







OPTICS算法
尽管DBSCAN算法能够给定的输入参数r(邻域的最大半径)和MinPts(核心对象的最小数量)聚类对象,但是参数任务留给了用户。参数的设置通常依靠经验,难以确定。大多数算法对参数的设置都比较敏感,设置的不同可能导致很大差别的聚类效果。
基于密度的簇关于邻域阈值是单调的。即在DBSCAN中,对于固定的MinPts值和两个邻域r1<r2,关于r1的簇C一定是关于r2的簇C’的子集。意味着,如果两个对象在同一个基于密度的簇中,则他们一定也在同一个具有较低密度的簇中。
上面这一段话可能觉得不好理解,其实意思就是说DBSCAN算法使用的参数都是全局参数,即r(邻域半径)和MinPts(最少数量)设定了之后,全局都是基于同一个密度在进行聚类。直接上图,看了图就明白DBSCAN的缺陷了。
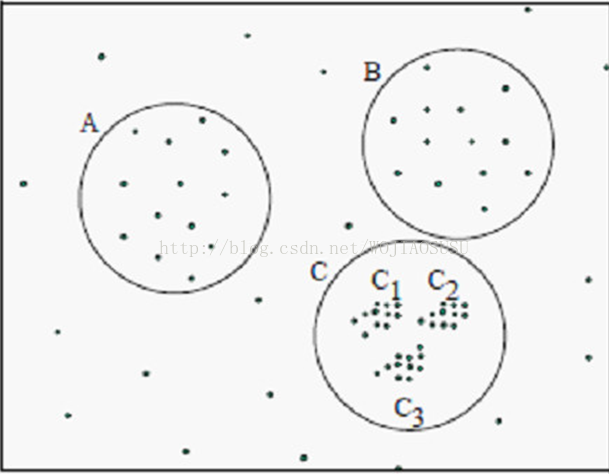
(1)不同的密度。在上图中,如果按照不同的密度,而不是在同一个基于密度的簇中,那么A,B,C三个簇都可以识别出来。
(2)最大的密度。如果按照相同的密度,如果按照最大的密度,即簇C的密度,那么只能识别出簇C,A,B可能作为噪声点而被处理了。
(3)最小的密度。如果按照最小的密度,即A,B的密度,那么所有A,B,C所有的点都在同一个簇中,聚类效果很差。
从上可以发现,DBSCAN使用全局参数聚类效果不是很好,尤其是高维数据集,数据倾斜可能比较严重。为了克服全局参数这一缺点,引入了OPTICS聚类算法。OPTICS并不显式地产生聚类簇,而是输出点排序。这个排序是所有分析对象的线性表(按照距离的远近),并且代表了数据的基于密度的聚类结构。OPTICS聚类算法不需要用户提供特定的密度阈值。簇排序可以用来提取基本的聚类信息,导出内在的聚类结构。
基本概念:
(1)核心距离:对象P的核心距离是最小的ξ’值,即使得对象P的ξ’-邻域内至少有MinPts个对象,即ξ’是使得P成为核心对象的最小半径阈值。如果P不是关于关于ξ和MinPts的核心对象,那么P的核心距离没有定义。(注意此处ξ’和ξ的联系)如下图所示我们设置的MinPts=5,那么在ξ’=4的时候就满足了,那么核心距离就是4,感觉我们全局设置的参数ξ=8没有意义?其实ξ只是起一个约束作用。
(2)可达距离:从对象q到对象p的可达距离是使p从q密度可达的最小半径值。q必须是核心对象,并且p必须在q的邻域内。从q到p的可达距离max{core_distance(q),dist(p,q)}。如果q不是核心对象,那么可达距离没有意义。
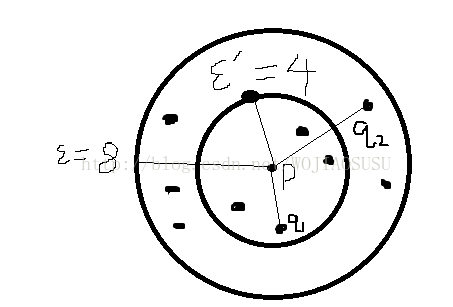
看了这两个概念,可能会觉得有点晕,其实很简单。
核心距离是某个对象满足在<=ξ的某个范围内,有MinPts个邻域点。
可达距离是核心对象(必须要有核心对象)与其邻域点的距离(邻域为ξ范围,不是ξ’范围)。
OPTICS算法思想如下所示:
-
输入:数据样本D,初始化所有点的可达距离和核心距离为MAX,半径 ε ,和最少点数 MinPts 。
-
1、建立两个队列,有序队列(核心点及该核心点的直接密度可达点),结果队列(存储样本输出及处理次序)
- 2、如果D中数据全部处理完,则算法结束,否则从D中选择一个未处理且未核心对象的点,将该核心点放入结果队列,该核心点的直接密度可达点放入有序队列,直接密度可达点并按可达距离升序排列;
- 3、如果有序序列为空,则回到步骤2,否则从有序队列中取出第一个点;
- 3.1 判断该点是否为核心点,不是则回到步骤3,是的话则将该点存入结果队列,如果该点不在结果队列;
- 3.2 该点是核心点的话,找到其所有直接密度可达点,并将这些点放入有序队列,且将有序队列中的点按照可达距离重新排序,如果该点已经在有序队列中且新的可达距离较小,则更新该点的可达距离。
- 3.3 重复步骤3,直至有序队列为空。
- 4、算法结束。
- 1、从结果队列中按顺序取出点,如果该点的可达距离不大于给定半径 ε ,则该点属于当前类别,否则至步骤2
- 2、如果该点的核心距离大于给定半径 ε ,则该点为噪声,可以忽略,否则该点属于新的聚类,跳至步骤1;
- 3、结果队列遍历结束,则算法结束
如果对这个算法之前一点了解都没有,可以仔细的看看上面的算法伪代码。其实总结一下很简单,跟DBSCAN一样也可以分为三个步骤。
(1) 对总数据D中的核心对象进行遍历
(2) 取出核心对象之后,建立两个队列,有序队列存放核心对以及核心对象的密度可达点,并且按照可达距离进行升序排序。
(3) 对有序队列进行遍历,判断每一个点是否是核心对象,如果是的话,将其密度可达点(不在结果队列中的)加入到有序队列中。将有序队列迭代输出的结果放入到结果队列中吗,同时在数据D汇总将其删掉。有序队列为空了,开始下一个核心对象的迭代,开始(1)。















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









