







实际运行结果:
- 上面的为最近邻分类器,其中红框表示最近邻搜索的预测结果。
- 下方的为SVM:橙色框表示SVM的预测结果。其中,最红的框表示SVM预测的最高得分的预测结果。

使用经典图像处理的方法开发简单人物检测器,其大致步骤如下:
- 获取正样本训练数据,即包含人的图像块。获取负样本训练数据,即不包含(完整)人的图像块。
- 提取方向梯度直方图(HoG)特征,以获取比原始像素值更稳健的图像描述符。
- 使用这些训练数据训练我们选择的分类器。使用一个简单的最近邻搜索或支持向量机。
- 使用滑动窗口方法从我们的验证图像中提取图像块和HoG特征,并在每个图像块上评估分类器,以便在验证图像中检测出人。
1 获取训练图像块
通过已经有的图像及数据,我们可以获得正样本训练数据,即包含人的图像块,使用PIL库进行裁剪
assert isinstance(img, Image.Image), 'img needs to be PIL.Image.Image'
crop = img.crop(box)
patch = crop.resize(patch_size)
return patch
再通过将给定大小的框放置在图像中的随机位置,获得负样本训练数据;
x = np.random.randint(0, W - boxsize[0])
y = np.random.randint(0, H - boxsize[1])
box = [x, y, x + boxsize[0], y + boxsize[1]]
为了包括更具挑战性的负样本,我们需要在已有的边界框基础上添加一个小的随机偏移量,从而构建出与正样本训练数据相似的困难的负样本。
off_x = np.random.randint(min_offset, max(2, max_offset_w))
off_y = np.random.randint(min_offset, max(2, max_offset_h))
off_box = [box[0] + off_x, box[1] + off_y, box[2] + off_x, box[3] + off_y]

2 提取 HoG 特征
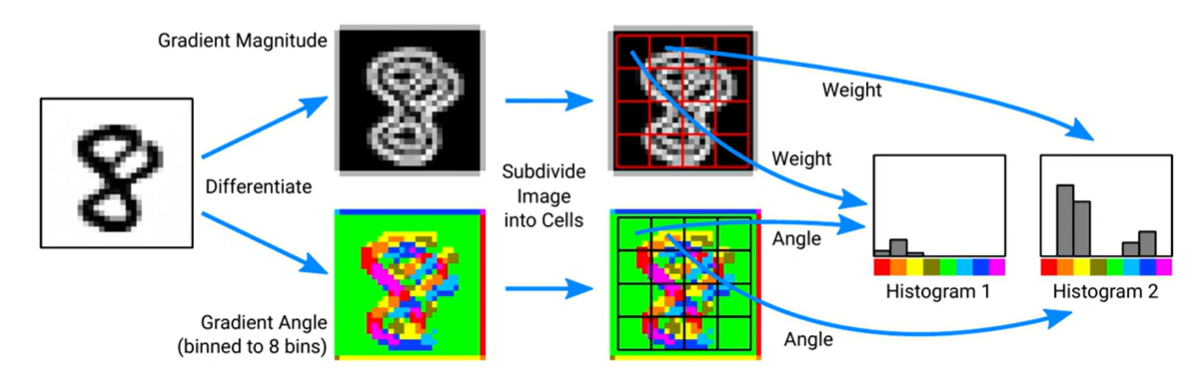
为了构建一个更鲁棒的人体检测器,我们将使用方向梯度直方图(Histogram of Oriented Gradients,HoG)特征。HoG 特征在处理视角、光照变化以及小的形变(如平移、缩放、旋转、透视变换)时具有较强的鲁棒性。
基本思想:
HoG 的核心思想是通过梯度方向和梯度幅值来表示图像块。具体,我们将图像块的每个像素点的梯度角度(由梯度方向决定)和梯度幅值(由梯度大小决定)用直方图表示,从而得到该图像块的特征描述。
提取步骤:
-
梯度计算
-
梯度幅值 (Gradient Magnitude):首先,对输入图像进行梯度计算,得到每个像素点的梯度幅值(强度)和梯度方向。梯度幅值描述了像素值变化的程度,梯度方向描述了变化的方向。
-
梯度方向 (Gradient Angle):计算每个像素点的梯度方向,并将这些方向量化为若干个方向区间。例如,这里将方向区间划分为8个方向(每个方向45度),这样可以简化计算和后续处理。
-
-
图像划分
将图像划分为多个较小的单元(cells),每个单元包含8x8个像素。
-
构建方向直方图
方向量化和加权:将梯度方向映射到相应的方向区间,并将梯度幅值作为该区间的权重值加进去。
-
块归一化
将若干个单元组合成一个块,例如2x2的单元构成一个块。然后,对块内的梯度方向直方图进行归一化处理,以增强特征的鲁棒性。
-
特征向量构建
将所有块的归一化直方图拼接在一起,形成最终的HoG特征向量。
我们可以使用 scikit-image 库来计算图像的HoG特征。
hog(img, orientations=8, pixels_per_cell=(16, 16), cells_per_block=(1, 1), channel_axis=-1, **kwargs)
- img:输入图像,类型可以是2D灰度图或3D彩色图
- orientations:方向区间的数量,即将梯度方向划分为多少个区间。默认值为8
- pixels_per_cell:每个单元(cell)包含的像素数,通常为一个2元组,例如(16, 16),表示每个单元为16x16个像素
- cells_per_block:每个块(block)包含的单元数,通常为一个2元组,例如(1, 1),表示每个块包含1x1个单元,即不进行块归一化
- channel_axis:图像通道所在的轴,对于彩色图像,通常为-1表示最后一个轴
3 训练分类器
将之前获取的正和负训练图像块进行HoG特征提取后拼接在一起,得到训练使用的特征向量X
for p in positives:
fds_pos.append(get_hog(p))
for n in negatives:
fds_neg.append(get_hog(n))
X = np.stack(fds_pos + fds_neg)
再使用正样本(标签是1)创建了一个全为1的布尔数组,长度等于正样本的数量;负样本(标签是0)创建了一个全为0的布尔数组,长度等于负样本的数量。这两个数组被连接在一起,形成了目标向量y。
y = np.concatenate([np.ones(len(positives), dtype=np.bool), np.zeros(len(negatives), dtype=np.bool)])
最近邻分类器:
使用Faiss库:
d = X.shape[1]
quantizer = faiss.IndexFlatL2(d) # measure L2 distance
index = faiss.IndexIVFFlat(quantizer, d, 100, faiss.METRIC_L2) # build the index
index.train(X.astype(np.float32))
index.add(X.astype(np.float32)) # add vectors to the index
支持向量机SVM:
使用 sklearn.svm.SVC 训练支持向量机。
svm = SVC(class_weight='balanced') # use balanced weight since we have more negatives than positives
svm.fit(X, y)
4 Evaluate
为了评估分类器,我们需要从目标图像中提取图像块及其 HOG 特征,以便我们的目标数据与训练数据进行对比。我们使用滑动窗口方法:
-
在图像上滑动窗口:
- 从图像的左上角开始,将窗口放置在该位置。提取窗口覆盖的图像区域作为一个裁剪。
- 根据步长在图像上移动窗口,提取新的裁剪。
- 重复上述步骤,直到窗口覆盖完整个图像。
for y in range(0, H - window_size[1], step_size): for x in range(0, W - window_size[0], step_size): window = (x, y, x + window_size[0], y + window_size[1]) -
特征提取与分类:
- 对每个裁剪提取HoG特征。
- 使用预先训练好的分类器对每个裁剪进行分类,判断其是否包含目标。















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









