







强化学习介绍
关于强化学习
强化学习在不同的学科中其实都具有不同的存在形式

- 机器学习的分支
- 有监督学习:利用一组已知类别的训练样本调整分类器的参数,使得习得的分类器能对未知样本进行分类或预测
- 无监督学习:从无标注的数据中学习隐含的结构或模式
- 强化学习:就是学习“做什么才能使数值化的收益信号最大化”,是机器通过与环境交互来实现目标的一种计算方法
- 区别与其他机器学习算法
- 没有监督数据,只有奖励(reward)信号
- 奖励信号不一定是实时的,可能存在延迟
- 时间是一个重要因素
- 智能体(Agent)当前的动作(Action)影响后续收到的数据
- 算法的稳定性目前仍没有具体的保证
强化学习基本要素(The RL Problem)
-
奖励
- 奖励(Rt)是一个反馈信号,是一个标量
- 反应智能体(Agent)在时间步t工作得如何
- 智能体的工作就是最大化累计奖励
- 强化学习主要基于奖励假设(Reward Hypothesis)
-
奖励假设:所有问题的目标都可以被描述成最大化期望的累积奖励
-
序列决策
- 目标:选择一定的动作序列以最大化未来的总体奖励
- 智能体的行为可能是一个很长的动作序列
- 大多数时候奖励是延迟的
- 宁愿牺牲即时(短期)奖励以获得更多的长期奖励
-
有些问题,不一定“步步优”,结果就是最优的
-
智能体
-
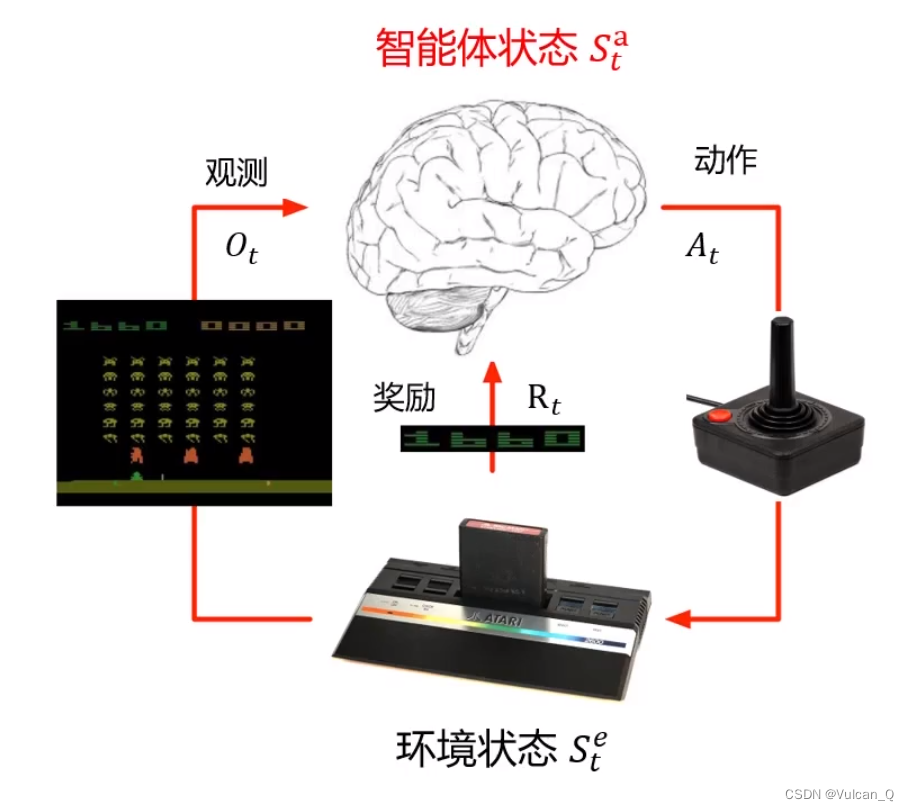
智能体与环境
-
智能体不是独立存在的,它需要与环境相互作用

- 智能体在每个时间步t:接收观测信息(observation)Ot、接收标量奖励信号Rt、执行动作(Action)At
- 环境:接收动作 At,产生观测 Ot+1、产生标量奖励信号 Rt+1
-
智能体结合了当前时间步长的奖励与观测信息后,完成了动作的执行,动作又会对下一个时间步长的环境产生影响,进而环境会给智能体新的观测信息与奖励。
-
-
历史与状态
- 历史是观测、行动和奖励的序列

- 根据历史可以决定接下来会发生什么,智能体选择行动,环境选择观测及奖励
- 状态是一种用于确定接下来会发生的事情(行动、观察、奖励)的信息
- 状态是关于历史的函数
-
环境状态
- 环境状态是环境内部的状态 ,用来确定下一个观测/奖励
- 环境状态通常对智能体是不可见的
- 即是环境状态可见,大都包含大量不相关的信息
-
智能体状态
- 是智能体内部对信息的表达,包括智能体可以使用的、决定未来动作的所有信息,是强化学习算法使用的信息
- 智能体状态时历史的函数
-
信息状态(Information State)
-
信息状态,也叫马尔科夫状态(Markov State),包含了历史上所有有用的信息

-
如果给定当前时刻的状态,将来与历史无关:

-

状态定义 状态定义是强化学习中极为关键的概念
- 完全可观测的环境(Fully Observation Environments)
- 完全可观测:智能体可以直接观察到全部环境状态

- 智能体状态 = 环境状态 = 信息状态
- 正式地说,这是马尔科夫决策过程(MDP)
- 完全可观测:智能体可以直接观察到全部环境状态
- 部分可观测的环境(Partially Observable Environments)
- 部分可观测:智能体可以观测到环境的部分
- 智能体状态不等于环境状态
- 正式的说,这是部分可观测马尔科夫决策过程(POMDP)
智能体组成
强化学习智能体由下述三个组件中的一个或多个组成:
- 策略
- 是从状态到行动的映射
- 确定性策略:a = π(s),将状态s映射为动作a
- 随机策略:
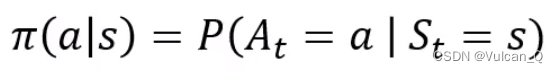
- 价值函数
- 价值函数是对于未来积累奖励的预测
- 用于评估在给定的策略下状态的好坏
- 可用于选择动作:

- 模型
- 模型用于模拟环境的行为,建模环境的动态特征
- 【解决问题一】:状态转移问题:用来预测环境的下一个状态:

- 【解决问题二】:奖励:预测环境给出的下一个即时奖励:

- 环境真实的运行机制通常不称为模型,而称为环境动力学
- 模型并不能立即给我们一个好的策略
智能体分类
分类基准:
Or
Else

强化学习问题
- 学习(Learning)与规划(Planning)
-
序列决策中的两个基础问题
- 强化学习:环境初始未知,智能体不断与环境交互,智能体提升它的策略
-
强化学习是一种试错的学习过程,更强调与环境的交互,而规划问题更多则往往已知了环境的模型,不需要与环境进行交互
- 规划:环境模型已知,智能体根据Model进行计算(不进行额外的交互),智能体提升它的策略
-
- 探索(Exploration)和利用(Exploitation)
- 探索会发现有关环境的更多信息,有选择地放弃某些奖励
- 利用已知信息来最大化回报,强调开发利用已有的信息
- 探索和利用是决策时需要平衡的两个方面
- 预测与控制
- 预测:评估未来;策略已给定
- 控制:最大化未来;找到最优策略














 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









