







 本文深入探讨了GOTURN模型在目标跟踪中的应用,该模型利用深度回归网络实现100FPS的高速跟踪。通过离线训练,模型能从大量数据中学习并具备较好的泛化能力。模型输入包括上一帧目标截图和当前帧搜索区域,输出为相对位置。论文提及模型在处理快速运动和遮挡方面的局限性,并提供了实现源码供进一步研究。
本文深入探讨了GOTURN模型在目标跟踪中的应用,该模型利用深度回归网络实现100FPS的高速跟踪。通过离线训练,模型能从大量数据中学习并具备较好的泛化能力。模型输入包括上一帧目标截图和当前帧搜索区域,输出为相对位置。论文提及模型在处理快速运动和遮挡方面的局限性,并提供了实现源码供进一步研究。
Learning to Track at 100 FPS with Deep Regression Networks,
David Held, Sebastian Thrun, Silvio Savarese,
European Conference on Computer Vision (ECCV), 2016 (In press)
论文解读
本文采用深度学习回归模型GOTURN(Generic Object Tracking Using Regression Networks)解决单目标跟踪问题。单目标跟踪问题的难点在于物体的平移、旋转、大小变化、视角变化、明暗变化、变形以及遮挡等情况。
作者一直在强调的是本模型可以离线训练,这样可以从大量的训练数据中学到数据的分布;而且在使用的时候由于只有正向的一个推理过程,在GPU上的速度可以达到100fps(其他基于神经网络的跟踪器速度在0.8fps-15fps之间,性能最好的神经网络跟踪器的速递为1fps。);另外大量的训练数据也使得模型的泛化性能比较好,可以跟踪其他没有见过的物体。需要补充一点,速度的提升的原因除了离线训练还有模型本身的原因,本文提出的模型是回归模型,网络只需正向跑一次,而其他深度跟踪模型本身是分类模型,需要对多个候选patches进行打分,以得分最高者作为目标。
模型:
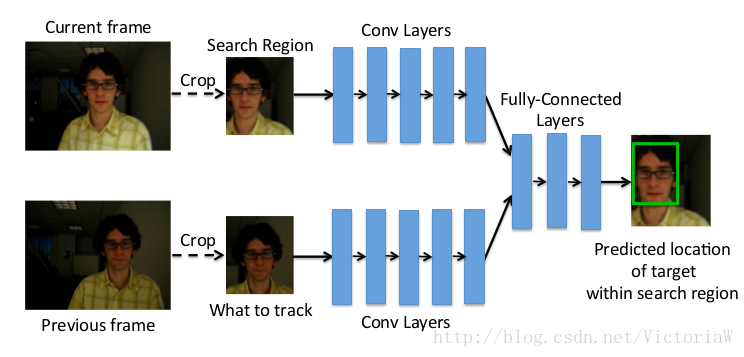
输入:
GOTURN是按帧处理视频的,根据上一张图中目标的位置来判断当前图片的目标位置,本质上还是在处理图片。假设上一张图片目标以 c=(cx,cy) 为中心,宽 w 高
那么问题来了,不同图片上的目标的BBox大小形状不一,导致截图不一样,但是神经网络的输入要求固定大小,怎么办呢?对截图进行reshape处理,缩放到一样大小。
为什么要在当前图片中以 c 为中心截宽
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3580
3580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









