







[1] E. Aasi, M. Cai, C. I. Vasile, and C. Belta, “Time-Incremental Learning from Data Using Temporal Logics.” arXiv, Dec. 28, 2021. doi: 10.48550/arXiv.2112.14300.
好久没看文献了,来更一篇
Outline
-
time-variant weights of STL
-
weights are learned by NN
-
通过决策树方法学出一系列STL约束
-
通过计算信号前缀相对于STL约束的加权鲁棒度来对信号前缀进行分类
Remark
-
在每个时间点学一个wSTL来分类,有点无聊
-
前期的决策时间点太少了吧,在第一个决策点之前都是盲猜啊
Formulation
-
数据集:等长的带标签信号
-
数据不是一次性获取,在收集信号的过程中给信号分类
-
最小化每个时刻的误分类率
Details
Signal Analysis
-
找决策时间点
-
一种基于信号间距离度量的启发式方法
-
positive-negtive distance: 用于衡量正负样本在时间上的距离
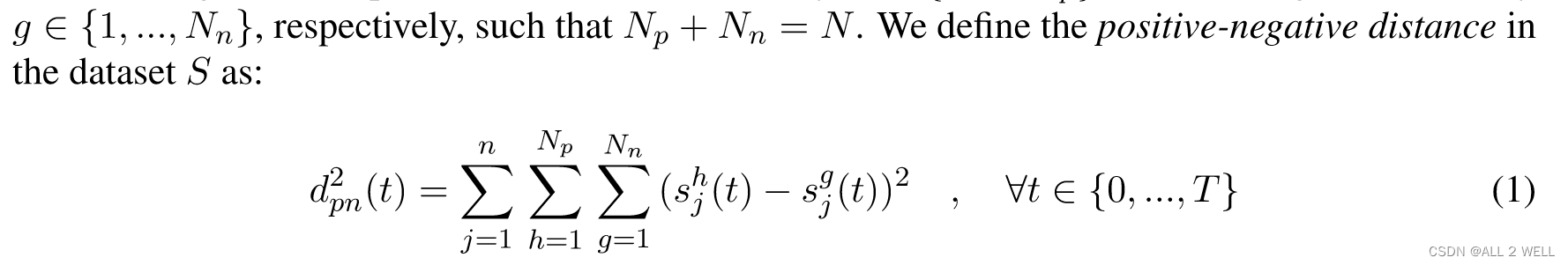
-
选取以上函数一阶导(极值点)和二阶导(趋势变化点)为0的时间点作为决策时间点
-
生成决策点集合为 T = { t k } k = 1 K \mathcal{T}=\{t_k\}^K_{k=1} T={tk}k=1K
Classifier Learning
-
在每个决策点用决策树生成分类器
-
每个决策点的分类器用STL公式 ϕ k \phi_k ϕk表示
Classifier Evaluation
-
计算每个STL的权值生成wSTL
-
ω ( t ) \omega(t) ω(t)是一个Kx1的列向量,每个元素是不同决策时间点的STL分类器的权值
-
用神经网络找到每个时刻的权值分配,可见权值是一个时变的参数
-
在t时刻,将所有的公式分为hrz<=t和hrz>t的两类
-
hrz>t的公式权值为0
-
将不同公式的鲁棒度作为输入,label作为输出训练NN,学习hrz<=t部分公式的权值
-
在决策点之间,权值将保持不变
Case Study
对比实验
-
all-times 每个时刻都是决策时间点
-
uniform-weights 所有公式的权值相等
-
our method
比较指标
-
runtime
-
STL分类器的数量
-
TMCR















 1828
1828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









