







什么是卷积?
卷积就是 通过两个函数生成第三个函数的 一种数学运算 其本质是一种特殊的积分变换
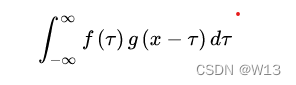
公式就是上面那样。看着很抽象。用王木头的话来解释还不错。一个人一整天24小时都在吃东西
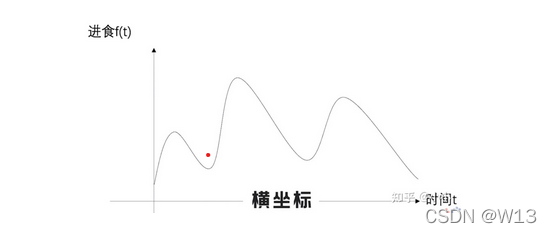
横坐标是时间 纵坐标是该时刻的进食量。吃进去的东西要消化
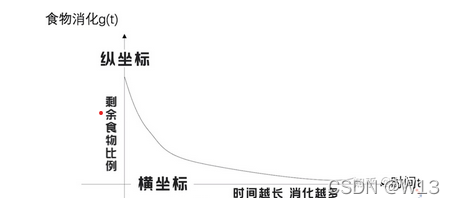
横坐标是时间 纵坐标是该时刻的该食物剩余的比例。比如我在10点吃了 (两个面包和一包牛奶)然后在下午两点剩下的就是40%的(面包牛奶)。f(x)*g(t-x)就是表示在t时刻 我在x时刻吃下去的东西还剩多少。那我们如果要求在 t时刻 胃里面还有多少东西 那就是每个x时候吃下去的东西,到t的时候还剩多少的和。有点绕,就是积分嘛。比如:我在7点吃一碗粥,8点吃了一包薯片,那我要知道9点我胃里面剩下多少东西,就是要求胃里面还有多少薯片 多少粥,然后加起来。前面说啦,这个人每时每刻都在吃东西。所以,就是
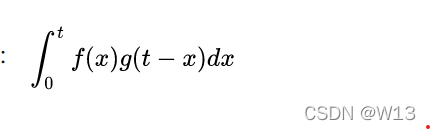
但是这不就是一个积分嘛,怎么会叫卷积。其实可以这样看。
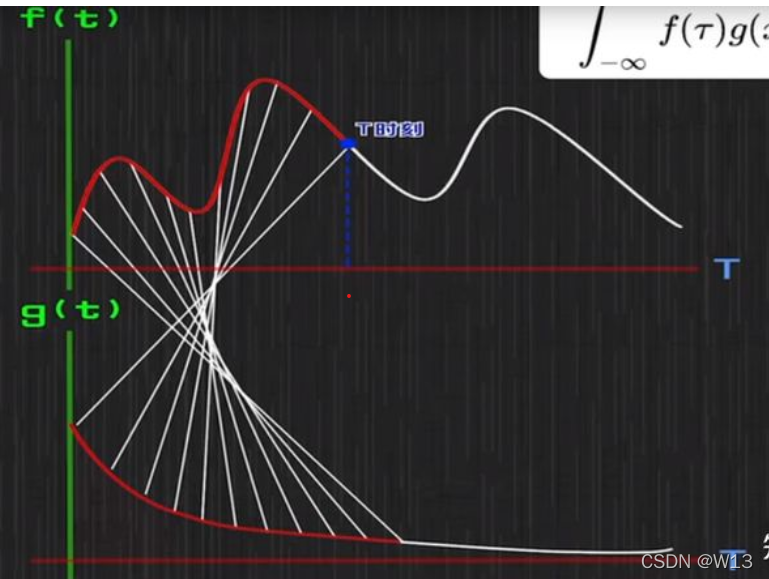 在每个T时刻,gx和fx都能对上,因为gx表示你还剩多少食物嘛。这样就卷起来了,哈哈哈哈哈,白线卷着。
在每个T时刻,gx和fx都能对上,因为gx表示你还剩多少食物嘛。这样就卷起来了,哈哈哈哈哈,白线卷着。
总结一下:一个系统的不稳定输入,输出是稳定的,就可以用卷积来求存量。消化稳定,吃多少不一定,剩下多少就可以求。
现在我们抽象一下,不再是单单吃饭了。还有这样看,你要求一个时刻t的结果,你就应该考虑在这之前,每个时刻发生的事,对t的影响。这样也是用卷积了。
卷积作用在图像上
图像的卷积操作就是
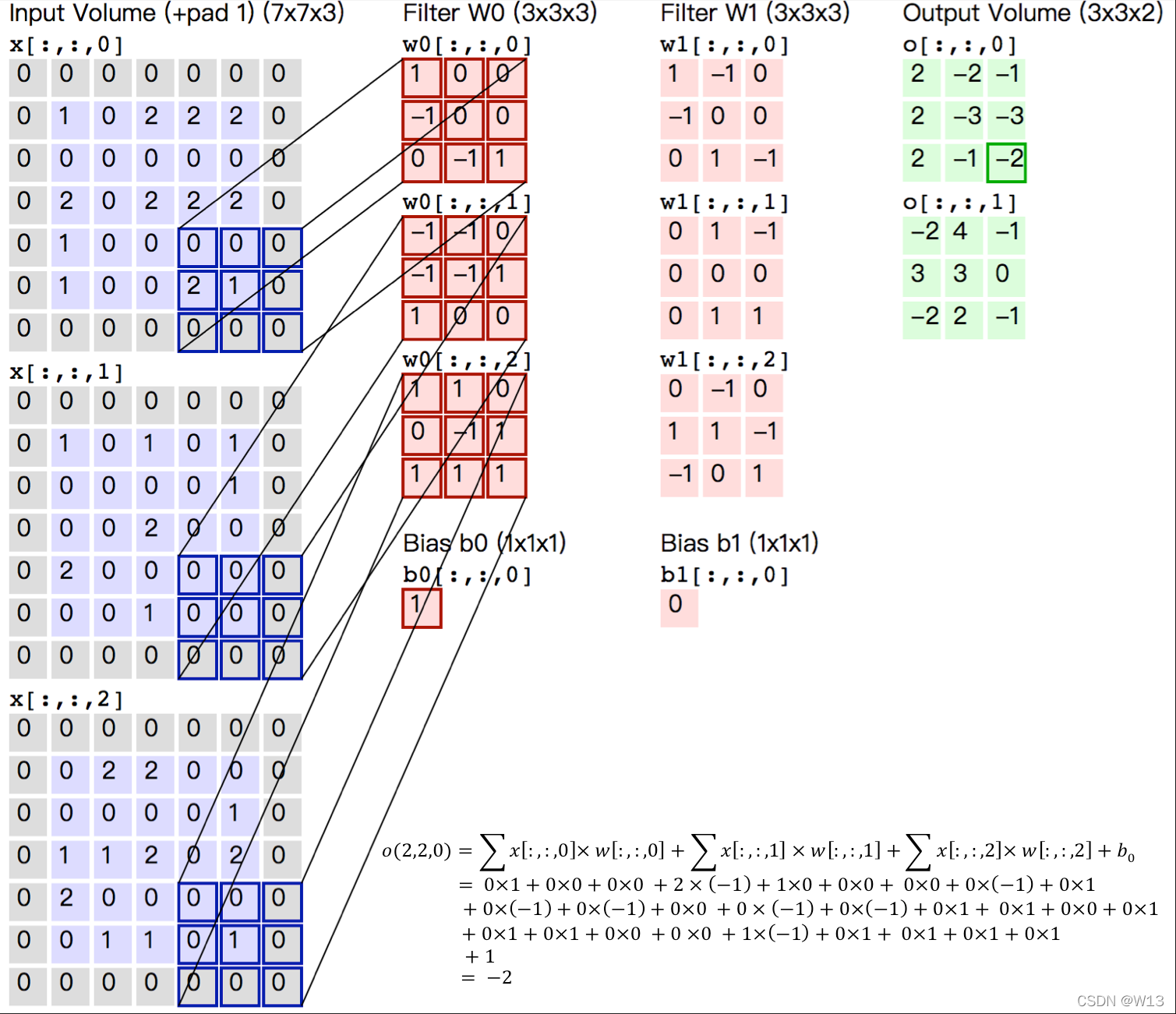 他也是先乘起来,再相加起来。那要怎么和卷积对应上呢?可以把图像看成不稳定的输入,卷积核看成稳定的输出。结果就是那一圈的像素点带来的影响。
他也是先乘起来,再相加起来。那要怎么和卷积对应上呢?可以把图像看成不稳定的输入,卷积核看成稳定的输出。结果就是那一圈的像素点带来的影响。
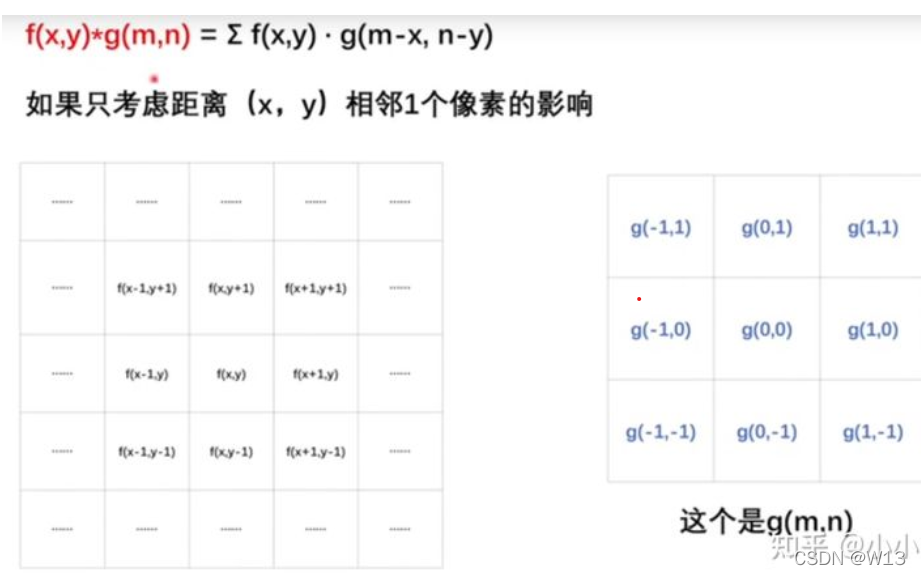 由上面的公式可以知道 fx和gx中的括号相加可以消掉 变量x,即fx * g(t-x)中的x和t-x相加剩下t。那么二维上的也一样,而g(m,n)要转180°就可满足卷积的形式了。但是其实图像卷积核g在使用时并没有这样转一下。
由上面的公式可以知道 fx和gx中的括号相加可以消掉 变量x,即fx * g(t-x)中的x和t-x相加剩下t。那么二维上的也一样,而g(m,n)要转180°就可满足卷积的形式了。但是其实图像卷积核g在使用时并没有这样转一下。
卷积的工作
对于一张图
 人眼看上去很容易辨认 都是x 但是计算机只有一堆的1 -1它并不懂。计算机进行图像识别的关键就是在于挑出图像的局部特征
人眼看上去很容易辨认 都是x 但是计算机只有一堆的1 -1它并不懂。计算机进行图像识别的关键就是在于挑出图像的局部特征
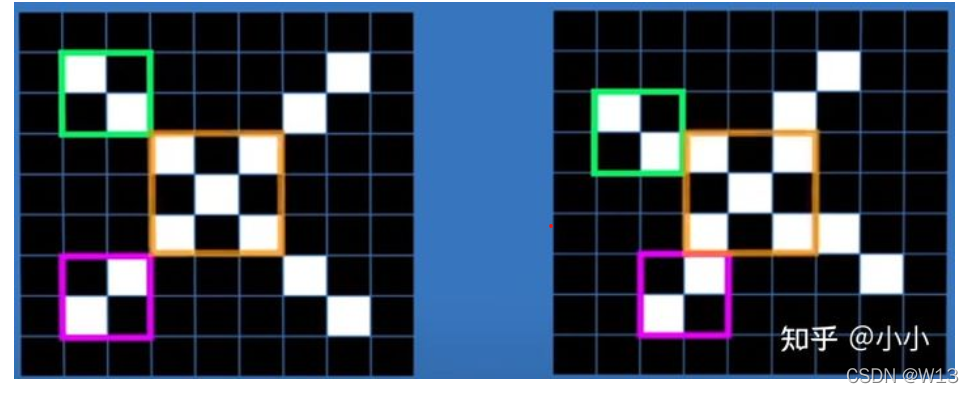 我们可以用特征当作卷积核,用来过滤图像中的信息
我们可以用特征当作卷积核,用来过滤图像中的信息 得到的就是特征图特征图中的值越大,表示和卷积核越像。
得到的就是特征图特征图中的值越大,表示和卷积核越像。
卷积网络的实现
那要怎么得到最后是x还是别的呢。那就是卷积网络的架构了。
#一张图 图片是9*9一个通道的
input = torch.randn((3,1,9,9))
kernel = torch.tensor([[[-1,-1,1],[-1,1,-1],[1,-1,-1]]])
# 卷积层
def covd2(input,kernel):
batch = input.shape[0]
chenal = input.shape[1]
result = torch.zeros((batch,chenal,input.shape[2]-kernel.shape[1]+1,input.shape[3]-kernel.shape[2]+1))
for i in range(batch):
img = input[i]
# print(img)
for c in range(chenal):
c_in = img[c]
x = c_in.shape[0]
y = c_in.shape[1]
for t in range(result.shape[-2]):
for r in range(result.shape[-1]):
result[i,c,t,r] = (c_in[t:t+kernel.shape[1],r:r+kernel.shape[2]]*kernel).sum()
return result
covd2(input,kernel).shape
# torch.Size([3, 1, 7, 7])
#池化层
def pooling2d(input,kernel,seg='max'):
batch = input.shape[0]
chenal = input.shape[1]
result = torch.zeros((batch,chenal,input.shape[2]-kernel.shape[1]+1,input.shape[3]-kernel.shape[2]+1))
print(result.shape)
for i in range(batch):
img = input[i]
# print(img)
for c in range(chenal):
k = kernel[c]
c_in = img[c]
x = c_in.shape[0]
y = c_in.shape[1]
# print(c_in.shape)
for t in range(result.shape[-2]):
for r in range(result.shape[-1]):
if seg =='max':
#print("img:",i,c_in[t:t+kernel.shape[1],r:r+kernel.shape[2]])
result[i,c,t,r] = (c_in[t:t+kernel.shape[1],r:r+kernel.shape[2]]).max()
return result
pooling2d(input,kernel)
多输入通道和多输出通道
其实一张图片包括多个通道 RGB 3个通道 我们需要分别对 每个通道的 2维矩阵 进行卷积 比如我们图片的大小是 3224224 那我们就可以用 333 即对每一个224224 用33 卷积核进行计算 然后最后得到一个 224-3+1=222 222*222 大小的特征图。222 就是 假设输入形状是nh×nw,卷积核窗口形状是kh×kw,如果在高的两侧一共填充ph行,在宽的两侧一共填充pw列,一般来说,当高上步幅为sh,宽上步幅为sw时,那么输出形状将会是
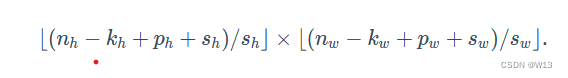
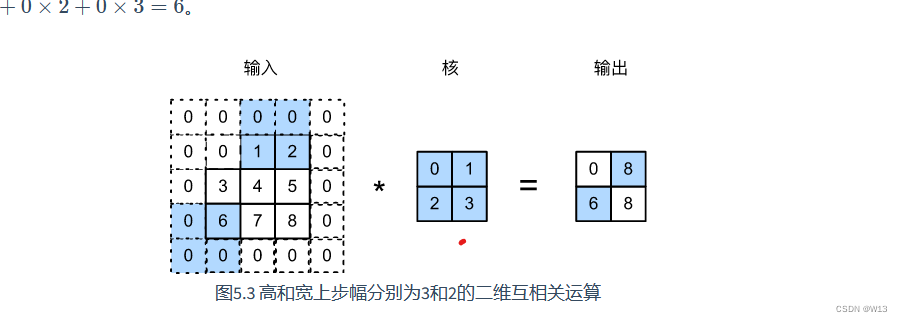 其实padding可以保证输出的维度不变
其实padding可以保证输出的维度不变
def padding(input_array, zp):
"""
:param input_array:
:param zp:
:return:
"""
if zp == 0:
return input_array
else:
if input_array.ndim == 3:
input_width = input_array.shape[2]
input_height = input_array.shape[1]
input_depth = input_array.shape[0]
#先生成一个 相应维度的 矩阵 然后 赋值
padded_array = np.zeros(
(input_depth,input_height+2*zp,input_width+2*zp)
)
padded_array[:,zp:zp+input_height,zp:zp+input_width]=input_array
return padded_array
elif input_array.ndim == 2:
input_width = input_array.shape[1]
input_height = input_array.shape[0]
#先生成一个 相应维度的 矩阵 然后 赋值
padded_array = np.zeros(
(input_height+2*zp,input_width+2*zp)
)
padded_array[zp:zp+input_height,zp:zp+input_width] = input_array
return padded_array
这就是 多输入通道 最后输出一个通道
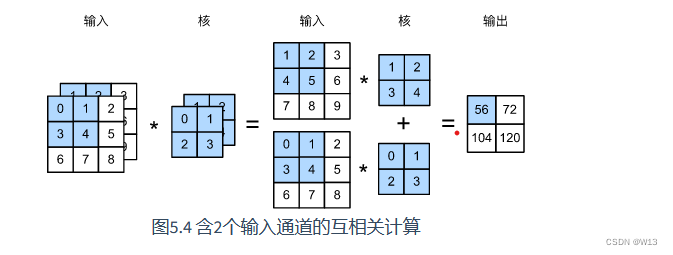
那如果要 输出多个通道呢 就是 用多组的 2* 2 * 2 嘛。比如我们再拿两个 2*2 的来计算 就会得到另外一个特征图。所以 要输出多少个通道就可以用 多少组卷积核 。每一组的个数和 输入的通道一样。
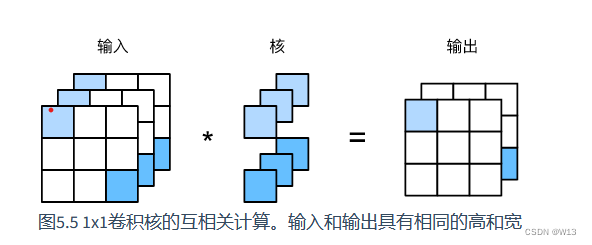
1*1卷积
值得注意的是,输入和输出具有相同的高和宽。输出中的每个元素来自输入中在高和宽上相同位置的元素在不同通道之间的按权重累加。假设我们将通道维当作特征维,将高和宽维度上的元素当成数据样本,那么1×1卷积层的作用与全连接层等价。
卷积的反向传播
这个还没懂 后面补上 只是知道了 池化层的反向传播 。因为你如果是最大池化层 你就是直接记住原来的max的值的位置 然后 因为是 y=x的映射 你就求导完就是 1.别的都是0 池化层没有激活函数 可以直接传。而对于 conv 比较困难 还不会。
# max avg
[1,0,0] [0.5,0.5]
[0,0,0] [0.5,0.5]
[0,0,0]
2022/5/16反向传播补上
其实计算 卷积核的梯度很好理解 因为就是要优化卷积核 但是 特征图的梯度也要计算 因为特征图是 上一层传下来的 反向传播回去 X的梯度 因为是求导。


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









