







转载请注明出处,谢谢。
对caffe、mxnet等框架的cu文件一直是一个很让人头疼的问题,特别是涉及跟进kernel函数的操作时,用cout打印变量的方式不能奏效。本文将介绍使用cuda-gdb对caffe的cu文件进行debug的方法。本文默认你的驱动、CUDA、OPENCV等caffe所需环境已经配置好,不再赘述此类内容。
一、环境准备:
cuda-gdb已经集成到CUDA里,故在安装CUDA时便已将cuda-gdb安装好了,不需要另外安装。
将$CAFFE_ROOT下的Makefile.config文件中的DEBUG的选项打开。即将
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
DEBUG := 1如果之前已经make过caffe,现在需要输入
make clean然后命令行输入
make all -j20(请根据自己电脑的实际情况修改 -j 后的数字。)
二、使用命令行时debug:
为了方便演示,此处将使用caffe自带的在mnist数据集上训练lenet的examples进行演示。首先在$CAFFE_ROOT下命令行执行
bash data/mnist/get_mnist.sh
bash examples/mnist/create_mnist.sh此时普通训练的命令应为
./build/tools/caffe train -solver examples/mnist/lenet_solver.prototxt 为了使用cuda-gdb,此时应将命令改为
cuda-gdb --args ./build/tools/caffe train -solver examples/mnist/lenet_solver.prototxt (其中 --args 表示后接调试时的指令及参数,所以在debug自己的模型时将这部分指令改为自己训练所用的指令及参数即可。)
执行后有以下界面:
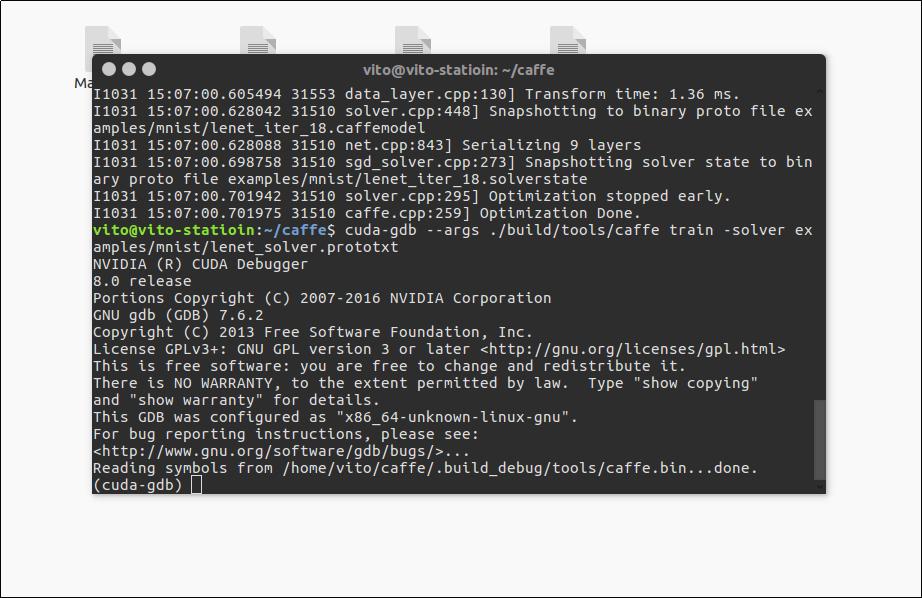
此时便已经进入了cuda-gdb。首先输入
start
可以看到程序停在了main函数处,此时需要插入断点。笔者建议使用文件行号作为断点,格式如下:
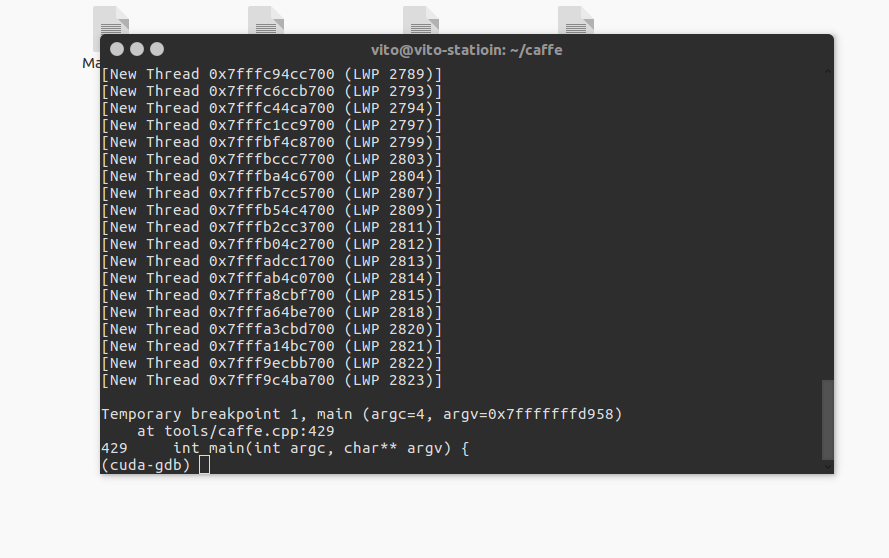
b (你想要debug的cu文件):(行号)例如要debug pooling层的29行话就输入
b pooling_layer.cu:29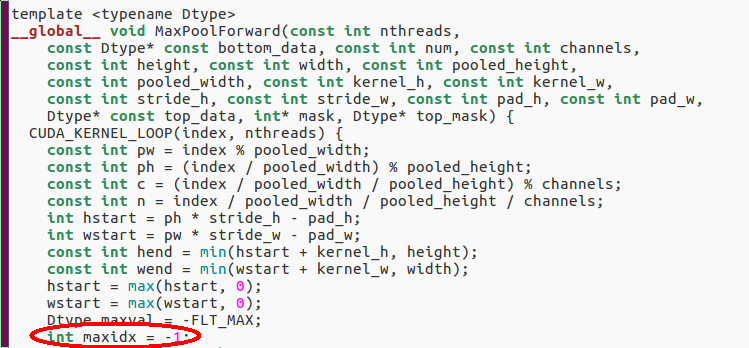
执行命令后有可以看到已经插入了断点。
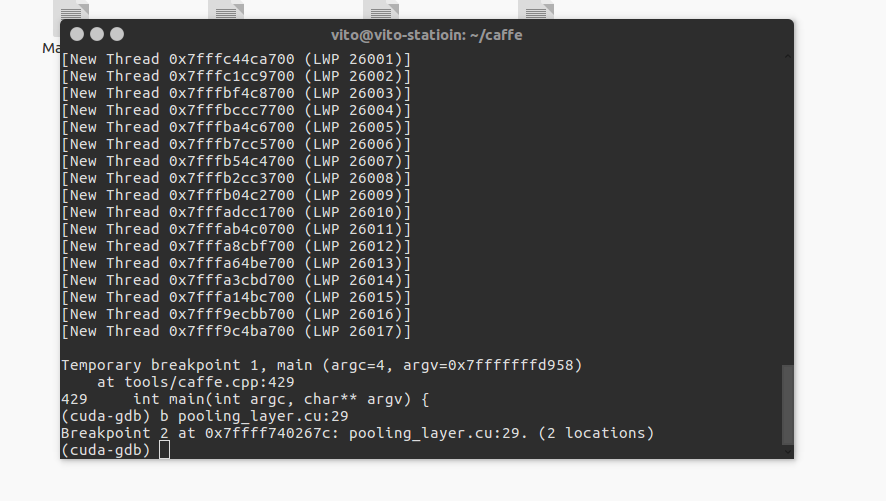
插入断点后输入 c 继续运行,稍等一会便程序便会停在断点处。如图:
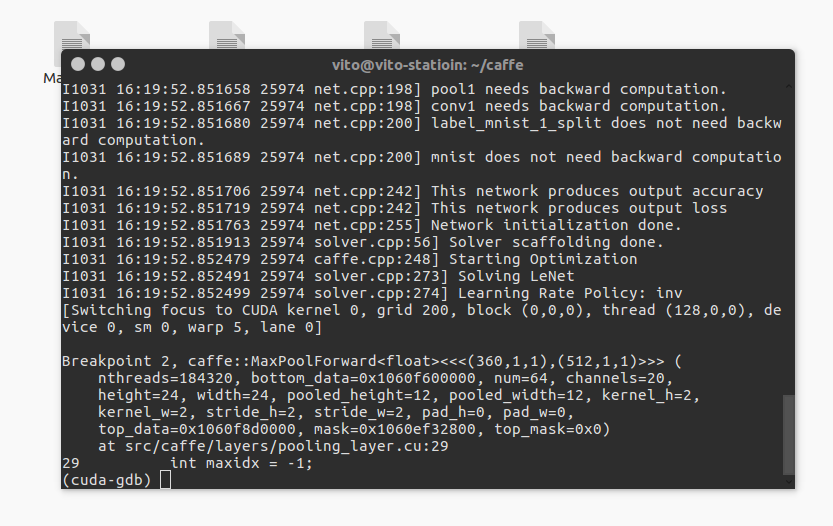
此时就可以使用p命令查看变量啦。比如我想看pw,ph,c,n,就有:
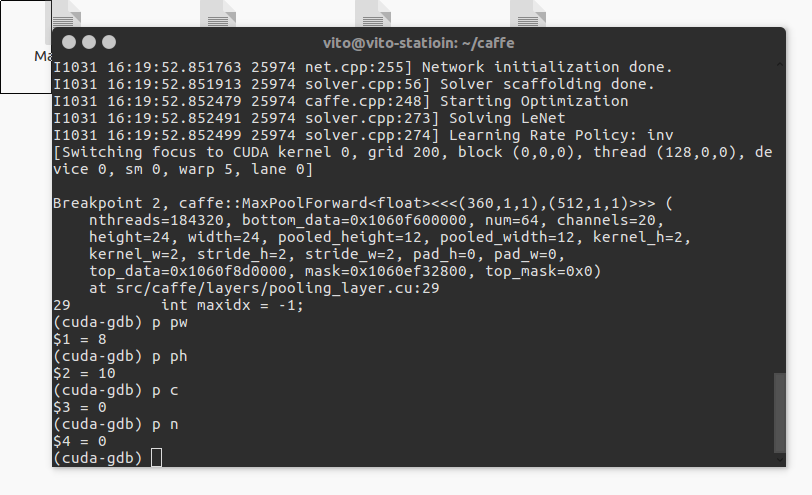
当然还可以使用很多其他命令进行各种操作,这个建议去看cuda-gdb的官方手册:点击打开链接
三、使用pycaffe接口时debug:
为了方便演示,此处将使用faster-rcnn的caffe python版本进行演示。链接:点击打开链接
同时默认已经下载好了数据并放在指定路径,可以直接训练。如需要进行此过程,请参考上链接中的readme进行配置。在配置好数据后,还应参考环境准备部分对需要调用的caffe进行re-build。
假设我们使用0号GPU在COCO数据集上训练基于VGG16的模型,正常的训练,应在$PY-FASTER-RCNN下执行:
bash ./experiments/scripts/faster_rcnn_end2end.sh 0 VGG16 coco现在为了debug 我们将./experiments/scripts/faster_rcnn_end2end.sh文件做一下修改,将其中的
time ./tools/train_net.py --gpu ${GPU_ID} \
--solver models/${PT_DIR}/${NET}/faster_rcnn_end2end/solver.prototxt \
--weights data/imagenet_models/${NET}.caffemodel \
--imdb ${TRAIN_IMDB} \
--iters ${ITERS} \
--cfg experiments/cfgs/faster_rcnn_end2end.yml \
${EXTRA_ARGS}cuda-gdb --args python ./tools/train_net.py --gpu ${GPU_ID} \
--solver models/${PT_DIR}/${NET}/faster_rcnn_end2end/solver.prototxt \
--weights data/imagenet_models/${NET}.caffemodel \
--imdb ${TRAIN_IMDB} \
--iters ${ITERS} \
--cfg experiments/cfgs/faster_rcnn_end2end.yml \
${EXTRA_ARGS}然后我们在$PY-FASTER-RCNN下执行:
bash ./experiments/scripts/faster_rcnn_end2end.sh 0 VGG16 coco
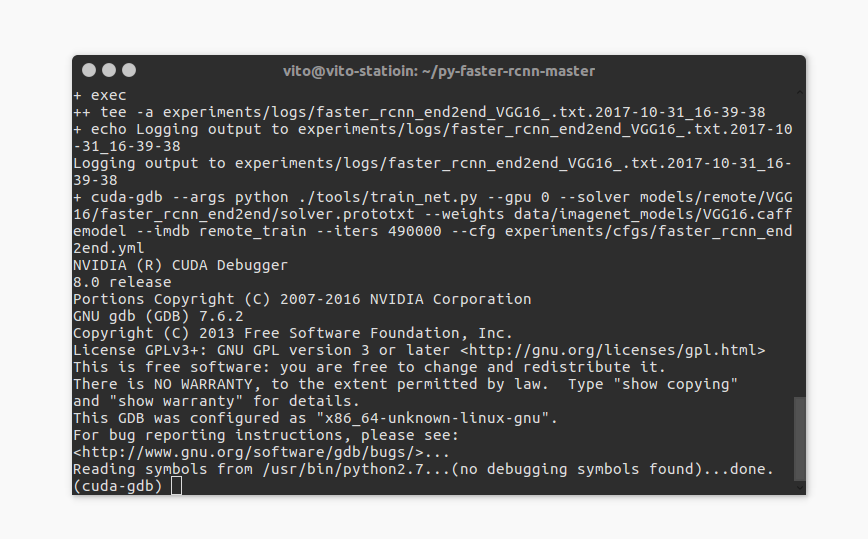
输入 start 后进入主函数。
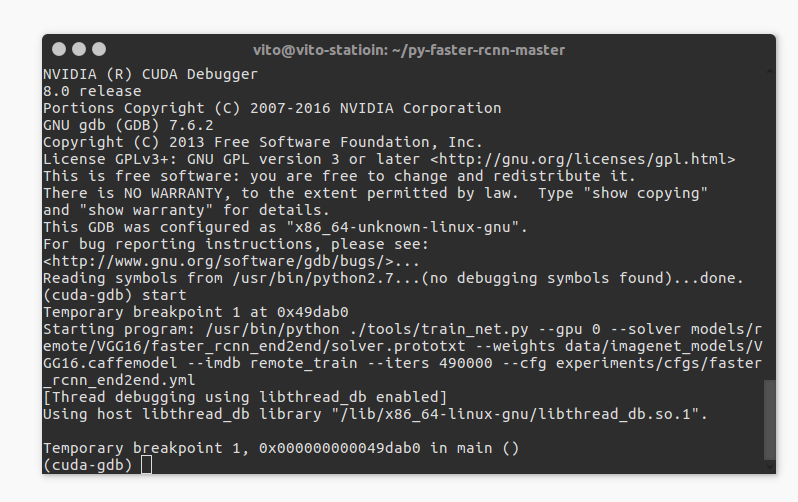
不过这次的main函数不是在命令行时的caffe.cpp文件中的main函数了,但是仍然不影响我们的debug。现在我想中断在roi_pooling层的61行,则应该输入:
b roi_pooling.cu:61No symbol table is loaded. Use the "file" command.
Make breakpoint pending on future shared library load? (y or [n])
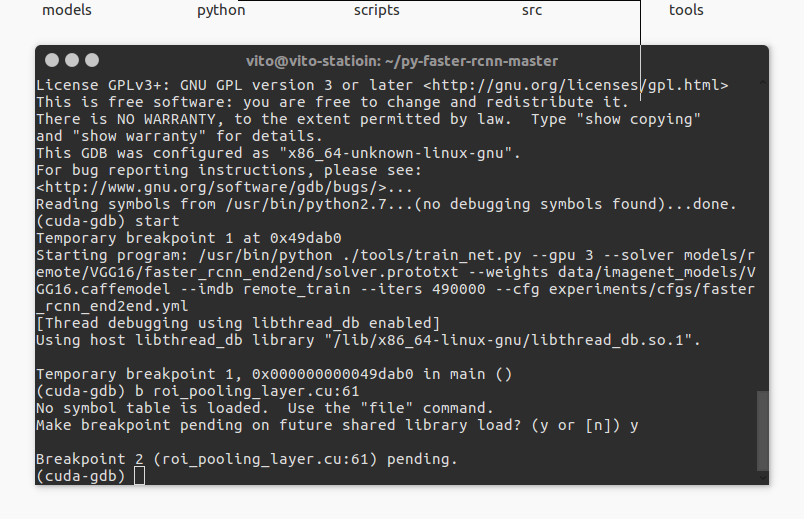
然后输入 c 继续运行,稍等一会(其实可能时很大一会,速度是真的慢),发现程序停在了断点:
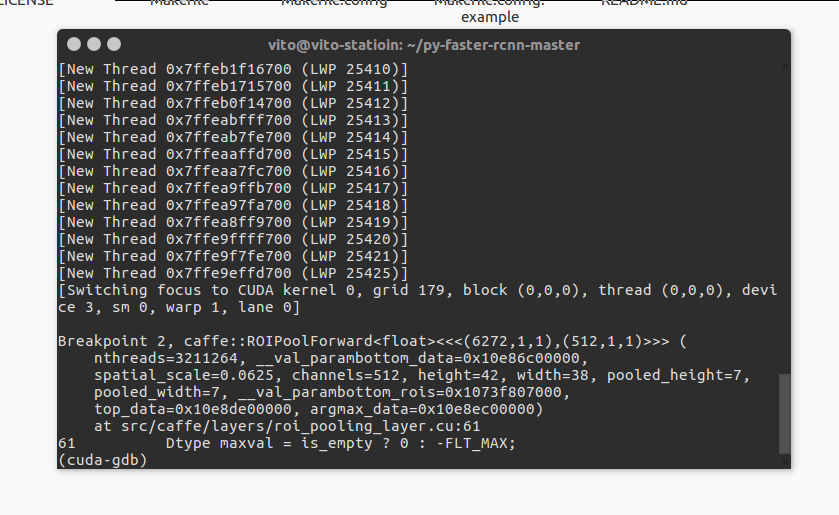
之后便可以继续各种操作啦。















 5666
5666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









