






论文解读《基于误差定位网络的半监督语义分割》
论文地址: 论文地址
论文代码:论文代码
论文出处: CVPR 2022
一、摘要:
1、 提出了误差定位网络(ELN),该辅助模块以图像及其分割预测为输入,识别出伪标签可能出错的像素点。在训练过程中忽略标签数据中的噪声,使半监督学习对准确的伪标签具有鲁棒性,与自训练和对比学习相结合。
2、 引入了一种新的学习策略,在学习过程中模拟分割错误,以增强其泛化能力。在PASCAL VOC 2012和Cityscapes上进行了评估,在每个评估设置中都优于所有现有的方法。
二、引言
(1)
1、 在文献中,自训练和对比学习是常用的方法。自我训练使用在有标记图像上训练的模型生成无标记图像的伪标签,并使用它们进行监督学习。同时,对比学习使同一伪标签对应的特征向量相互接近。尽管这些技术在很大程度上提高了半监督语义分割的性能,但它们有一个共同的缺点:由于对未标记图像的预测通常会被错误破坏,使用这种预测作为监督的学习将导致对错误的确认偏差,从而返回损坏的模型。大多数现有的方法通过不使用不确定的预测作为监督来缓解这一问题,但它们的表现在很大程度上取决于手工调整的阈值。
2、 利用一个辅助网络来纠正误差,这个模型被称为 误差校正网络(ECN),它从主分割网络的预测和它们在训练图像的标签子集上的标准标签之间的差异进行学习。理想情况下,ECN可以显著提高伪标签的质量。
3、 通过学习和利用一个辅助网络来纠正错误,处理伪标签上的错误,并更好地推广到那些任意未标记的图像。该方法的核心是误差定位网络(ELN)。更重要的是,由于误差定位是一个误差纠正的class-agnostic子问题,因此更容易求解。
class-agnostic 方式只回归2类bounding box,即前景和背景,结合每个box在classification 网络中对应着所有类别的得分,以及检测阈值条件,就可以得到图片中所有类别的检测结果。当然,这种方式最终不同类别的检测结果,可能包含同一个前景框,但实际对精度的影响不算很大,最重要的是大幅减少了bbox回归参数量。
(2) 在主分割网络上附加了多个辅助解码器。框架以两种方式利用未标记的图像:自训练和对比学习,两者都依赖于伪标签。
采用了两个分割网络:学生网络,和教师网络生成伪标签,并通过学生的指数移动平均更新。
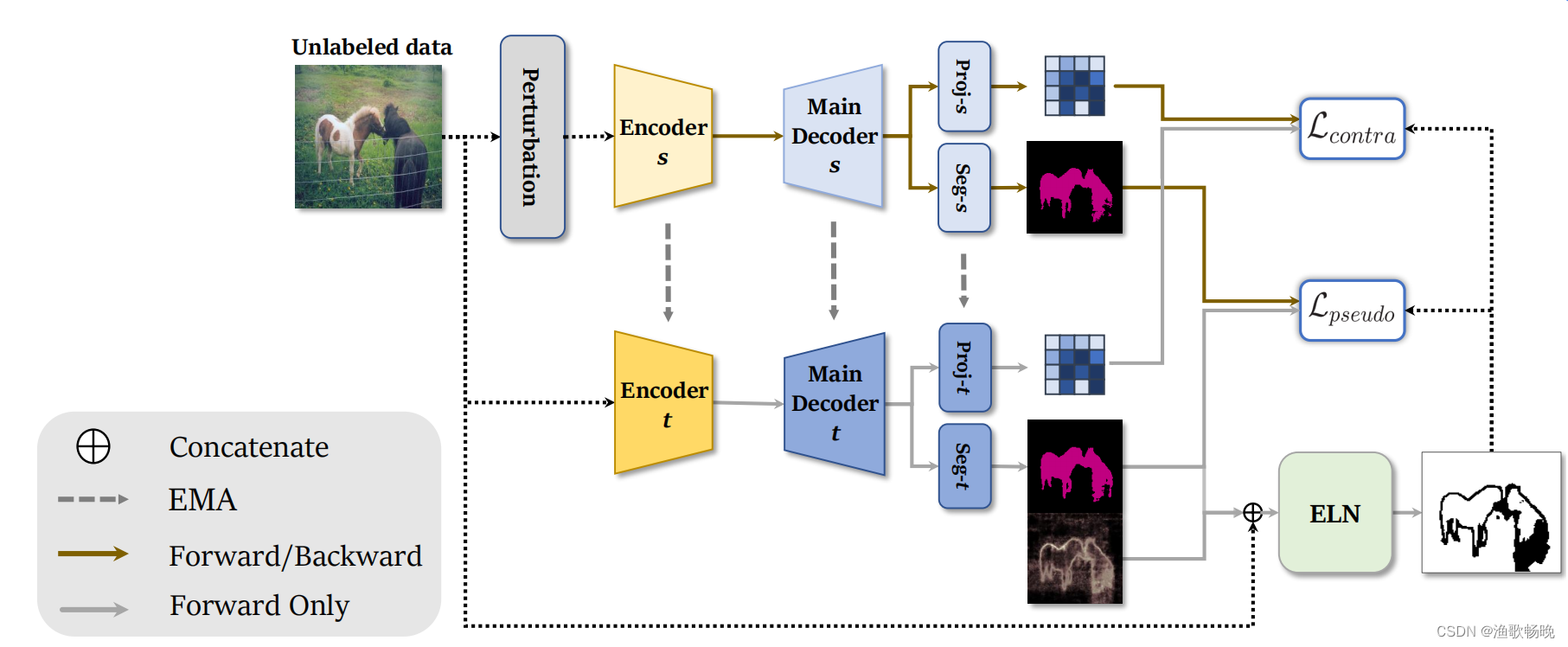
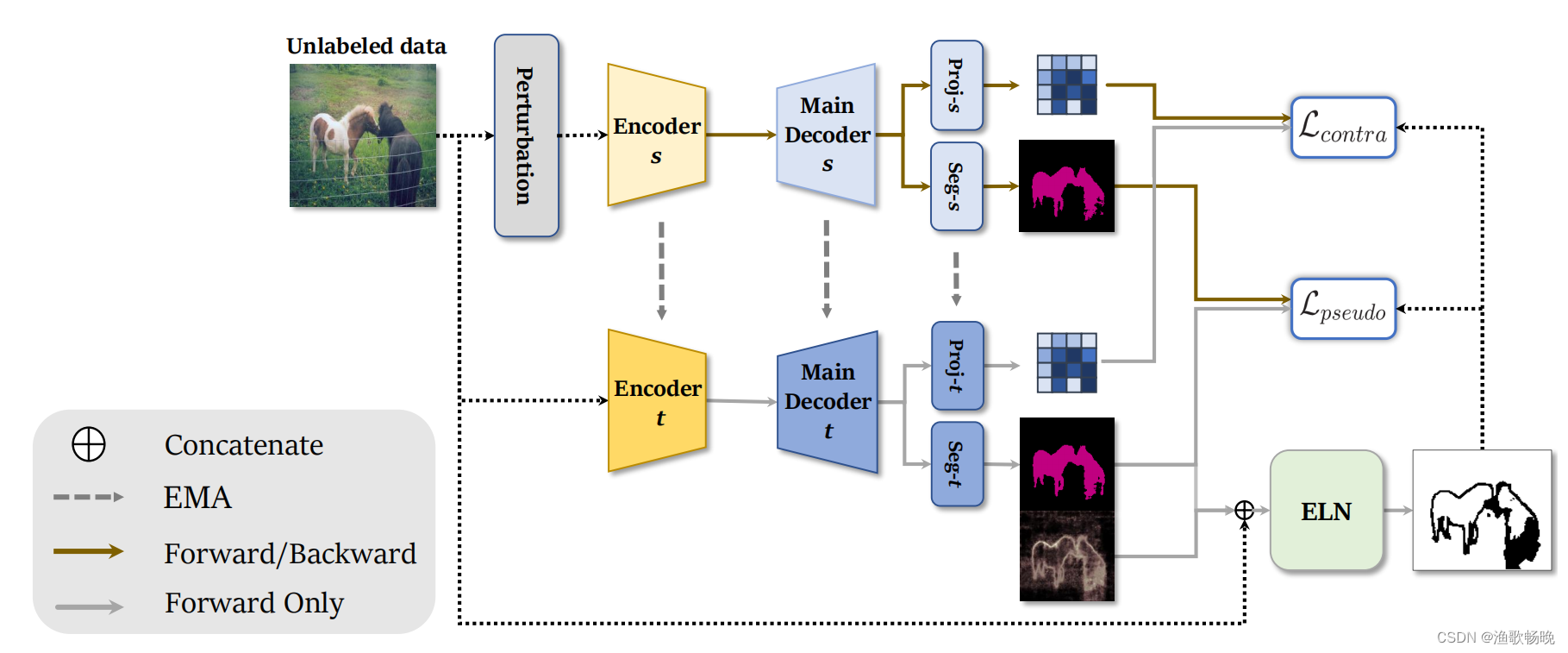
图1 1、结合ELN的半监督学习框架。它使用了两个分割网络,学生(s),和老师(t)用于生成伪标签。学生网络使用教师网络的伪标签进行训练的方式有两种:自训练和对比学习。
2、解码器有两个头部,一个用于分割(Seg),另一个用于特征嵌入(Proj);分别对Seg和Proj头的输出进行了自训练和对比学习。然后用学生网络的指数移动平均(exponentially weighted moving average EMA)更新教师网络参数。
3、ELN识别并忽略伪标签可能有噪声的像素,在自训练和对比学习对伪标签上的噪声处理方面表现更鲁棒。
注: 指数滑动平均,或者叫做指数加权平均(exponentially weighted moving average),可以看做一段时间内的历史加权均值。一般近期的数据拥有更高的权重。
工作总结:
(3) 一种处理伪标签错误的新方法——误差定位。结合自训练和对比学习。实验证明了误差定位优于误差校正。
(4) 在ELN训练过程中产生预测误差。
(5) 在两个基准数据集PASCAL VOC 2012和Cityscapes上,在每个设置中都达到了最先进的水平。
三、传统方法
半监督语义分割的自校正网络 研究了用辅助网络校正伪标签的思想。学习预测和标准真实分割标签之间的差异来纠正伪标签错误的网络。然而,在半监督学习设置下,分割网络会快速的对标记数据进行过拟合,导致校正的泛化性较差,因此很难有效的训练这类网络。为了解决这一泛化问题,引入了一种新的误差定位辅助任务,并提出了ELN及其训练策略。
四、本文方法
我们的学习框架包括两个阶段,使用 标记数据学习ELN和使用ELN的半监督学习 。
第一阶段 的主要问题是主要网络的预测缺乏多样性,这导致了ELN泛化能力差。为了解决这个问题,除了主分割网络(编码器E,解码器D),还采用了辅助解码器(D1 aux,…, DK aux)。ELN与分割网络和辅助解码器一起学习,以识别预测中的错误。ELN训练的总体流程如图2所示。
在第二阶段,训练后的ELN被用于语义分割的半监督学习,其中未标记的图像被利用在两种方式,自训练和对比学习。
ELN的作用是识别出伪标签容易出错的像素点。
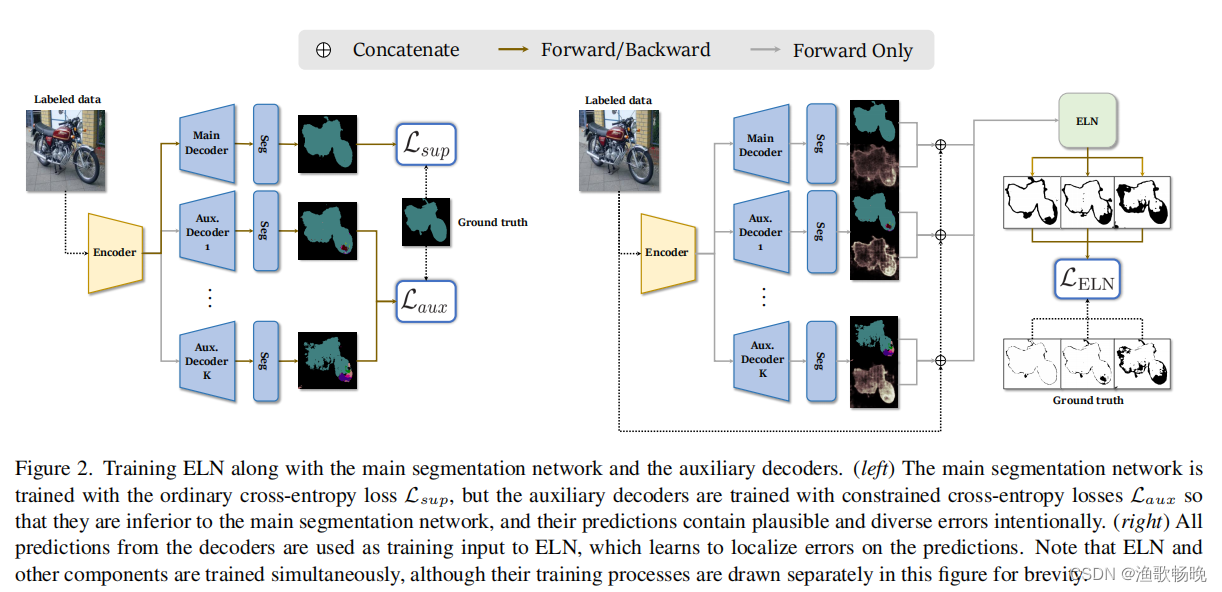
图2 与主分割网络和辅助解码器一起训练ELN。
(左)主分割网络使用普通的交叉熵损失Lsup进行训练,但辅助解码器使用受限的交叉熵损失Laux进行训练,因此它们不如主分割网络,它们的预测包含各种错误。
(右)所有来自解码器的预测都被用作ELN的训练输入,ELN学习在预测上定位误差。ELN和其他组件是同时进行训练的,尽管为了简单起见,它们的训练过程在图中单独绘制。
3.1 学习ELN的标记数据
Lce(P, Y) 表示分割预测P与其标准真实标签Y之间的标准像素交叉熵:
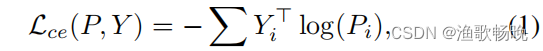
其中i为输入的每个像素的指标,Yi为像素i的标准真实度的一个独热向量。
主分割网络在标记图像集合DL上用 标准的像素交叉熵损失Lsup 进行预训练:
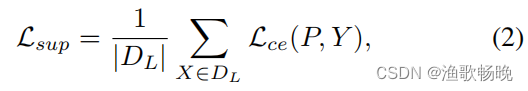
其中Y为输入图像x的标准真值。当预训练完成后,每个辅助解码器的训练与主网络相似,但有约束的交叉熵损失,交叉熵损失仅在Lce(P, Y)的一定倍数内最小,其梯度不会传播到辅助解码器之外。设K为所有辅助解码器的个数,K为其索引。
K个辅助解码器的总损失,用Laux表示,由
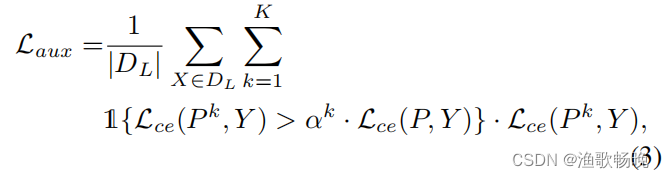
其中Pk = Dk(E(X))表示第k个解码器的分割预测,αk表示用于约束第k个辅助解码器损失的尺度超参数。
设Ek为Pk的像素级熵映射,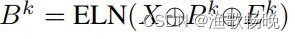
ELN的二元交叉熵损失:
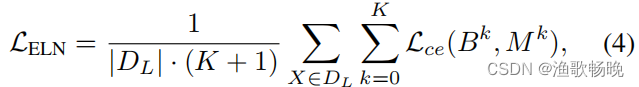
式中Mk为Bk的标准真值掩模;如果像素i的预测正确,Mki为1,否则为0。k = 0表示主解码器。
Lwce表示分割预测P和它的标准真实标签Y之间的权重重新调整的像素交叉熵。
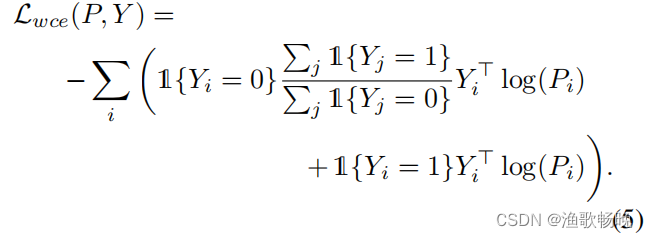
标签数据第一阶段最小化的总损失如下:
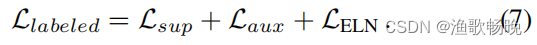
虽然在训练前Lsup是最小的,但在第一阶段Llabelled损失是联合优化的。
3.2 ELN的半监督学习
(1)自训练损失,(2)像素级对比损失。 教师(E, D)的权θ用学生(E, D)的权θ的指数移动平均更新,更新比为β
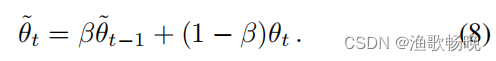
自训练损失Lpseudo是像Lsup一样的像素交叉熵损失,但只适用于经ELN识别的有效像素。
设P = D(E(X))表示教师网络的分割预测,设Pa = D(E(A·X))表示学生网络的分割预测,其中A为对输入图像X的摄动算子,设
为ELN的二值分割输出。然后Lpseudo由
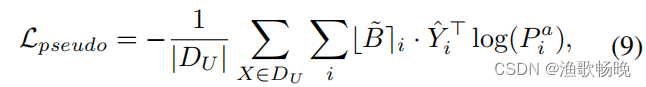
式中为舍入到最接近整数的函数,Yi为像素i伪标签的一个热点向量。通过舍入二值掩码,主分割网络只能在有效像素上训练。
进一步提高学习特征的质量,采用 像素级对比损失Lcontra。
对于给定的输入,用ip表示属于像素i类的一组像素,用in表示不属于像素i类的一组像素。同时,用d表示距离函数,d(f1, f2) = exp(cos(f1, f2)/τ),其中cos表示余弦相似度,τ为温度超参数。像素级对比度损失Lcontra
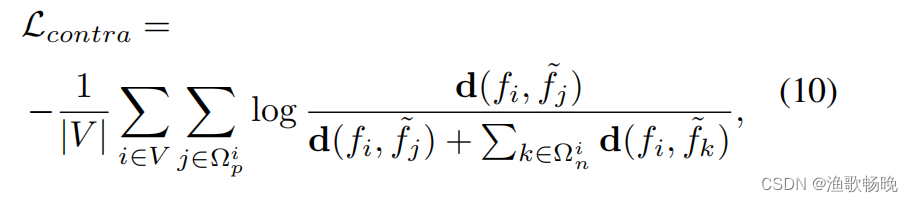
其中V表示DU上的有效像素集合,fi和
分别为来自学生网络和教师网络的像素i的特征嵌入。
未标注数据的总损失如下:
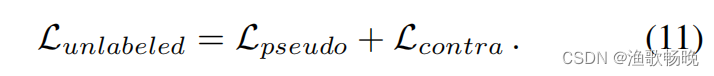
注意标记数据也通过Llabeled参与训练。当训练完成时,只有学生网络用于推理,因为其他的模块,包括ELN,都是支持学生的半监督学习的辅助模块。
############################ ELN网络结构
class ELNetwork(nn.Module):
def __init__(self, output_stride=16, num_classes=21):
super(ELNetwork, self).__init__()
BatchNorm = SynchronizedBatchNorm2d
self.backbone = ResNet34(output_stride, BatchNorm, num_classes)
self.aspp = ASPP(512, output_stride, BatchNorm)
self.decoder = Decoder(BatchNorm, 64)
self.classifier = self.classifier = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1, kernel_size=1, stride=1),
)
@torch.cuda.amp.autocast()
def forward(self, images, cls_output, gt_mode=False):
cls_output = cls_output.detach()
cls_output = F.interpolate(
cls_output, size=images.shape[2:], mode="bilinear", align_corners=True
)
p = F.softmax(cls_output, dim=1)
cls_output_sup_entropy = torch.sum(-p * F.log_softmax(cls_output, dim=1), dim=1)
comb_input = torch.cat(
[images, cls_output_sup_entropy.detach().unsqueeze(1), cls_output.detach()],
dim=1,
)
x, low_level_feat = self.backbone(comb_input)
x = self.aspp(x, gt_mode)
x = self.decoder(x, low_level_feat, gt_mode)
x = self.classifier(x)
return x
4 实验部分
4.1 网络结构
1、 使用带有ResNet骨干网的DeepLab v3+作为我们的分割网络。
2、 该模型主要由两类网络组成: 主分段网络和分段网络 。
每个网络由编码器和解码器组成。
(1) 编码器包括ResNet骨干;
(2) 解码器(包括辅助解码器)包含空间金字塔池化层ASPP(Atrous Spatial Pyramid Pooling) ;
用于分割的像素分类器(图1中的Seg) ;用于特征嵌入的投影(图1中的Proj)等子模块。
ASPP: 1、语义分割模型DeepLabv2中提出了ASPP模块,该模块使用具有不同采样率的多个并行空洞卷积层。为每个采样率提取的特征在单独的分支中进一步处理,并融合以生成最终结果。该模块通过不同的空洞rate构建不同感受野的卷积核,用来获取多尺度物体信息。
2、ASPP是由空洞卷积(Atrous/Dilated Convolution)组成。如果想要对图片提取的特征具有较大的感受野,并且又想让特征图的分辨率不下降太多(分辨率损失太多会丢失许多关于图像边界的细节信息),这两个是矛盾的,想要获取较大感受野需要用较大的卷积核或池化时采用较大的步伐,对于前者计算量太大,后者会损失分辨率。而空洞卷积就是用来解决这个矛盾的。即可让其获得较大感受野,又可让分辨率不损失太多
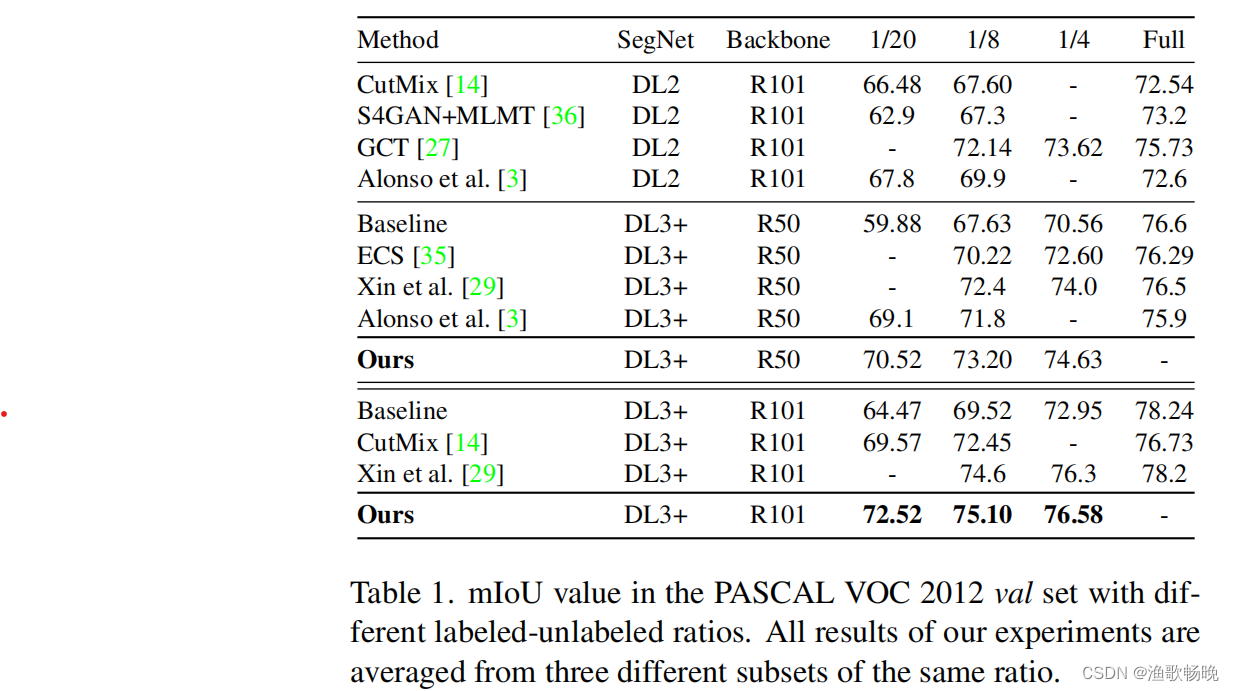
表1。PASCAL VOC 2012 val中的mIoU值设置为不同的已标记-未标记比率。实验的所有结果都是从三个相同比例的不同子集中平均出来的。
注:采用ResNet-50或ResNet-101作为主网骨干(backbone),ELN采用ResNet-34。这些主干是在ImageNet上预先训练的,但由于ELN的输入是图像和张量的拼接,因此它的第一个卷积层相应地被重新设计和微调。
###########编码器encoder
class DeepLab(nn.Module):
def __init__(self, output_stride=16, resnet_name=101):
super(DeepLab, self).__init__()
BatchNorm = SynchronizedBatchNorm2d
if resnet_name == 101:
self.backbone = resnet.ResNet101(output_stride, BatchNorm)
elif resnet_name == 50:
self.backbone = resnet.ResNet50(output_stride, BatchNorm)
@torch.cuda.amp.autocast()
def forward(self, input):
x, low_level_feat = self.backbone(input)
return x, low_level_feat
class classifier(nn.Module):
def __init__(self, num_classes=21, out_dim=256):
super(classifier, self).__init__()
self.classifier = nn.Sequential(
nn.Conv2d(out_dim, out_dim, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_dim, num_classes, kernel_size=1, stride=1),
)
@torch.cuda.amp.autocast()
def forward(self, x, expand=None):
cls = self.classifier(x)
return cls # b x num_class
class projector(nn.Module):#######特征投影
def __init__(self, out_dim=256):
super(projector, self).__init__()
self.projector = nn.Sequential(
nn.Conv2d(out_dim, out_dim, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_dim, 128, kernel_size=1, stride=1),
)
@torch.cuda.amp.autocast()
def forward(self, x):
x = self.projector(x)
return x
###################解码器
class Decoder(nn.Module):
def __init__(
self, backbone="resnet", output_stride=16, num_classes=256, num_cls=21
):
BatchNorm = SynchronizedBatchNorm2d
super(Decoder, self).__init__()
self.aspp = build_aspp(backbone, output_stride, BatchNorm)
self.decoder = build_decoder(num_classes, backbone, BatchNorm)
self.cls = classifier(num_classes=num_cls)
self.proj = projector()
@torch.cuda.amp.autocast()
def forward(self, x, low_level_feat, gt_mode=False):
x = self.aspp(x, gt_mode)#######空间金字塔池化
x_ = self.decoder(x, low_level_feat, gt_mode)
cls = self.cls(x_)#########分类器
proj = self.proj(x_)###########特征投影
return cls, proj
4.2 结果分析
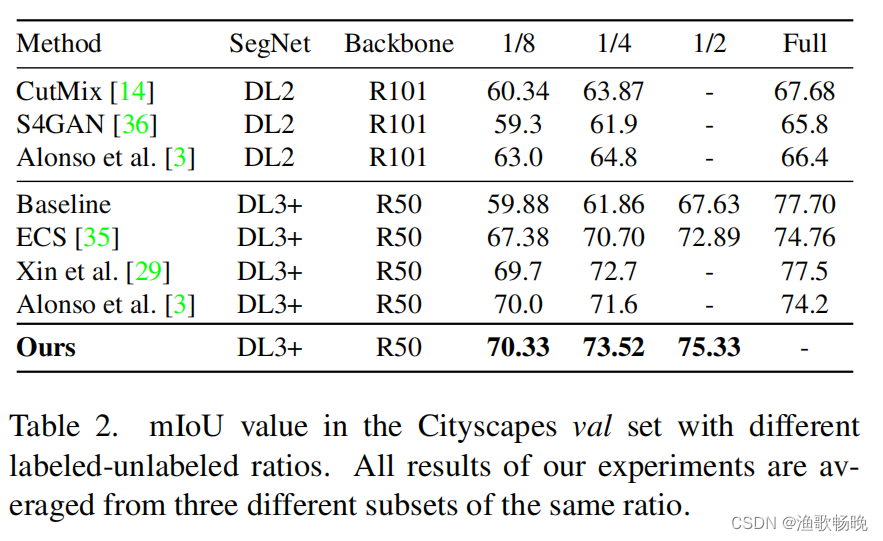
(1)语义分割性能分析 为了证明我们的方法的优越性能,我们将该方法与最新的最先进的模型和仅在标记数据上的训练(Baseline)进行比较。我们的方法对PASCAL VOC 2012的结果列在表1中。
注 :将Deeplab v2简称为DL2,将Deeplab v3+简称为DL3+,将ResNet-50简称为R50,将ResNet-101简称为R101。
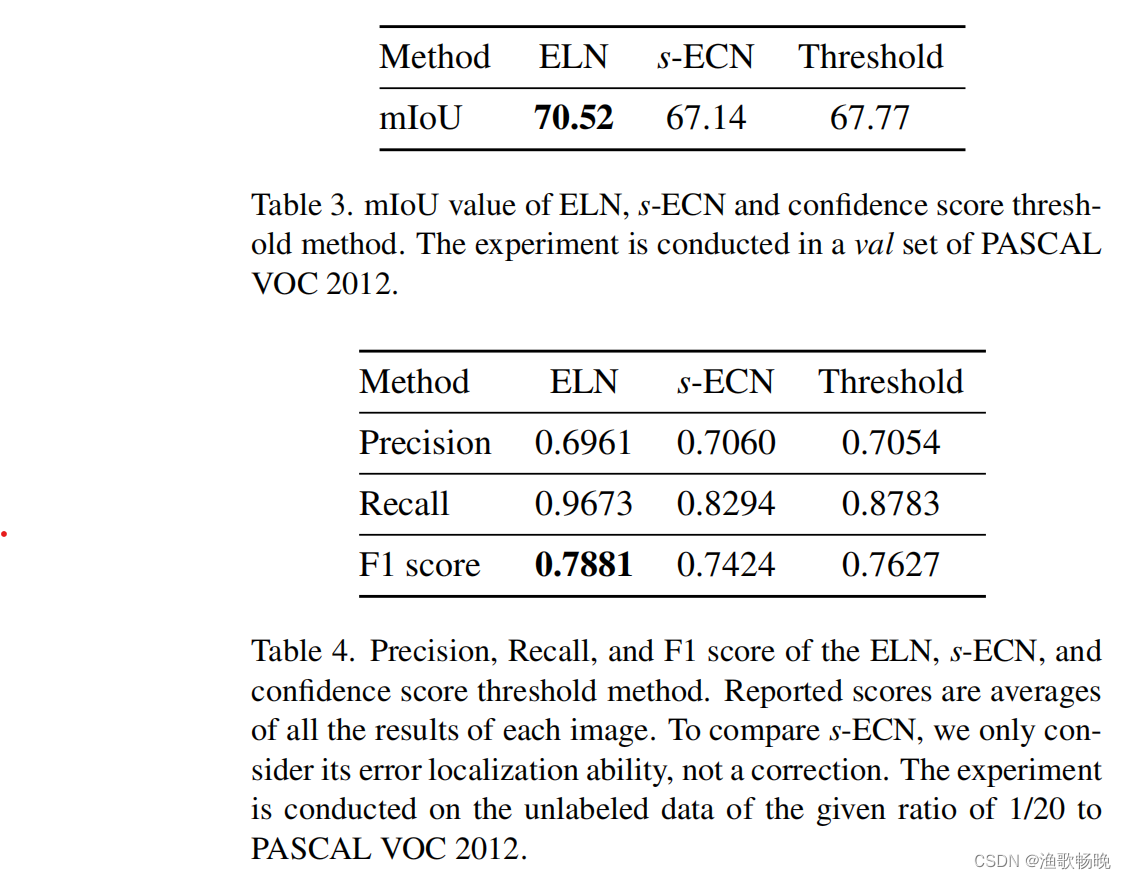
表3 ELN、s-ECN的mIoU值和置信度评分阈值法。实验在PASCAL VOC 2012的验证集上进行。
表4 精度、召回率、F1评分的ELN、s-ECN和置信度评分阈值法。报告的分数是每个图像所有结果的平均值。为了比较s-ECN,我们只考虑了它的误差定位能力,而不考虑它的校正。实验在未标记的数据上进行,给定的比例为1/20 / PASCAL VOC 2012。
(2)误差定位网络的性能分析
以ResNet-50为骨干网络,对PASCAL VOC 2012的1/20进行实验。考虑一种简单的 纠错网络(s-ECN),它具有与ELN相似的学习策略;s-ECN使用像素级交叉熵损失进行训练,并产生一个修正的分割预测作为输出,而不是二进制掩模。在softmax层之后对分割预测的输出进行置信度评分阈值,不需要额外的网络。
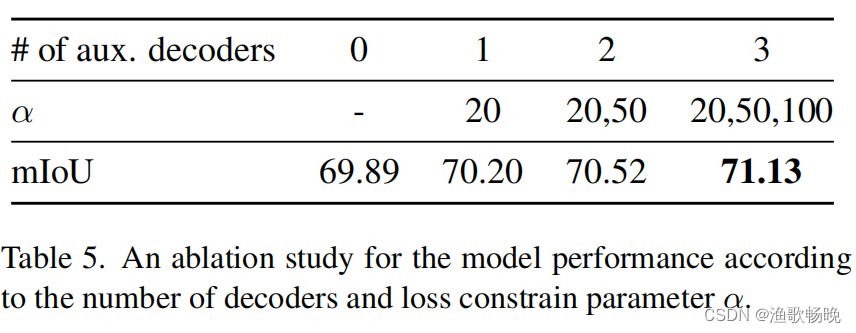
表5所示。根据解码器数量和Loss约束参数α对模型性能进行消融研究。

表6所示。mIoU中不同损耗组合的消融研究。表中的“阈值”是不使用与ELN相关的两种损失,但应用一个置信度评分阈值的方法。
(3)消融实验
我们进行消融研究,以调查所提出方法的每个组成部分的影响。实验基于PASCAL VOC 2012,比例为1/20,结果取三次平均值。我们使用ResNet-50作为主分段网络的主干。
不同数量的辅助解码器
辅助解码器在ELN学习中起着至关重要的作用。通过改变辅助解码器的数量和约束参数来实验辅助解码器对整体性能的影响。结果如表5所示。实验结果表明,随着解码器数量的增加和使用高损耗约束值,系统性能得到了提高。结果表明,不同质量的分割预测有助于语言学习网络的有效学习。注意,我们只需要两个辅助解码器就可以实现足够的性能改进。
式(11)中的不同loss组合
提出的像素级对比损失Lcontra,通过使用标准的像素级交叉熵损失Lpseudo学习图像之间的关系,可以在更多样化的环境中训练特征嵌入。我们对 式(11) 中各损失项的影响进行了比较。
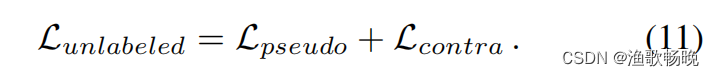

表6所示。mIoU中不同损失组合的消融研究。表中的阈值是不使用与ELN相关的两种损失,但应用一个置信度评分阈值的方法。
五、结论
1、 提出了错误定位网络(ELN)及其训练方案。实验验证了ELN有效地消除了不可见数据的伪标签错误。
2、 在PASCAL VOC 2012和cityscape数据集上都达到了目前的水平,具有较高的泛化能力。
3、 局限性 辅助网络数量多,所需GPU内存大。ELN有时不能指出主分割网络错误预测。














 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









