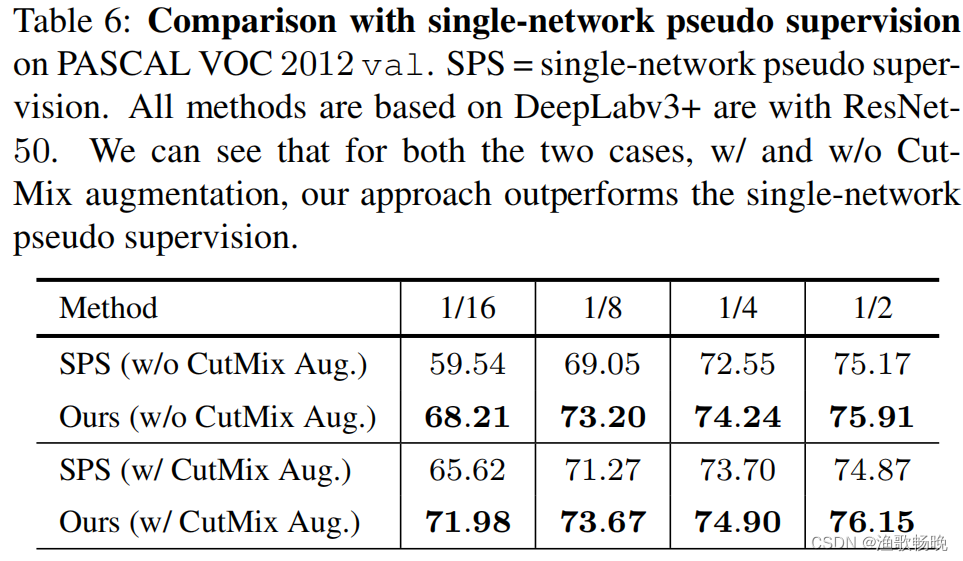
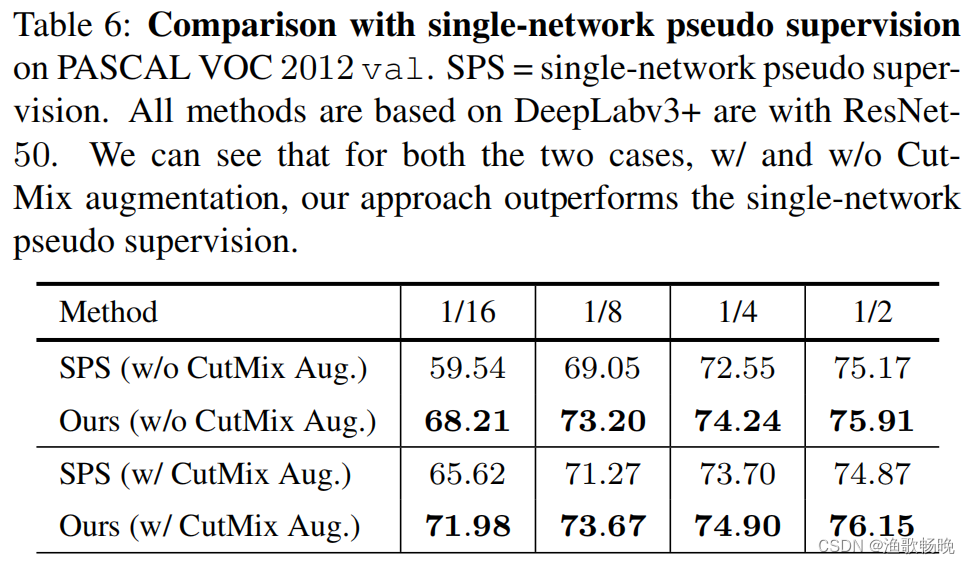
单网络伪监管vs跨网络伪监管
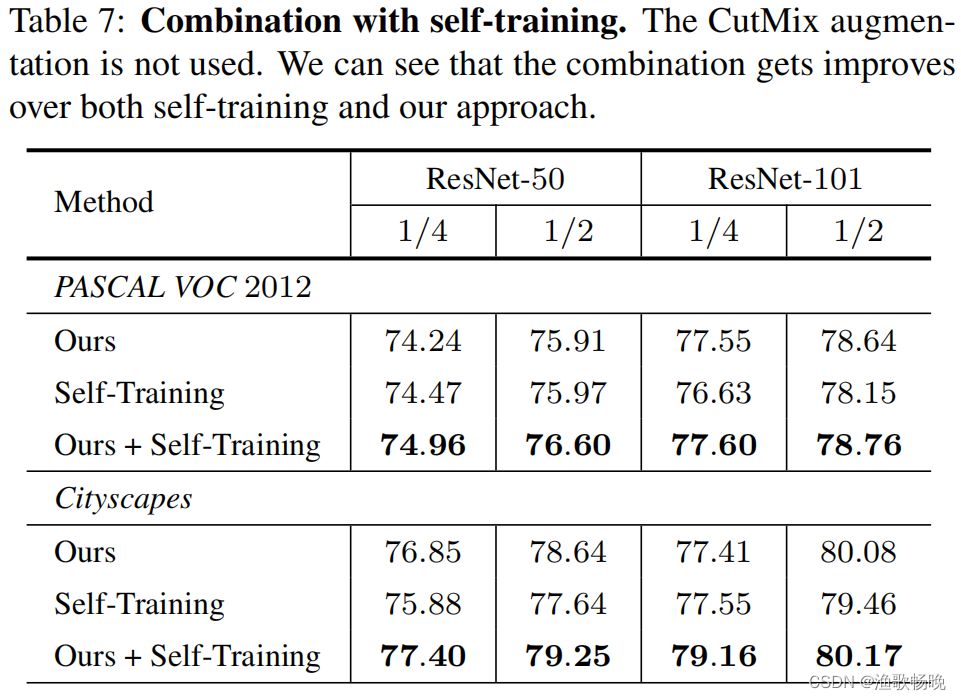
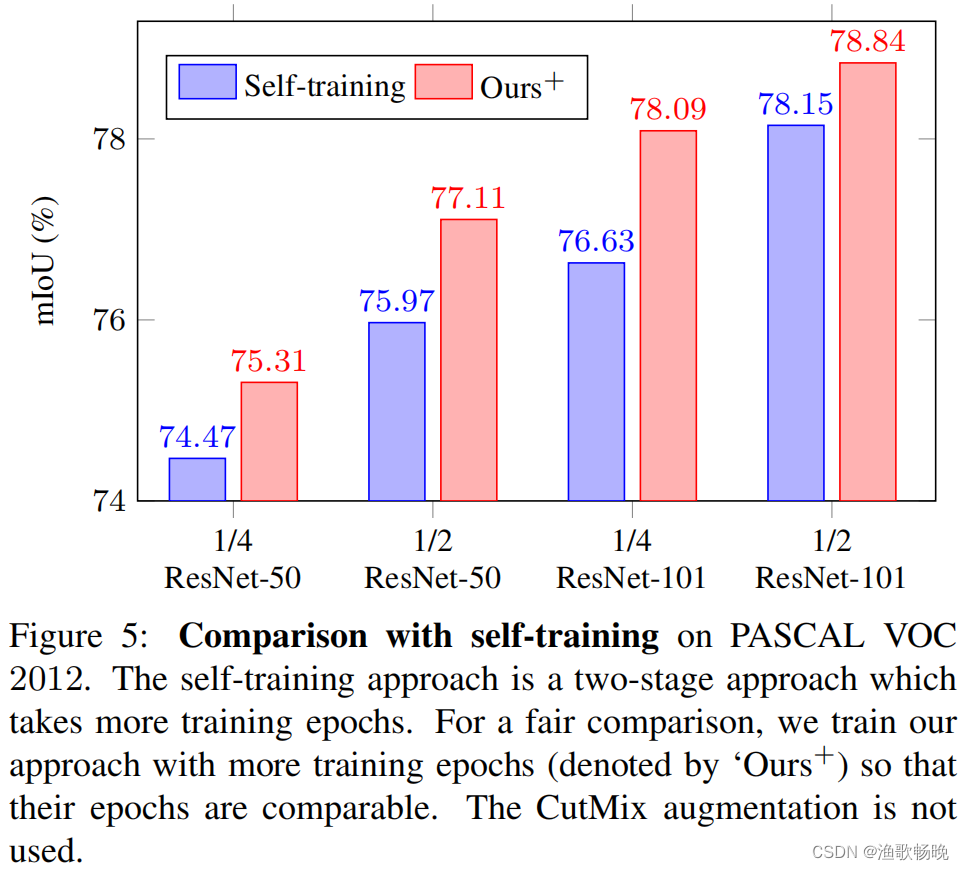
与自我训练比较
八 结论
本文提出一种简单但有效的半监督分割方法——交叉伪监督。

















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









