






文章目录
一、准备工作
导入库+创建数据表
import numpy as np
import pandas as pd
#数据预处理与数据提取
#创建数据表1
df1 = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20220102', periods=6),
"city":['Beijing ', 'Hangzhou', 'Shanghai', 'Beijing', 'Shanghai', 'Shanghai'],
"age":[31,27,25,27,29,28],
"category":['100-B','100-B','110-A','110-C','210-C','130-F'],
"price":[1000,np.nan,2300,5400,np.nan,3330]},
columns =['id','date','city','category','age','price'])
#创建数据字典
col={'id':[1001,1002,1003,1004,1005,1006,1007,1008,1009],
'gender':['F','M','F','F','M','M','M','F','F'],
'name':['Jane','Wan','Summer','Flore','Wang','Chung','Dev','Linda','Lucy',],
'salary':[3000,5500,3500,4600,4500,6000,3800,6500,3500]}
#创建数据表2
df2 = pd.DataFrame(col,
columns =['id','gender','name','salary'])
二、数据合并
1、merge数据表连接
类似SQL中的join on,内连接、左连接、右连接、外连接
#数据表合并
df_inner=pd.merge(df1,df2,how='inner') # 匹配合并,交集
df_left=pd.merge(df1,df2,how='left')
df_right=pd.merge(df1,df2,how='right')
df_outer=pd.merge(df1,df2,how='outer') #并集
print(df_inner)
print(df_left)
print(df_right)
print(df_outer)
内连接结果:

2、添加数据
1)append追加
两个表上下进行连接,不匹配的字段则将值设置为NaN
#添加数据,相当于union,和全连接full join
# df_addtion = df1.append(df2) #把df2添加到df1后面
# print(df_addtion)
2)concat连接
一中简单纵向连接,可以用于不同行不同列,表之间或者列之间
#df1和df2两个表进行连接:与append追加的结果一样
df_concat = pd.concat([df1,df2], axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
sort=False, copy=True)
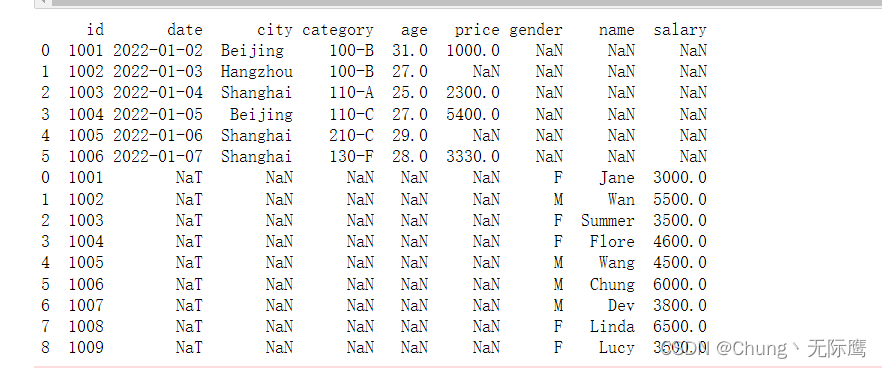
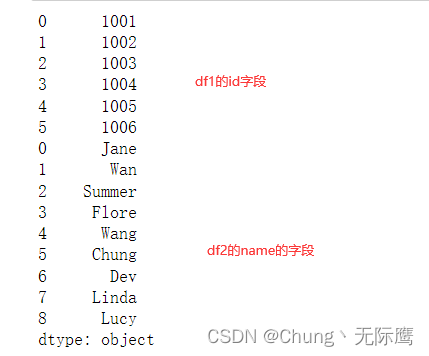
#df1的id字段与df2的name字段进行连接
df_concat = pd.concat([df1.id,df2.name], axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
sort=False, copy=True)
print(df_concat)
df1的id字段与df2的name字段进行连接:
三、数据提取
1、索引列
#设置索引列
df1.set_index('id') #把id列设置为索引列
#按索引提取单行的数值
df_inner.loc[5] #提取“索引值”为5的那一行数据,也就是第6行
#按索引提取区域行数值
df_inner.iloc[0:3] #用切片提取前3行
#重设索引
df_inner.reset_index() #再设置一条索引
2、loc函数(⭐)
利用切片原理,使用loc函数进行切片操作时只能使用行名或者列名,也就是索引(行名)和字符串(列名)。
1)索引操作
df_inner.loc[:4] #因为是索引名,所以这里是取0到4的所有列
df_inner.loc[2:4] #2到4的所有列

2)索引+列名操作
df_inner.loc[2:4,'age':'name'] #2到4的age到name列
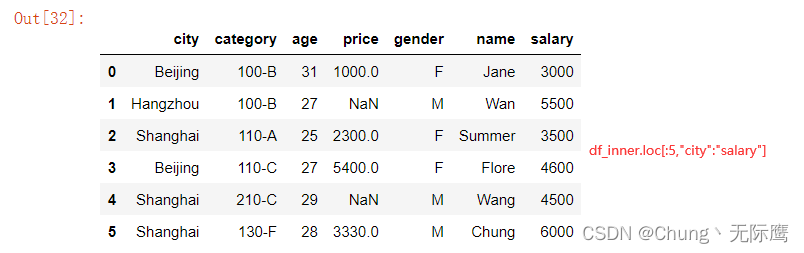
df_inner.loc[:5,"city":"salary"]
3)特殊索引名操作
索引是默认的01234,而不是date,但是这里仍然可以选取到数据,导致索引模糊不清因此这种方法不常用,常用的是明确的索引定位。
df_inner.loc['2022-01-02':] #提取2022年1月2日以后的所有行
df_inner.loc[:'2022-01-05'] #提取2022年1月5日之前的所有数据

4)特殊索引+列名操作
df_inner.loc['2022-01-02':,'age':'name'] #提取2022年1月2日后的age到name列
df_inner.loc[:'2022-01-05',:] #提取2022年1月5日前的所有列
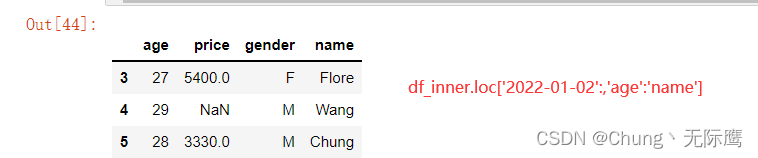
5)自定义索引+自定义列名
#将索引定义为id,并且因为下面还需要用到替换后的表,因此选择替换源数据
df_inner.set_index('id',inplace=True)
#把列名city替换为城市
df_inner.rename(columns={'city':'城市'},inplace=True)
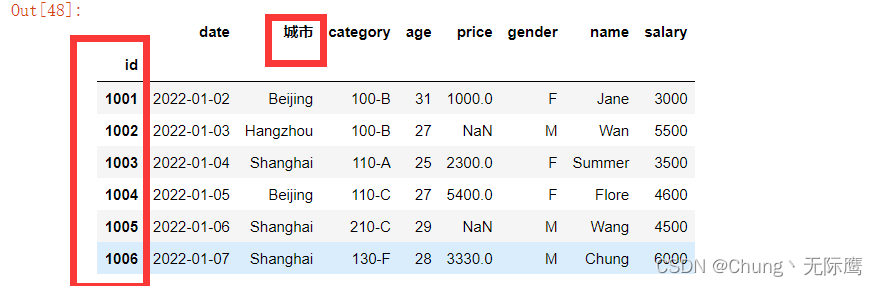
提取id为1002-1005的’城市‘列到’name‘列信息:
#尝试:
df_inner.loc[1002:1005] #id为1002-1005的信息
df_inner.loc[:,'城市':'name'] #城市‘列到’name‘列信息
#实现:id为1002-1005的’城市‘列到’name‘列信息
df_inner.loc[1002:1005,'城市':'name']
3、ix函数
1)ix出现问题:AttributeError: ‘DataFrame’ object has no attribute ‘ix’
2)解决思路:
s.ix[:3]返回的结果与s.loc[:3]一样,这是因为如果series的索引是整型的话,ix会首先去寻找索引中的标签3而不是去找位置3,因此造成了一些混乱
3)解决方法:pandas的1.0.0版本后,已经对该函数进行了升级和重构。
只需要将
column01 = dataset.ix[:, 'first']
改为
column01 = dataset.loc[:,'first']
也就是将ix函数名改为loc即可。
4、iloc函数
1)iloc函数则和loc函数相反,只能使用默认的数字索引,不能使用自定义的行列名字索引
#使用iloc按位置区域提取数据
df_inner.iloc[:4,:5] #从0开始,前四行,前五列
df_inner.iloc[1:3,2:] #从1到3行,第2列以后的所有列
注意:冒号前后的数字不再是索引的标签名称,而是数据所在的位置.
2)按位置单独提取数据(间隔提取)
df_inner.iloc[[0,2,5],[4,5]] #提取第0、2、4行,4、5列

5、排序
#按照索引列排序
df1.sort_index(ascending=False) #ascending为False表示降序,默认升序
#按照特定列值排序
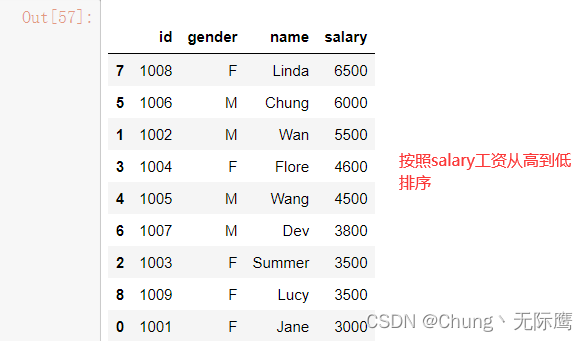
df2.sort_values(by='salary',ascending=False) #按照salary工资从高到低排序
.
6、特定标记
相当于SQL中的CASE WHEN
#单条件标记:工资大于3000为high,低于3000为low
df_inner['level'] = np.where(df_inner['salary'] > 3000,'high','low') #df_inner是两表进行内连接的结果
print(df_inner)
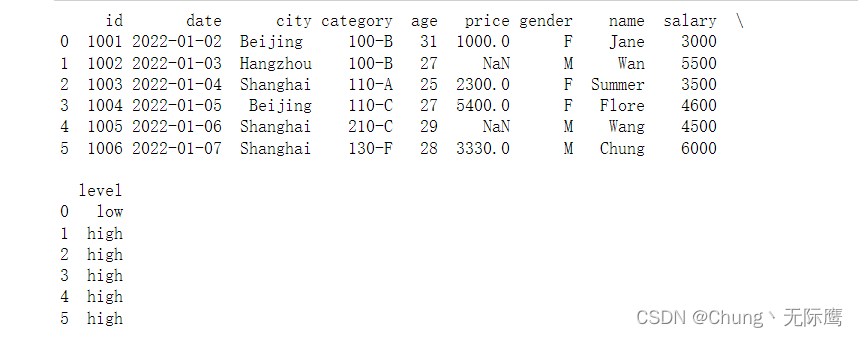
#多条件分组标记:city为上海,工资大于4000等级为1
df_inner.loc[(df_inner['city'] == 'Shanghai') & (df_inner['salary'] >= 4000), 'level']=1
print(df_inner)
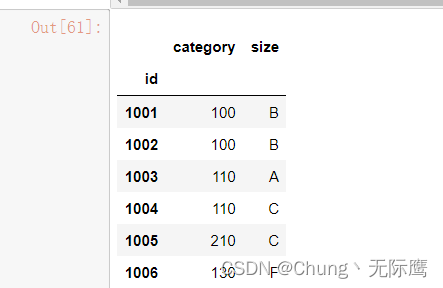
7、分列
将category字段的值依次进行分列,
并创建2个新列组成新表,
索引值为df_inner的id,
列名称分别为category和size
pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.id, columns=['category','size'])
8、提取字符生成新表
提取前三个字符,并生成数据表
df3=pd.DataFrame(df_inner['name'].str[:3])
df3.set_index('name')
print(df3)

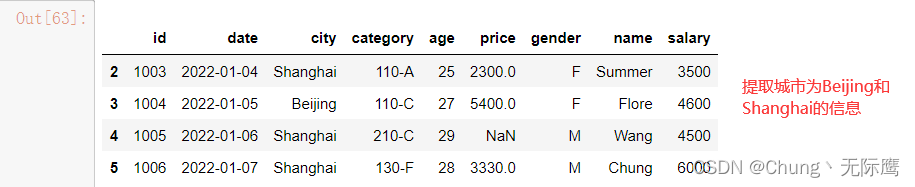
9、isin条件提取
#判断city列的值是否为北京
df_inner['city'].isin(['Shanghai'])
#判断city列里是否包含Beijing和Shanghai,然后将符合条件的数据提取出来
df_inner.loc[df_inner['city'].isin(['Beijing','Shanghai'])]
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











