






f=open("text.txt",'w') #打开文件,如果文件不存在,系统将新建一个文件
f.close() #关闭文件
f=open('text.txt','r') #阅读文件,如果文件不存在,会报错
f=open("text.txt",'w')
f.write('hello world) #在text.txt文件中写具体内容
f=open('text.txt','r')
a=f.read(5)
print(a)
f.close()
输出 hello
#分别阅读 所输出的内容不一样
f=open("text.txt",'r')
a=f.read(5)
print(a)
b=f.read(5)
print(b)
f.close()
输出 hello
worl、
#还能阅读行数
f=open("text.txt",'r')
content=f.readline()
print(content)
f.close()
输出 hello world
#能够分别阅读所有的内容
f=open("text.txt",'w')
f.write('hello world'\n'hello world')
f.close()
f=open("text.txt",'r')
content=f.readlines()
i=1
for temp in content:
print(temp)
print('%d,%s'%(i,temp)
i+=1
f.close()
输出结果 1:hello world
2: hello world
文件还可以进行更改
import os
os.rename('text.txt','one.txt') #text.txt 文件名被更改2.异常处理
print('text------1')
print('text------2')
print(num) #发生错误时 将不执行下面的命令
print('文件错误')
输出 text----------1
text----------2
出现报错
#消除错误
try:
print('text------1')
print('text------2')
print(num)
print('文件错误')
except NameError: 输出将不会报错
pass
#处理多项错误
try:
print('text------1')
print('text------2')
f=open('123.txt','r')
print(num)
print('文件错误')
except (NameError,IOError): #输出时不会报错num 和123.txt #NameError,IOError 一起可以用Exception来表示
pass
#如果想要显示具体错误原因,可以添加 as result
#如:
try:
print('text------1')
print('text------2')
print(num) #发生错误时 将不执行下面的命令
f=open('123.txt''r')
except Exception as result: #具体结果将会显示出现num没被定义 123.txt没找到
print('文件错误')
print(result)
3.经典例题
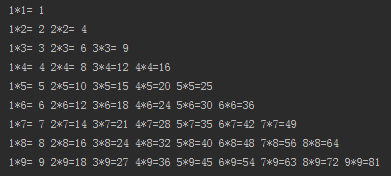
99乘法表
i=1
while i<10:
j=1
while j<=i:
print("%d*%d=%2d"%(j,i,j*i),end=' ')
j+=1
print("")
i+=1输出结果
商品
products=[['iphone',6888],['Macpro',14880],['小米',2488],['office',31],['book',50],['Nike',699]]
a=len(products)
for i in range(0,a):
print(i,end='\t')
print(products[i][0],products[i][1])输出结果:
0 iphone 6888
1 Macpro 14880
2 小米 2488
3 office 31
4 book 50
5 Nike 6993.python爬虫
定义:网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
来干什么:可以代替人们自动地在互联网中进行数据信息的采集与整理,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛,如果它遇到自己的猎物(所需要的资源),那么它就会将其抓取下来。
本质:分布式只是提高爬虫功能和效率的一个环节而已,它从来不是爬虫的本质东西。爬虫的本质是网络请求和数据处理,如何稳定地访问网页拿到数据,如何精准地提取出高质量的数据才是核心问题。
基本流程:
准备工作:分析目标网页,学习编程基础规范
获取数据 :通过http库向目标站发起请求,请求包含header等信息
新的内容:得到的可能是HTTP.json等格式,可以用页面分析库,正则表达式等来进行解析。
保存数据:可以保存到不同类型的文本 如excel等















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









