







 本文介绍了如何使用Pandas进行数据合并,包括concat函数的使用,如行/列方向的合并以及内/外连接操作。同时,展示了数据清洗过程,如检测和处理重复值、缺失值以及异常值的方法。此外,还涉及了哑变量处理和连续型变量的离散化策略。
本文介绍了如何使用Pandas进行数据合并,包括concat函数的使用,如行/列方向的合并以及内/外连接操作。同时,展示了数据清洗过程,如检测和处理重复值、缺失值以及异常值的方法。此外,还涉及了哑变量处理和连续型变量的离散化策略。
一、数据合并
1.数据合并之 concat 数据堆叠
对于pandas对象(如Series和DataFrame),带有标签的轴使你能够进一步推广数组的连接运算。具体点说,你还需要考虑以下这些东西:
- 如果对象在其它轴上的索引不同,我们应该合并这些轴的不同元素还是只使用交集?
- 连接的数据集是否需要在结果对象中可识别?
- 连接轴中保存的数据是否需要保留?许多情况下,DataFrame默认的整数标签最好在连接时删掉。
pandas的concat函数提供了一种能够解决这些问题的可靠方式。我将给出一些例子来讲解其使用方式。假设有三个没有重叠索引的Series:
1.1创建以下Series,使用concat对s1,s2进行合并并打印。
import pandas as pd import numpy as np s1 = pd.Series([0, 1], index=['a', 'b']) s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e']) display(s1,s2) """ 输出为 a 0 b 1 dtype: int64 c 2 d 3 e 4 dtype: int64 """ print(pd.concat([s1,s2])) """ a 0 b 1 c 2 d 3 e 4 dtype: int64 """默认情况下,concat是在axis=0及行方向上工作的,最终产生一个新的Series。
1.2使用concat对s1和s2实现列方向的合并并打印。
如果传入axis=1,则结果就会变成一个DataFrame(axis=1是列):
print(pd.concat([s1,s2],axis=1)) """ 0 1 a 0.0 NaN b 1.0 NaN c NaN 2.0 d NaN 3.0 e NaN 4.0 """这种情况下,另外的轴上没有重叠,从索引的有序并集(外连接)上就可以看出来。也就是说,默认情况下,可得到它们的并集(即外连接)。
1.3创建s4,使用concat对s1和s4实现列方向的交集(内连接)合并并打印。其中s4 = pd.concat([s1, s3]), s3 = pd.Series([5, 6], index=['f', 'g'])。
若要得到交集(即内连接),可传入join='inner'即可得到它们的交集。
s3 = pd.Series([5, 6], index=['f', 'g']) s4 = pd.concat([s1, s3]) print(pd.concat([s3,s4],axis=1,join='inner')) """ 0 1 f 5 5 g 6 6 """在这个例子中,f和g标签消失了,是因为使用的是join='inner'选项。
2.数据合并之 combine_first 重叠合并
还有一种数据组合问题不能用简单的合并(merge)或连接(concatenation)运算来处理。比如说,你可能有索引全部或部分重叠的两个数据集。举个有启发性的例子,我们使用NumPy的where函数,它表示一种等价于面向数组的if-else:
a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan], index=['f', 'e', 'd', 'c', 'b', 'a']) b = pd.Series(np.arange(len(a), dtype=np.float64), index=['f', 'e', 'd', 'c', 'b', 'a']) b[-1] = np.nan display(a,b) """ f NaN e 2.5 d NaN c 3.5 b 4.5 a NaN dtype: float64 f 0.0 e 1.0 d 2.0 c 3.0 b 4.0 a NaN dtype: float64 """2.1利用combine_first实现 b[:-2] 和 a[2:] 的重叠合并:
(1)打印 b[:-2].combine_first(a[2:]) 并观察结果。
(2)打印 a[2:].combine_first(b[:-2]) 并观察结果。
b[:-2].combine_first(a[2:]) """ a NaN b 4.5 c 3.0 d 2.0 e 1.0 f 0.0 dtype: float64 """ a[2:].combine_first(b[:-2]) """ a NaN b 4.5 c 3.5 d 2.0 e 1.0 f 0.0 dtype: float64 """2.2对于DataFrame,combine_first自然也会在列上做同样的事情,因此你可以将其看做:用传递对象中的数据为调用对象的缺失数据“打补丁”:
(1)df2.combine_first(df3)
(2)df3.combine_first(df2)
观察(1)和(2)的结果有何不同并打印。
df2 = pd.DataFrame({'a': [1., np.nan, 5., np.nan], 'b': [np.nan, 2., np.nan, 6.], 'c': range(2, 18, 4)}) df3 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.], 'b': [np.nan, 3., 4., 6., 8.]}) display(df2,df3) """ a b c 0 1.0 NaN 2 1 NaN 2.0 6 2 5.0 NaN 10 3 NaN 6.0 14 a b 0 5.0 NaN 1 4.0 3.0 2 NaN 4.0 3 3.0 6.0 4 7.0 8.0 """df2.combine_first(df3) """ a b c 0 1.0 NaN 2.0 1 4.0 2.0 6.0 2 5.0 4.0 10.0 3 3.0 6.0 14.0 4 7.0 8.0 NaN """ df3.combine_first(df2) """ a b c 0 5.0 NaN 2.0 1 4.0 3.0 6.0 2 5.0 4.0 10.0 3 3.0 6.0 14.0 4 7.0 8.0 NaN """
二、数据清洗与预处理
1. 数据清洗
1.1检测与处理重复值
(1)检测重复值
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行(前面出现过的行):
创建以下DataFrame,并检测重复值:
data0 = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'], 'k2': [1, 1, 2, 3, 3, 4, 4]}) data0 """ k1 k2 0 one 1 1 two 1 2 one 2 3 two 3 4 one 3 5 two 4 6 two 4 """data0.duplicated(keep=False) """ 0 False 1 False 2 False 3 False 4 False 5 True 6 True dtype: bool """(2)处理重复值
① 利用drop_duplicates方法,删除data0重复值。
data0.drop_duplicates(keep=False) """ k1 k2 0 one 1 1 two 1 2 one 2 3 two 3 4 one 3 """② duplicated和drop_duplicates这两个方法默认会判断全部列,你也可以指定部分列进行重复项判断。例如,且只希望根据'k1'列过滤 data0 的重复项,程序如下:
data0.drop_duplicates('k1') """ k1 k2 0 one 1 1 two 1 """③ duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入keep='last'则保留最后一个。
根据'k1'和'k2'列过滤 data0 的重复项,保留最后一个:
data0.drop_duplicates(keep='last') """ k1 k2 0 one 1 1 two 1 2 one 2 3 two 3 4 one 3 6 two 4 """④ inplace 参数可以实现在原表上进行操作。
例如,根据'k2'列过滤 data0 的重复项,保留第一个:
data0.drop_duplicates('k2',inplace=True) display(data0) """ k1 k2 0 one 1 2 one 2 3 two 3 5 two 4 """
1.2 检测与处理缺失值
在许多数据分析工作中,缺失数据是经常发生的。pandas的目标之一就是尽量轻松地处理缺失数据。例如,pandas对象的所有描述性统计默认都不包括缺失数据。
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正常。对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。
(1)检测缺失值
创建以下DataFrame:
① 检测data1缺失值:
data1 = pd.DataFrame([[1., 6.5, 3.], [1., np.nan, np.nan], [np.nan, np.nan, np.nan], [np.nan, 6.5, 3.]]) data1 """ 0 1 2 0 1.0 6.5 3.0 1 1.0 NaN NaN 2 NaN NaN NaN 3 NaN 6.5 3.0 """ data1.isnull() """ 0 1 2 0 False False False 1 False True True 2 True True True 3 True False False """② 统计data1缺失值:
②-1 行方向统计缺失值
②-2 列方向统计缺失值
data1.isnull().T.sum() """ 0 0 1 2 2 3 3 1 dtype: int64 """ data1.isnull().sum() """ 0 2 1 2 2 2 dtype: int64 """(2)处理data1缺失值
① 删除缺失值:
①-1 利用dropna方法可实现缺失值的过滤
data1.dropna() """ 0 1 2 0 1.0 6.5 3.0 """①-2 传入how='all'将只丢弃全为NaN的行
data1.dropna(how='all') """ 0 1 2 0 1.0 6.5 3.0 1 1.0 NaN NaN 3 NaN 6.5 3.0 """①-3 丢弃含有NaN的列
data1[4] = np.nan #添加一列NaN值 data1 """ 0 1 2 4 0 1.0 6.5 3.0 NaN 1 1.0 NaN NaN NaN 2 NaN NaN NaN NaN 3 NaN 6.5 3.0 NaN """ data1.dropna(axis=1, how='any') """ 0 1 2 3 """①-4 若只希望留下一部分观测数据,可以用thresh参数实现此目的
删除data2中非空值少于2个的行:
data2 = pd.DataFrame(np.random.randn(7, 3)) data2.iloc[:4, 1] = np.nan data2.iloc[:2, 2] = np.nan data2 """ 0 1 2 0 -0.898827 NaN NaN 1 0.578754 NaN NaN 2 0.594226 NaN 1.155896 3 1.028439 NaN 1.048531 4 -0.274937 -1.187021 -0.648771 5 0.722347 -1.459620 -0.052184 6 0.355397 0.322658 -0.551293 """data2.dropna(axis=0, thresh=2) """ 0 1 2 2 0.594226 NaN 1.155896 3 1.028439 NaN 1.048531 4 -0.274937 -1.187021 -0.648771 5 0.722347 -1.459620 -0.052184 6 0.355397 0.322658 -0.551293 """删除非空值少于4个的列:
data2.dropna(axis=1, thresh=4)② 填充缺失值:
有时不希望滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为常数值。
②-1 用 0 填充 data2 中的缺失值,返回新的数据框。
data2.fillna(0) """ 0 1 2 0 -0.898827 0.000000 0.000000 1 0.578754 0.000000 0.000000 2 0.594226 0.000000 1.155896 3 1.028439 0.000000 1.048531 4 -0.274937 -1.187021 -0.648771 5 0.722347 -1.459620 -0.052184 6 0.355397 0.322658 -0.551293 """②-2 通过调用fillna,可以实现对列的填充:
data3_lie2 = data2.iloc[:,2] #取出data2的第2列 data3_lie2 """ 0 NaN 1 NaN 2 1.155896 3 1.048531 4 -0.648771 5 -0.052184 6 -0.551293 Name: 2, dtype: float64 """data2.iloc[:,2] = data3_lie2.fillna(6) #填充缺失值后再将其赋值给data2的第2行,注意通过赋值修改了data2 data2②-3 通过一个字典调用fillna,就可以实现对不同的列填充不同的值。
创建以下数据框,将第一列的缺失值填充为0.5,将第二列的缺失值填充为0:
data2 = pd.DataFrame(np.random.randn(7, 3)) data2.iloc[:4, 1] = np.nan data2.iloc[:2, 2] = np.nan data2 """ 0 1 2 0 -0.850256 NaN NaN 1 0.599265 NaN NaN 2 -1.019812 NaN -0.572536 3 1.849595 NaN 0.369481 4 1.340728 0.499847 1.875878 5 -0.152210 -0.844857 0.684423 6 -0.289375 0.452367 -0.229623 """data2.fillna({1:0.5,2:0})②-4 fillna默认会返回新对象,但也可以对现有对象进行就地修改。
创建data2,将data2的第一列的缺失值填充为6:
data2 = pd.DataFrame(np.random.randn(7, 3)) data2.iloc[:4, 1] = np.nan data2.iloc[:2, 2] = np.nan data2 """ 0 1 2 0 -1.018293 NaN NaN 1 -0.142144 NaN NaN 2 1.042160 NaN 0.334089 3 -0.372838 NaN -0.983950 4 0.937713 -0.316478 -1.060486 5 -1.616421 -0.013837 1.307735 6 -1.357601 -1.087214 -0.856341 """data2.fillna({1:6},inplace=True) display(data2)1.3 检测与处理异常值
(1)检测异常值
①-1 利用 3σ 法则检测异常值
①-2 利用箱线图检测异常值
创建以下数据框:
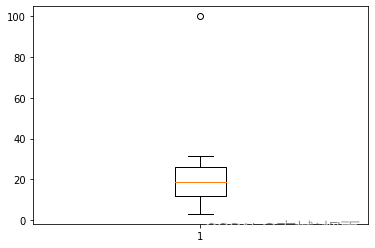
data3 = pd.Series(np.arange(20)) data4 = data3 *1.5 + 3 data4.iloc[4] = 100 data4.plot(x='w',y='y') data4 """ 0 3.0 1 4.5 2 6.0 3 7.5 4 100.0 5 10.5 6 12.0 7 13.5 8 15.0 9 16.5 10 18.0 11 19.5 12 21.0 13 22.5 14 24.0 15 25.5 16 27.0 17 28.5 18 30.0 19 31.5 dtype: float64 """def outRange(Ser): blidx = (Ser.mean()-3*Ser.std()>Ser) | (Ser.mean()+3*Ser.std()< Ser) outRange = Ser[blidx] return outRange outer=outRange(data4) outer """ 4 100.0 dtype: float64 """import matplotlib.pyplot as plt plt.boxplot(data4) plt.show()
(2)处理异常值
将异常值修改为data4的均值:
data4.iloc[4] = data4.mean() data42. 数据变换与数据离散化
2.1 哑变量处理
哑变量是用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。利用pandas库中的get_dummies函数对类别型特征进行哑变量处理。
创建以下数据框:
data5 = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']]) data5.columns = ['color', 'size', 'prize','class label'] display(data5)(1)哑变量变换:
pd.get_dummies(data5)(2)针对DataFrame的某一列或某几列进行哑变量变换
pd.get_dummies(data5[['prize','color','size']])2.2连续型变量的离散化
创建一个数据框,举例说明以下方法:
(1)等宽法
(2)等频法
np.random.seed(12) values = np.random.rand(10) values """ array([0.15416284, 0.7400497 , 0.26331502, 0.53373939, 0.01457496, 0.91874701, 0.90071485, 0.03342143, 0.95694934, 0.13720932]) """# 等宽法 score_cut=pd.cut(values,5) score_cut # 等频法 df=pd.qcut(values,5) df

















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











