







识别精度主要是由召回率(recall)和精度(precision)表示的。通过绘制precision-recall 曲线,该曲线下方的面积越大,识别精度也就越高,反之越低。
在说明 recall 和 precision 计算公式之前需要先介绍几个数据定义。
在一个数据集检测中,会产生四类检测结果:
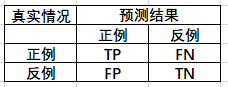
TP、TN 、FP 、FN:
T ——true 表示正确
F——false 表示错误
P—— positive 表示积极的,看成正例
N——negative 表示消极的,看成负例
我的理解:后面为预测结果,前面是预测结果的正确性。如:
T P—— 预测为 P (正例), 预测对了, 本来是正样本,检测为正样本(真阳性)。
T N—— 预测为 N (负例), 预测对了, 本来是负样本,检测为负样本(真阴性)。
F P—— 预测为 P (正例), 预测错了, 本来是负样本,检测为正样本(假阳性)。
F N—— 预测为 N (负例), 预测错了, 本来是正样本,检测为负样本(假阴性)。
TP+FP+TN+FN:样本总数。
TP+FN:实际正样本数。
TP+FP:预测结果为正样本的总数,包括预测正确的和错误的。
FP+TN:实际负样本数。
TN+FN:预测结果为负样本的总数,包括预测正确的和错误的
四种情形组成的混淆矩阵如下:
召回率(Recall):
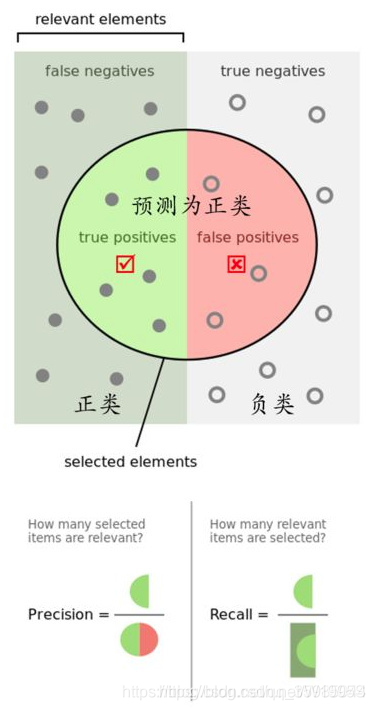
表示的是样本中的正例有多少被预测正确了(找得全)所有正例中被正确预测出来的比例。
用途:用于评估检测器对所有待检测目标的检测覆盖率
针对数据集中的所有正例(TP+FN)而言,模型正确判断出的正例(TP)占数据集中所有正例的比例。FN表示被模型误认为是负例但实际是正例的数据,召回率也叫查全率,以物体检测为例,我们往往把图片中的物体作为正例,此时召回率高代表着模型可以找出图片中更多的物体

精确率(Precision):
表示的是预测为正的样本中有多少是真正的正样本(找得对)。预测结果中真正的正例的比例。
用途:用于评估检测器在检测成功基础上的正确率
针对模型判断出的所有正例(TP+FP)而言,其中真正例(TP)占的比例。精确率也叫查准率,还是以物体检测为例,精确率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体

也就是说 recall 表示在整个检测结果中有用部分占整个数据集有用部分的比重,precision 表示在整个检测结果中有用部分占整个检测结果为有用的比重。虽然希望两个指标都能越高越好,但是这两个指标在被某些情况下存在着矛盾,所以在实际检测场景中需要根据自己的判断选择取舍或者绘制 precision-recall 曲线(简称PR曲线)帮助分析。
放一张较为经典理解上述公式的图:
还有一个指标:
准确率(Accuracy): 模型判断正确的数据(TP+TN)占总数据的比例

直观上说,我们用上述标准来衡量目标检测的好坏似乎已经够了。然而,目标检测问题中的模型的分类和定位都需要进行评估,每个图像都可能具有不同类别的不同目标,因此,在图像分类问题中所使用的标准度量不能直接应用于目标检测问题。
缺点:准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。

















 2945
2945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









