







 本文介绍了卷积神经网络(CNNs)的基本结构和原理,包括输入层、隐层(卷积、ReLU和池化操作)、输出层的详细解析,并探讨了ReLU激活函数的优势。此外,还讨论了CNNs在图像识别和NLP领域的应用,以及通过局部感知野和权值共享降低模型复杂度的方法。最后,提到了CNNs的可视化和参考资源。
本文介绍了卷积神经网络(CNNs)的基本结构和原理,包括输入层、隐层(卷积、ReLU和池化操作)、输出层的详细解析,并探讨了ReLU激活函数的优势。此外,还讨论了CNNs在图像识别和NLP领域的应用,以及通过局部感知野和权值共享降低模型复杂度的方法。最后,提到了CNNs的可视化和参考资源。
孔子说过,温故而知新,时隔俩月再重看CNNs,当时不太了解的地方,又有了新的理解与体会,特此记录下来。文章图片及部分素材均来自网络,侵权请告知。
卷积神经网络(Convolutinal Neural Networks)是非常强大的一种深度神经网络,它在图片的识别分类、NLP句子分类等方面已经获得了巨大的成功,也被广泛使用于工业界,例如谷歌将它用于图片搜索、亚马逊将它用于商品推荐等。
首先给出几个CNNs应用的两个例子如下:
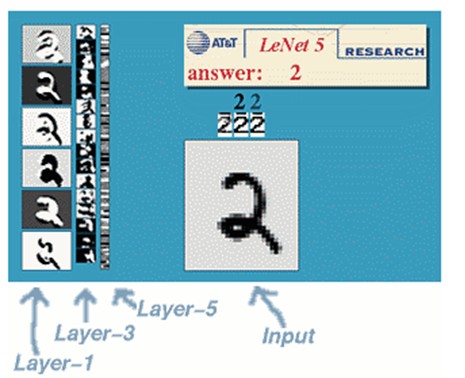
(1)、手写体数字识别

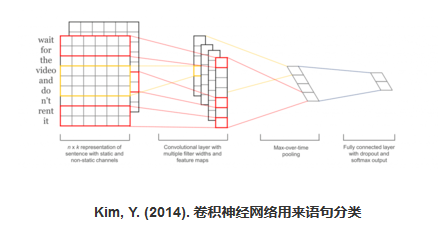
(2)、对象识别 [1]
可以看到CNNs可以被用来做许多图像与NLP的事情,且效果都很不错。那么CNNs的工作框架是什么样子呢?
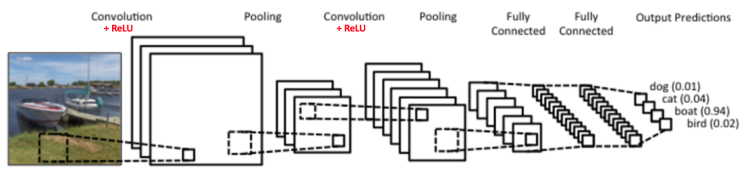
由上可以看到,CNNs的输入层为原始图片,当然,在计算机中图片就是用构成像素点的多维矩阵来表示了。然后中间层包括若干层的卷积+ReLU+池化,和若干层的全连接层,这一部分是CNNs的核心,是用来对特征进行学习和组合的,最终会学到一些强特征,具体是如何学习到的会在下面给出。最后会利用中间层学到的强特征做为输入通过softmax函数来得到输出标记。
下面就针对上面给出的CNNs框架一层层进行解析。
1、输入层
输入层没有什么可讲的,就是将图片解析成由像素值表示的多维矩阵即可,如下:
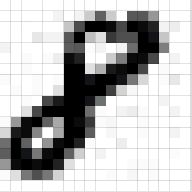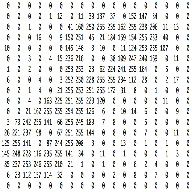
通道为1也就是厚度为1的图称为灰度图,也即上图。若是由RGB表示的图片则是一个三维矩阵表示的形式,其中第三维长度为3,包含了RGB每个通道下的信息。
2、隐层
CNNs隐层与ANN相比,不仅增加了隐层的层数,而且在结构上增加了convolution卷积、ReLU线性修正单元和pooling池化的操作。其中,卷积的作用是用来过滤特征,ReLu作为CNNs中的激活函数,作用稍后再说,pooling的作用是用来降低维度并提高模型的容错性,如保证原图片的轻微扭曲旋转并不会对模型产生影响。
由于CNNs与ANN相比,模型中包含的参数多了很多,若是直接使用基于全连接的神经网络来处理,会因为参数太多而根本无法训练出来。那有没有一些方法降低模型的参数数目呢?答案就是局部感知野和权值共享,中间层的操作也就是利用这些trick来实现降低参数数目的目的。
首先解释一下什么是局部感知野 [2] :一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
举个例子来讲就是,一个32
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









