







MultiLabelBinarizer 说明介绍
1. MultiLabelBinarizer 是什么?
MultiLabelBinarizer是scikit-learn库中的一个用于处理多标签数据的编码器。通常用于将多标签的分类任务中的标签转化为二进制形式,便于机器学习模型的处理。该编码器的主要目标是将每个样本的多个标签转换为一个二进制数组,其中每个元素表示一个可能的标签,如果样本属于该标签则为1,否则为0。
主要用于处理什么类型的任务/问题?
MultiLabelBinarizer 主要用于处理多标签分类问题,其中一个样本可以属于多个类别。以下是一些常见的任务和问题,其中该编码方法经常被使用:
- 多标签文本分类: 当文本可以被分为多个主题或类别时,如新闻分类、电影分类等。
- 图像标注: 在图像处理中,一张图像可能包含多个对象或场景,需要将图像标注为多个标签。
- 音频分类: 对音频文件进行分类时,可能涉及到多种音频特征,例如音乐类型、语言、情感等。
- 推荐系统: 在推荐系统中,物品可以被归属到多个类别,例如一部电影可能属于多个流派。
- 生物信息学: 在生物信息学中,基因或蛋白质可能具有多个功能或属于多个通路。
- 社交媒体分析: 在分析社交媒体数据时,一篇文章、一条推文或一张照片可能涉及多个主题或标签。
2. 优缺点
优点
- 灵活性: 能够处理不同样本具有不同标签集合的情况。
- 易于使用: 提供了简单而有效的接口,易于集成到机器学习流水线中。
- 适用性广泛: 适用于多标签分类问题。
缺点
- 稀疏性: 生成的二进制矩阵可能会变得非常稀疏,特别是当类别数目较多时。
- 维度增加: 二进制矩阵的列数等于所有唯一标
- 二进制表示: 二进制表示可能不够灵活,无法表达标签之间的相对关系。
- 无法处理未知标签: 如果新数据中包含未在训练数据中出现的标签,可能导致无法正确处理这些标签。
3. 方法说明
MultiLabelBinarizer 提供了以下主要方法:
-
fit_transform(X, y=None): 该方法接受一个包含标签的列表的列表 X,对标签进行编码,并返回编码后的二进制数组。如果提供了可选的参数 y,则根据 y 中的标签进行编码。该方法是一个组合方法,包括 fit 和 transform 两个步骤。
-
fit(y): 该方法用于学习标签的编码规则,但不进行转换。通常与 transform 方法一起使用,用于对新数据进行相同的编码。
-
transform(y): 该方法将输入的标签列表转换为二进制数组。通常在已学习编码规则的情况下使用,可以通过 fit 或 fit_transform 学习规则。
-
inverse_transform(y): 该方法将二进制数组还原为原始的标签列表,用于反向转换。
4. 参考代码案例
from sklearn.preprocessing import MultiLabelBinarizer
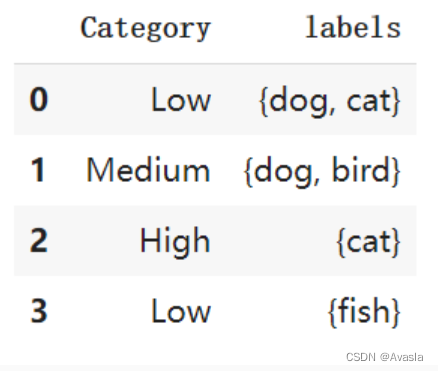
# 示例数据
data = {'Category': ['Low', 'Medium', 'High', 'Low'],
'labels':[{ 'cat', 'dog' }, { 'dog', 'bird' }, { 'cat' }, { 'fish' }]}
df = pd.DataFrame(data)
df
# 创建MultiLabelBinarizer对象并进行fit_transform
mlb = MultiLabelBinarizer()
binary_matrix = mlb.fit_transform(df.labels)
print("Classes:", mlb.classes_)
print("Transformed labels:\n", binary_labels)

#将结果转换成DF格式
mlb_df = pd.DataFrame(binary_matrix, columns=mlb.classes_, index=df.labels.index)
mlb_df
![![[Pasted image 20240115141046.png]]](https://img-blog.csdnimg.cn/direct/f6c83af1a632465ca9ed93cc2177a24c.png)
#合并
mlb_df=pd.concat([df.drop(columns='labels',axis=1),mlb_df],axis=1)
mlb_df
![![[Pasted image 20240115142016.png]]](https://img-blog.csdnimg.cn/direct/aeb86534f39945119f83e3f89c1dbc08.png)
# 进行逆变换
original_labels = mlb.inverse_transform(mlb_df.values)
#original_labels = mlb.inverse_transform(binary_matrix)
print("Inverse transformed labels:\n", original_labels)
注:mlb_df.values 和 binary_matrix是一样的

5. 适合的模型类型
MultiLabelBinarizer 主要适用于多标签分类问题,特别是在需要将标签转换为二进制形式以供模型处理的情况下。它常与支持多标签输出的分类模型一起使用,如多标签文本分类、图像标注等任务。一些适合的模型类型包括多标签的逻辑回归、支持向量机和神经网络等。















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









