







目录
这里,不知道为什么我的内核经常挂掉,所以在开头附上此代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" #防止内核挂掉重启1 实现一个简单的线性回归模型
要通过机器学习来解决一个特定的任务时,我们需要准备5个方面的要素:
- 数据集:收集任务相关的数据集用来进行模型训练和测试,可分为训练集、验证集和测试集;
- 模型:实现输入到输出的映射,通常为可学习的函数;
- 学习准则:模型优化的目标,通常为损失函数和正则化项的加权组合;
- 优化算法:根据学习准则优化机器学习模型的参数;
- 评价指标:用来评价学习到的机器学习模型的性能.
1.1 数据集构建
首先,我们构造一个小的回归数据集。
def linear_func(x,w=1.2,b=0.5):
y=w*x+b
return y使用paddle.rand()函数来进行随机采样输入特征x,并代入上面函数得到输出标签𝑦。
import paddle
def create_toy_data(func, interval, sample_num, noise = 0.0, add_outlier = False, outlier_ratio = 0.001):
"""
根据给定的函数,生成样本
输入:
- func:函数
- interval: x的取值范围
- sample_num: 样本数目
- noise: 噪声均方差
- add_outlier:是否生成异常值
- outlier_ratio:异常值占比
输出:
- X: 特征数据,shape=[n_samples,1]
- y: 标签数据,shape=[n_samples,1]
"""
# 均匀采样
# 使用paddle.rand生成sample_num个随机数
X = paddle.rand(shape = [sample_num]) * (interval[1]-interval[0]) + interval[0]
y = func(X)
# 生成高斯分布的标签噪声
# 使用paddle.normal生成0均值,noise标准差的数据
epsilon = paddle.normal(0,noise,paddle.to_tensor(y.shape[0]))#生成均值为0,标准差为noise,个数为sample_num的数据
y = y + epsilon
if add_outlier: # 生成额外的异常点
outlier_num = int(len(y)*outlier_ratio)
if outlier_num != 0:
# 使用paddle.randint生成服从均匀分布的、范围在[0, len(y))的随机Tensor
outlier_idx = paddle.randint(len(y),shape = [outlier_num])
y[outlier_idx] = y[outlier_idx] * 5
return X, y下面生成 150 个带噪音的样本,其中 100 个训练样本,50 个测试样本,并打印出训练数据的可视化分布。
from matplotlib import pyplot as plt # matplotlib 是 Python 的绘图库
func = linear_func
interval = (-10,10)
train_num = 100 # 训练样本数目
test_num = 50 # 测试样本数目
noise = 2 #标准差
#给定函数下生成样本数据
X_train, y_train = create_toy_data(func=func, interval=interval, sample_num=train_num, noise = noise, add_outlier = False)
X_test, y_test = create_toy_data(func=func, interval=interval, sample_num=test_num, noise = noise, add_outlier = False)
X_train_large, y_train_large = create_toy_data(func=func, interval=interval, sample_num=5000, noise = noise, add_outlier = False)
# paddle.linspace返回一个Tensor,Tensor的值为在区间start和stop上均匀间隔的num个值,输出Tensor的长度为num
X_underlying = paddle.linspace(interval[0],interval[1],train_num)
y_underlying = linear_func(X_underlying)
# 绘制数据
plt.scatter(X_train, y_train, marker='*', facecolor="none", edgecolor='#e4007f', s=50, label="train data")
plt.scatter(X_test, y_test, facecolor="none", edgecolor='#f19ec2', s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"underlying distribution")#绘制我们的线性函数
plt.legend(fontsize='x-large') # 给图像加图例
# plt.savefig('ml-vis.pdf') # 保存图像到PDF文件中
plt.show()运行结果如下:
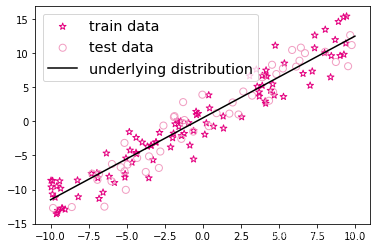
数据已经准备好了。
1.2 模型构建


shape属性是指每个维度上元素的数量,其实无非就是矩阵的运算。
import paddle
from nndl.op import Op
paddle.seed(10) #设置随机种子
# 线性算子
class Linear(Op):
def __init__(self, input_size):
"""
输入:
- input_size:模型要处理的数据特征向量长度
"""
self.input_size = input_size
# 模型参数
self.params = {}
self.params['w'] = paddle.randn(shape=[self.input_size,1],dtype='float32')
self.params['b'] = paddle.zeros(shape=[1],dtype='float32')
def __call__(self, X):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









