







【参加CUDA线上训练营】共享内存实例1:矩阵转置实现及其优化②
本文参考Nvidia官方blog[An Efficient Matrix Transpose in CUDA C/C++及其对应的github代码transpose.cu学习下共享内存(Shared Memory)的使用,感受下其加速效果。
使用的共享内存大小为32*32的tile,一个block中定义的线程数32*8。这就意味着需要循环4次才能对tile进行一次读写操作。
const int TILE_DIM = 32;
const int BLOCK_ROWS = 8;
dim3 dimGrid(nx/TILE_DIM, ny/TILE_DIM, 1); //设置block个数
dim3 dimBlock(TILE_DIM, BLOCK_ROWS, 1);//设置block中的线程数位32*8
1.不使用Shared Memory
__global__ void transposeNaive(float *odata, const float *idata)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[x*width + (y+j)] = idata[(y+j)*width + x];
}
可以看出程序的工作主要是将y维度8线程,分四次,赋值给转置后的矩阵。
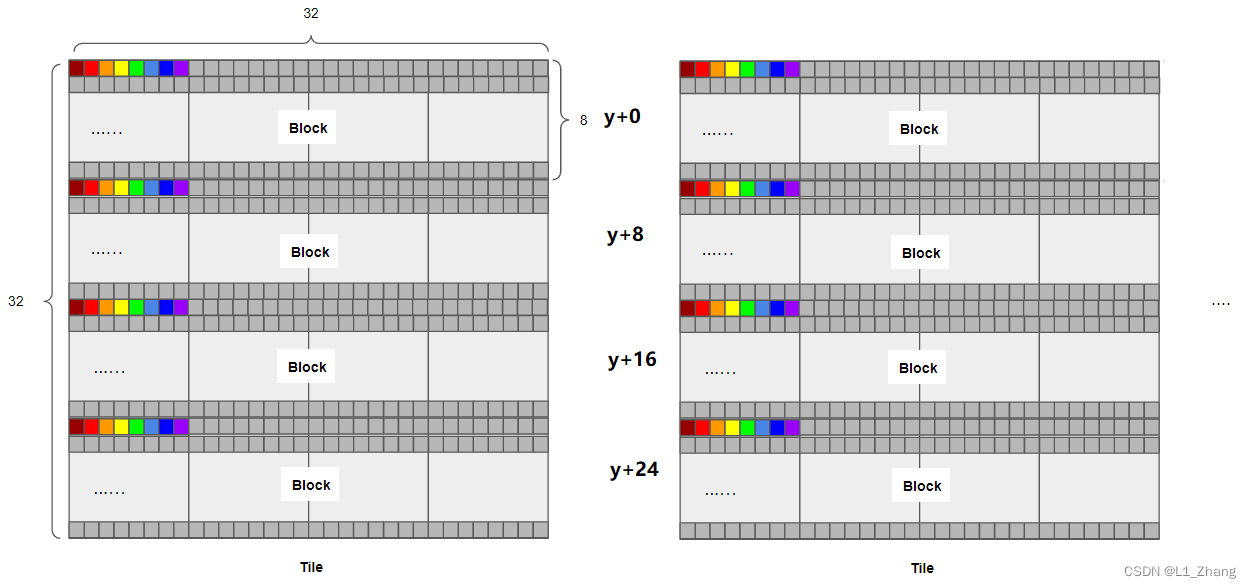
2.使用Shared Memory
__global__ void transposeCoalesced(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // transpose block offset
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
可以看出程序的工作主要是先将y维度4个8线程对应的元素组装成32*32的子矩阵,存入共享内存tile中,再进行转置操作。
从下图可以看出,矩阵分块求转置的过程,只是将各block的x方向与y方向的id对调下,这样就比较容易理解了。
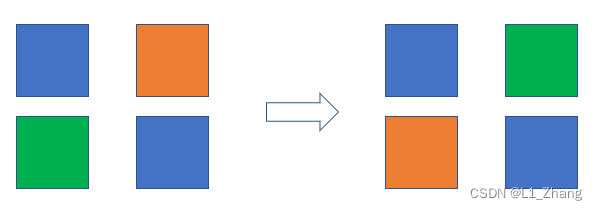
而tile内部的交换通过下列语句实现:
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
3.使用Shared Memory,并加入No Bank Conflicts
Bank Conflicts是指,当一个warp中的不同线程访问一个bank中的不同的字地址时,就会发生bank冲突。
解决办法是通过memory padding操作。
这块理解的很浅,后续有机会深入理解后再补充。
// No bank-conflict transpose
// Same as transposeCoalesced except the first tile dimension is padded
// to avoid shared memory bank conflicts.
__global__ void transposeNoBankConflicts(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM][TILE_DIM+1];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // transpose block offset
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
可见唯一的差别就在于这一句:
__shared__ float tile[TILE_DIM][TILE_DIM+1];
4.效果对比
此代码在我的jetson nano上运行结果如下:

使用了shared memory及no_bank_conflicts优化后,提升明显。
参考文献
[1] An Efficient Matrix Transpose in CUDA C/C++
[2] NVIDIA-developer-blog github:transpose.cu
[3] CUDA矩阵转置优化















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











