







KNN 算法,或者称 k最邻近算法,是 有监督学习 中的 分类算法 。它可以用于分类或回归问题,但它通常用作分类算法。通常根据距离来进行实现数据类别的划分。
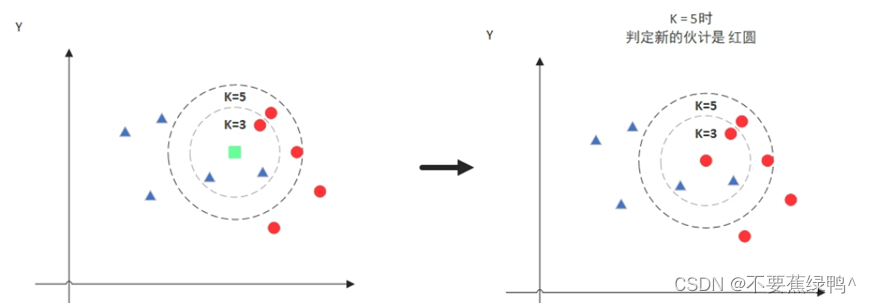 通过k个最近距离类别属性的数量,来进行判定该类别从属哪一个类别,列如当k=3时那么KNN算法就会找到与它距离最近的三个点,看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
通过k个最近距离类别属性的数量,来进行判定该类别从属哪一个类别,列如当k=3时那么KNN算法就会找到与它距离最近的三个点,看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
import numpy as np
from collections import Counter
from joblib import Parallel, delayed
from aeon.distances import (dtw_distance, ddtw_distance, lcss_distance, edr_distance, euclidean_distance, wdtw_distance)
class KNNClassifier:
def __init__(self, n_neighbors=1, metric='euclidean', n_jobs=-1, g=0.05): # 并行线程数量为-1时表示最大并行量,g权重比默认0.05
self.n_neighbors = n_neighbors
self.metric = metric
self.n_jobs = n_jobs
self.g = g
self._fit_X = None
self._fit_y = None
self._distance_cache = {}
def fit(self, X, y):
if isinstance(X[0], np.ndarray) and X[0].ndim == 2:
self._fit_X = np.array([np.array(x).flatten() for x in X])
elif isinstance(X[0], np.ndarray) and X[0].ndim == 1:
self._fit_X = np.array(X)
else:
raise ValueError("数据维度不正确或者数据类型不正确")
self._fit_y = np.array(y)
def _compute_distance(self, x1, x2):
cache_key = (tuple(x1), tuple(x2))
if cache_key in self._distance_cache:
return self._distance_cache[cache_key]
if self.metric == 'euclidean':
distance = euclidean_distance(x1, x2)
elif self.metric == 'dtw':
distance = dtw_distance(x1, x2)
elif self.metric == 'wdtw':
distance = wdtw_distance(x1, x2, g=self.g)
else:
raise ValueError(f"Unsupported metric: {self.metric}")
self._distance_cache[cache_key] = distance
return distance
def _predict_single(self, x):
distances = [self._compute_distance(x, x_train) for x_train in self._fit_X]
k_indices = np.argsort(distances)[:self.n_neighbors]
k_nearest_labels = [self._fit_y[i] for i in k_indices]
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
def predict(self, X):
if isinstance(X[0], np.ndarray) and X[0].ndim == 2:
X = [np.array(x).flatten() for x in X]
predictions = Parallel(n_jobs=self.n_jobs)(delayed(self._predict_single)(x) for x in X)
return predictions
def score(self, preds, y):
correct = sum(p == t for p, t in zip(preds, y))
return correct / len(y)
# 示例用法
if __name__ == "__main__":
# 示例时间序列数据
X_train = np.array([
[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[10, 11, 12, 13, 14],
[11, 12, 13, 14, 15]
])
y_train = [0, 0, 1, 1]
X_test = np.array([
[1, 2, 3, 4, 5],
[10, 11, 12, 13, 14]
])
y_test = [0, 1]
# 使用欧几里得距离
knn_euclidean = KNNClassifier(n_neighbors=3, metric='euclidean', n_jobs=3)
knn_euclidean.fit(X_train, y_train)
euclidean_predictions = knn_euclidean.predict(X_test)
euclidean_accuracy = knn_euclidean.score(euclidean_predictions, y_test)
print("Euclidean metric predictions:", euclidean_predictions)
print("Euclidean metric accuracy:", euclidean_accuracy)
数据中的x_train 和y_train分别表示训练集的数据和对应的标签,y_train,y_test分别表示测试集的数据和测试数据集的标签。该分类器可以结合其他库中的距离算法来进行实现数据的分类,也可以结合自定义的算法实现对于数据集的分类。对于数据集的制作可以参考UCR公共数据集的文件制作方式,亦可以自定义实现。
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











