






目录
一. 背景介绍
广告推荐主要基于用户对广告的历史曝光、点击等行为进行建模,如果只是使用广告域数据,用户行为数据稀疏,行为类型相对单一。而引入同一媒体的跨域数据,可以获得同一广告用户在其他域的行为数据,深度挖掘用户兴趣,丰富用户行为特征。引入其他媒体的广告用户行为数据,也能丰富用户和广告特征。
本赛题希望选手基于广告日志数据,用户基本信息和跨域数据优化广告ctr预估准确率。目标域为广告域,源域为信息流推荐域,通过获取用户在信息流域中曝光、点击信息流等行为数据,进行用户兴趣建模,帮助广告域ctr的精准预估。
二. 赛事要求
本赛题提供7天数据用于训练,1天数据用于测试,数据包括目标域(广告域)用户行为日志,用户基本信息,广告素材信息,源域(信息流域)用户行为数据,源域(信息流域)物品基本信息等。希望选手基于给出的数据,识别并生成源域能反映用户兴趣,并能应用于目标域的用户行为特征表示,基于用户行为序列信息,进行源域和目标域的联合建模,预测用户在广告域的点击率。所提供的数据经过脱敏处理,保证数据安全。
三. 赛事数据
(1) 数据来源

此处可以选择全球、上海、新加坡三类数据进行下载,下载完成解压之后将得到train、test的CSV文件,具体细节可结合下文中“数据说明”自行查阅。
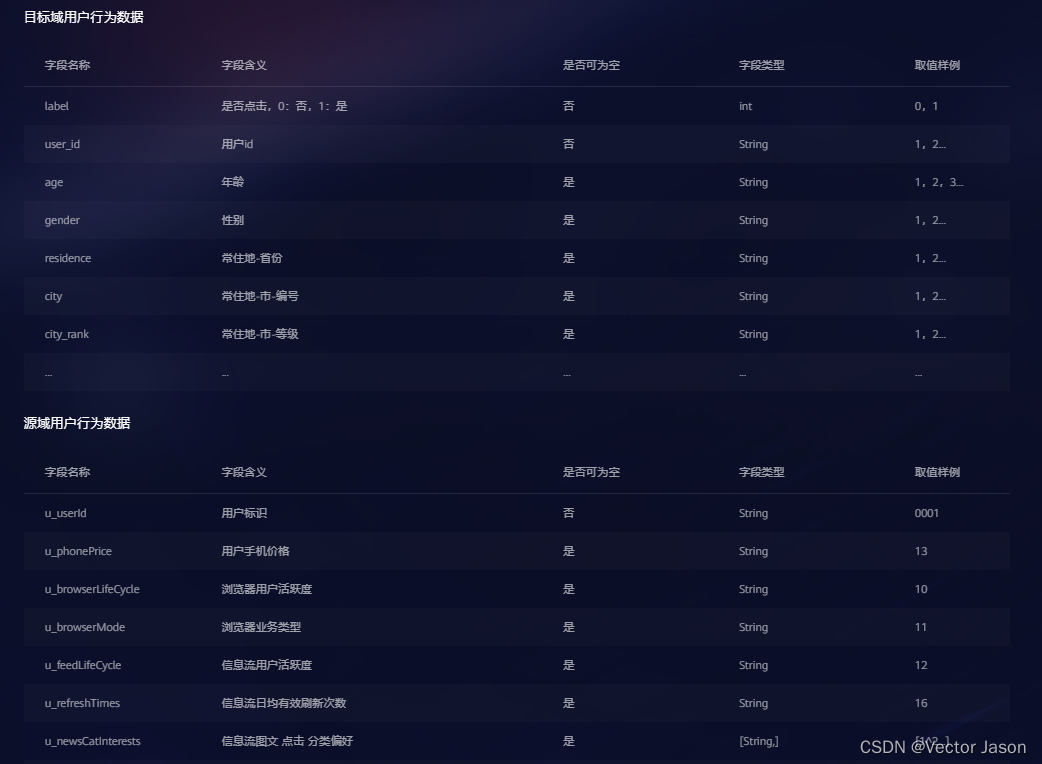
(2) 数据说明
四. 实践思路
本次比赛是一个经典点击率预估(CTR)的数据挖掘赛,选手需要通过训练集数据构建相应的模型,然后对测试集数据进行预测,并提交最终的预测结果。其中,在具体CSV文件中,将根据用户的个人数据如年龄、性别、常住地等来预测这个用户是否点击广告。这种类型的任务是典型的二分类问题,模型的预测输出为 0 或 1 (点击:1,未点击:0),在数据集中即表现为label=1或lable=0。
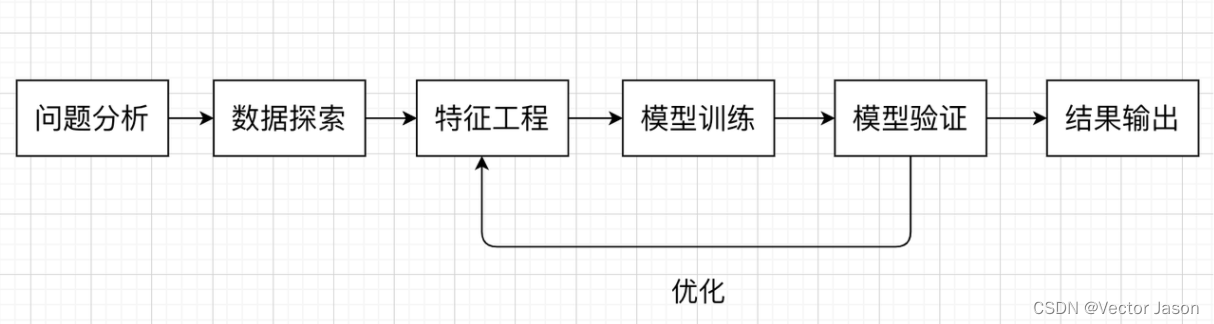
特别地,在考虑类似机器学习问题中,我们通常的分析流程为:
五. 实践代码
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install sklearn
#!pip install pandas
#---------------------------------------------------
#导入库
import pandas as pd
#----------------数据探索----------------
# 只使用目标域用户行为数据
train_ads = pd.read_csv('./train/train_data_ads.csv',
usecols=['log_id', 'label', 'user_id', 'age', 'gender', 'residence', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'])
#此处train_ads读取train文件夹中的train_data_ads.csv文件,读取的内容为'log_id', 'label', 'user_id', 'age', 'gender', 'residence', 'device_name',
# 'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'的各列数据
test_ads = pd.read_csv('./test/test_data_ads.csv',
usecols=['log_id', 'user_id', 'age', 'gender', 'residence', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'])
#此处test_ads读取test文件夹中的test_data_ads.csv文件,读取的内容为'log_id', 'user_id', 'age', 'gender', 'residence', 'device_name',
# 'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd'的各列数据
# 数据集采样
train_ads = pd.concat([
train_ads[train_ads['label'] == 0].sample(70000),
train_ads[train_ads['label'] == 1].sample(10000),
])
#用concat将label分别为0,1且进行采样过后的训练数据拼接起来,其中label为0的训练数据采样70000个,label为1的训练数据则采样10000个
#----------------模型训练----------------
# 加载训练逻辑回归模型
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(
train_ads.drop(['log_id', 'label', 'user_id'], axis=1),
train_ads['label']
)
#将train_ads中'log_id', 'label', 'user_id'三列丢弃后的数据作为自变量X,将'label'该列的数据作为因变量Y进行逻辑回归;
# 利用X,Y对逻辑回归模型进行训练(调整权重、偏置)
#----------------结果输出----------------
# 模型预测与生成结果文件
test_ads['pctr'] = clf.predict_proba(
test_ads.drop(['log_id', 'user_id'], axis=1),
)[:, 1]
test_ads[['log_id', 'pctr']].to_csv('submission.csv',index=None)
#将test_ads中'log_id', 'user_id'两列丢弃后的数据作为自变量X,利用已训练结束的逻辑回归模型,把最终预测结果按照列向量的形式放入test_ads中的'pctr'列;
# 将处理后的test_ads文件提取'log_id', 'pctr'两列放入到命名为submission.csv的文件中
六. 结论
经过提交submission文件后,得分情况为:

相比之下,排行榜最佳得分情况为:

结合上述对比分析,可得到以下结论:
1. LogisticRegression线性模型对该数据集的拟合效果较差,由于该模型相对简单,从而导致泛化性、鲁棒性较差,不能合理切实地预测数据。
2. 由于数据集庞大,可通过建立神经网络模型来解决该类机器学习问题。其中,可利用pytorch架构的API高效建立模型,并采用老中医式调参的方法获取最优模型以达到最高分数。
七. 备注
提升版本:(成绩0.72)















 6405
6405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









