







 本文深入探讨了类增量学习,一种允许深度神经网络在不遗忘旧知识的同时学习新任务的方法。主要挑战包括灾难性遗忘、任务间混淆和任务近期偏差。文章对正则化、排练和偏差校正等方法进行了分类和评估,通过实验比较了12种方法,旨在优化类增量学习的性能和防止遗忘。
本文深入探讨了类增量学习,一种允许深度神经网络在不遗忘旧知识的同时学习新任务的方法。主要挑战包括灾难性遗忘、任务间混淆和任务近期偏差。文章对正则化、排练和偏差校正等方法进行了分类和评估,通过实验比较了12种方法,旨在优化类增量学习的性能和防止遗忘。
Class-incremental learning:survey and performance evaluation

论文地址:
https://arxiv.org/abs/2010.15277
摘要:
增量学习允许:
- 在获取到新数据到无需从头重新训练;
- 通过防止或限制所需存储的数据量来减少内存使用——在施加隐私限制时也很重要;
- 学习更接近人类学习的知识;
增量学习的主要挑战是灾难性遗忘,这是指在学习了一个新的任务后,先前学习过的任务的表现急剧下降。近年来,对深度神经网络的增量学习出现了爆炸式的增长。最初的工作集中在任务增量学习(task incremental learning)上,其中在推理时提供一个任务 id。
最近类增量学习(class-incremental learning)火了,学习器必须在推理时,对在之前的任务中看到的所有类之间进行分类,而不求助于任务 id。
在本文中,作者对现有的(2020年)增量学习方法进行了完整的调查,特别是对 12 种类增量方法进行了广泛的实验评估。
作者考虑了几个新的实验场景,包括在多个大规模数据集上的类增量方法的比较,研究小领域和大领域的迁移,以及对各种网络架构的比较。
介绍:
增量学习,也通常被称为持续或终身学习,旨在开发人工智能系统,可以从新数据中不断学习处理新任务,同时保留从以前学习过的任务中学习到的知识。
在大多数增量学习(IL)场景中,任务在一系列描述的训练过程中呈现给学习者,在此期间,只有来自单一任务的数据可用于学习。
在每次训练结束后,学习者应该能够对看不见的数据执行所有以前看到过的任务。
这种学习模式反映了人类如何获得和整合新知识:当面对新的学习任务时,我们利用以前的知识,并将新学到的知识整合到以前的任务中。
这与普遍的监督学习范式形成了鲜明对比,监督学习中,所有任务的标记数据在一个深度网络的单一训练过程中共同可用。
增量学习中,学习者每次只能访问单个任务的数据,但是是在全部学习过的任务上评估。
增量学习的主要挑战是在某种程度上从当前任务中学习数据来避免忘记以前学过的任务。
在以前学习过的任务上表现的急剧下降是一种被称为灾难性遗忘。增量学习旨在防止灾难性遗忘,同时避免抑制适应新任务的不妥协(intransigence)问题。
除了学习的生物学动机外,增量学习还有许多实际优势。例如,增量学习比经典的监督学习能更好地优化计算资源。
在经典的监督学习方法中,当将新任务纳入人工智能系统的范围时,最好的(通常只有)选择是联合重新训练所有任务,包括以前的和新的任务。
然而,在许多场景下,由于隐私考虑,以前的任务的数据可能不可用。
在增量学习中,训练被分为一系列任务,在任何训练过程中,学习者都只能访问当前任务的数据(或者,有些方法可以考虑来自以前任务的少量存储数据)。大多数早期的增量学习方法都考虑了这个场景,即任务-增量学习(task-IL),其中算法在推理时可以访问一个任务 id。
这一点有一个明显的优势,即方法不必区分来自不同任务的类。
而最近,一些方法已经开始解决更困难的类增量学习(class-IL)的场景,即学习者在推理时无法访问任务,因此必须要求学习以区分所有类和所有任务。
在本次调查中,作者着手确定类增量学习的主要挑战,并将提出的解决方案分为三类:
- 基于正则化的解决方案,旨在最小化学习新任务对之前任务的重要权重的影响;
- 基于范例的解决方案,即存储有限的范例集,以防止忘记以前的任务;
- 以及直接解决任务近因偏差问题的解决方案,指的是对最近学习的任务的偏差;
除了概述近年来 class-IL 的进展外,作者还对现有方法进行了广泛的实验评价。
作者评估了几种更流行的正则化方法(通常是为 task-IL 提出的),并将它们用范例进行扩展,以便与最近开发的方法进行更公平的比较。
此外,作者还在几种场景下进行了广泛的实验,比较了12种方法,并在一个新的、更具挑战性的多数据集设置上评估了 class-IL 方法。
最后,我们首先在广泛的网络架构上比较这些方法,并为可扩展的 class-IL 评估框架提供代码,以确保所有结果的可复现性。
相关工作:
Task-incremental learning:
正如在中所讨论的,大多数 task-IL 方法可以分为具有相似特征的大类。大多数基于正则化和基于重放的方法可以同时应用于 task-IL 和 class-IL 。而参数隔离(Parameter isolation)方法通常应用于 task-IL 问题,因为它们的计算代价高昂或性能不佳。
基于掩码的方法通过对每个参数或每一层的表示应用掩码来减少或完全消除灾难性遗忘。然而,通过学习网络结构中每个任务的有用路径,并不可能同时对所有学习到的任务进行评估。这迫使几次使用不同的掩码前进,这使得这些方法对于任务感知评估非常有效,但对于任务无关的设置不切实际。
架构增长(architecture growing)的方法动态地增加了网络的能力,以减少灾难性的遗忘。他们依赖于促进一个更不妥协的模型,能够维护以前的任务知识,同时扩展该模型,以学习新的任务。这使得当任务 id 不知道,或在网络中添加太多的参数时,这些方法不可行,这使得这些方法在大量任务中不可行。
Online learning:
在线方法是基于流媒体框架的,其中学习者只允许观察每个样本一次,而不是在训练中迭代一组样本。样本是非独立同分布型的,通常具有时间相关性。
Lopez-Paz 为此设置建立了定义和评估方法,并描述了 GEM,它使用每个任务的样本记忆(exemplar memory)来约束梯度,从而不会增加先前任务的近似损失。
A-GEM 则通过约束基于前一类样本的梯度平均值来提高 GEM 的效率。
然而,有的研究表明,简单的在记忆样本上的训练,类似于强化学习中已经建立的技术,优于以前的结果。
GSS基于 GEM 和 A-GEM 程序执行基于梯度的样本选择,以允许在不知道任务边界的情况下进行训练。
MIR通过选择在每个训练步骤后损失增加更大的样本来基于样本记忆进行训练。
在 M. Riemer 等人的研究中,内存用于存储来自变分自动编码器的离散潜在嵌入,它允许生成以前的任务数据进行训练。
MER将经验重放与元学习方法的修改相结合,以选择减少遗忘的重放样本。
Variational continual learning:
变分持续学习是基于贝叶斯推理框架的。
VCL提出合并在线和蒙特卡罗变分推理的神经网络产生变分连续学习。它是通用的,适用于判别和生成的深度模型。
VGL引入了变分生成回放,这是一种对深度生成回放(DGR)的变分推理推广,它是对VCL的补充。
UCL提出了基于标准贝叶斯在线学习框架的不确定性正则化持续学习。它对高斯平均场近似情况下的变分下界的 KL 散度项作了一个新的解释。
FBCL 提出使用自然梯度和Stein梯度来更好地估计参数的后验分布,并使用近似后验构造共置。
IUVCL提出了一种新的平均场变分贝叶斯神经网络的最佳实践方法。
上述这些方法通常只考虑具有任务感知功能的设置。
而 BGD 以封闭的形式更新后部,这不需要任务 id。
Pseudo-rehearsal methods:
为了避免存储样本,并且规避样本排列中固有的隐私问题,一些方法学习从以前的任务中生成示例。
DGR使用一个无条件的GAN来生成这些合成样本,即使用一个辅助分类器来为每个生成的样本分配真值标签。
MeRGAN提出了一个改进的版本,它使用了一个标签条件的GAN和重放对齐。
DGM则结合了条件GANs和突触可塑性(synaptic plasticity)的优势,即引入一种动态网络扩展机制,以保证有足够的模型容量。
Lifelong-GAN 在没有灾难性遗忘的情况下扩展了图像生成,从标签条件GAN扩展到图像条件GAN。
类增量学习:
在本节中,我们将定义类增量学习设置的细节,并讨论类增量学习方法必须解决的主要挑战。
通用类增量式学习设置:
我们的研究重点是类增量学习场景,其中算法必须学习一系列任务。对于任务,我们指的是一组与其他(以前的或将来的)任务中的类分离的类。
在每次训练中,学习者只能从单个任务中获得数据。我们有选择地考虑一个小内存,可以用来存储来自以前任务的一些样本。
任务由多个类组成,允许学习者在训练过程中多次处理当前任务的训练数据。我们不考虑在一些论文中使用的在线学习设置,其中每个数据样本只看到一次。
更正式地说,一个增量学习问题 T T T 由 n n n 个任务序列组成:
T = [ ( C 1 , D 1 ) , ( C 2 , D 2 ) , … , ( C n , D n ) ] \mathcal{T}=\left[\left(C^{1}, D^{1}\right),\left(C^{2}, D^{2}\right), \ldots,\left(C^{n}, D^{n}\right)\right] T=[(C1,D1),(C2,D2),…,(Cn,Dn)]
其中,每个任务 t t t 由一个类别集合 C t = { c 1 t , c 2 t … , c n t t } C^{t}=\left\{c_{1}^{t}, c_{2}^{t} \ldots, c_{n^{t}}^{t}\right\} Ct={c1t,c2t…,cntt} 和训练数据 D t D^{t} Dt 构成,并且我们用 N t N^{t} Nt 来表示包含任务 t t t 及其之前的任务的类别总数,即:
N t = ∑ i = 1 t ∣ C i ∣ N^{t}=\sum_{i=1}^{t}\left|C^{i}\right| Nt=i=1∑t∣∣Ci∣∣
我们考虑类增量分类问题,即:
D t = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m t , y m t ) } D^{t}=\left\{\left(\mathbf{x}_{1}, \mathbf{y}_{1}\right),\left(\mathbf{x}_{2}, \mathbf{y}_{2}\right), \ldots,\left(\mathbf{x}_{m^{t}}, \mathbf{y}_{m^{t}}\right)\right\} Dt={(x1,y1),(x2,y2),…,(xmt,ymt)}
其中, x \mathbf{x} x 为一个训练样本的输入特征, y ∈ { 0 , 1 } N t \mathbf{y} \in\{0,1\}^{N^{t}} y∈{0,1}Nt 为对应于 x i \mathbf{x}_{i} xi 的one-hot标签向量。
在任务 t t t 的训练过程中,学习者只能访问 D t D^{t} Dt 并且这些任务在类别上没有重叠,即:
C i ∩ C j = ∅ if i ≠ j C^{i} \cap C^{j}=\varnothing \text { if } i \neq j Ci∩Cj=∅ if i=j
我们的增量学习的学习者通常是深度神经网络,参数为 θ \theta θ,我们使用 o ( x ) = h ( x ; θ ) \mathbf{o}(\mathbf{x})=h(\mathbf{x};\theta) o(x)=h(x;θ) 来表示输出的 logits。
然后我们可以进一步将神经网络分成特征提取器 f f f(参数为 ϕ \phi ϕ)和线性分类器 g g g(参数为 V V V),即:
o ( x = g ( f ( x ; ϕ ) ; V ) ) \mathbf{o}(\mathbf{x}=g(f(\mathbf{x};\phi);V)) o(x=g(f(x;ϕ);V))
我们用 y ^ = σ ( h ( x ; θ ) ) \hat{\mathbf{y}}=\sigma(h(\mathbf{x};\theta)) y^=σ(h(x;θ)) 来表示网络的预测,其中 σ \sigma σ 表示 softmax 函数。
在对任务 t t t 进行训练后,我们评估了网络在所有类 ⋃ i = 1 t C i \bigcup_{i=1}^{t} C^{i} ⋃i=1tCi 上的性能。
大多数 class-IL 分类器都训练了交叉熵损失,当只训练来自当前任务 t t t 的数据时,我们可以考虑两个交叉熵变量。
我们可以考虑到目前任务为止的所有类的交叉熵:
L c ( x , y ; θ t ) = ∑ k = 1 N t y k log exp ( o k ) ∑ i = 1 N t exp ( o i ) \mathcal{L}_{c}\left(\mathbf{x}, \mathbf{y} ; \theta^{t}\right)=\sum_{k=1}^{N^{t}} y_{k} \log \frac{\exp \left(\mathbf{o}_{k}\right)}{\sum_{i=1}^{N^{t}} \exp \left(\mathbf{o}_{i}\right)} Lc(x,y;θt)=k=1∑Ntyklog∑i=1Ntexp(oi)exp(ok)
在这种情况下,由于 softmax 规范化是在之前所有任务中看到的所有类上执行的,因此训练期间的错误将从所有输出反向传播——包括那些不对应于属于当前任务的类的错误。
相反,我们只能考虑属于当前任务 t t t 的类的网络输出,并定义以下交叉熵损失:
L c ∗ ( x , y ; θ t ) = ∑ k = 1 ∣ C t ∣ y N t − 1 + k log exp ( o N t − 1 + k ) ∑ i = 1 ∣ C t ∣ exp ( o N t − 1 + i ) \mathcal{L}_{c^{*}}\left(\mathbf{x}, \mathbf{y} ; \theta^{t}\right)=\sum_{k=1}^{\left|C^{t}\right|} y_{N^{t-1}+k} \log \frac{\exp \left(\mathbf{o}_{N^{t-1}+k}\right)}{\sum_{i=1}^{\left|C^{t}\right|} \exp \left(\mathbf{o}_{N^{t-1}+i}\right)} Lc∗(x,y;θt)=k=1∑∣Ct∣yNt−1+klog∑i=1∣Ct∣exp(oNt−1+i)exp(oNt−1+k)
这种损失只考虑来自当前任务的类的 softmax 标准化预测。因此,错误只从任务 t t t 中与这些类相关的概率中反向传播。
类增量学习的挑战:
有效的类增量学习的基本障碍在概念上很简单,但在实践中非常难以克服。
这些挑战源于对任务的顺序训练,以及要求学习者在任何时候都必须能够从所有以前学过的任务中对所有的类进行分类。
增量学习方法必须在为当前任务学习新知识的同时,平衡从当前任务中保留知识。这个问题被称为稳定性-可塑性困境(stability-plasticity dilemma)。
一种只专注于学习新任务的朴素方法将会遭受灾难性的遗忘,即在之前的任务上的表现急剧下降。
防止灾难性遗忘会导致类增量学习的第二个重要问题,即难以学习新任务。
类增量学习者的灾难性遗忘有几个原因:
- 权重漂移(weight drift): 在学习新任务时,与旧任务相关的网络权重会被更新,以尽量减少新任务的损失,因此对以前的任务的性能会受到影响;
- 激活漂移(activation drift): 与权重漂移密切相关的是,权重的变化会导致激活的变化,从而导致网络输出的变化。关注激活而不是权重的限制可能较少,因为这允许权重改变,只要它们不太影响激活的变化;
- 任务间混淆(inter-task confusion): 在类增量学习中,目标是区分所有类和所有任务。然而,由于类从未经过联合训练,网络权值不能最优地区分所有类(如图1),这适用于网络中的所有层;
- 任务一致性偏差(task-recency bias): 单独学习到的任务可能具有较好的分类器输出。通常,最主要的任务偏向是对更近期的任务类别。这种效应在混淆矩阵中可以清楚地观察到,这说明了将输入误分类为属于最近看到的任务的倾向(如图2);
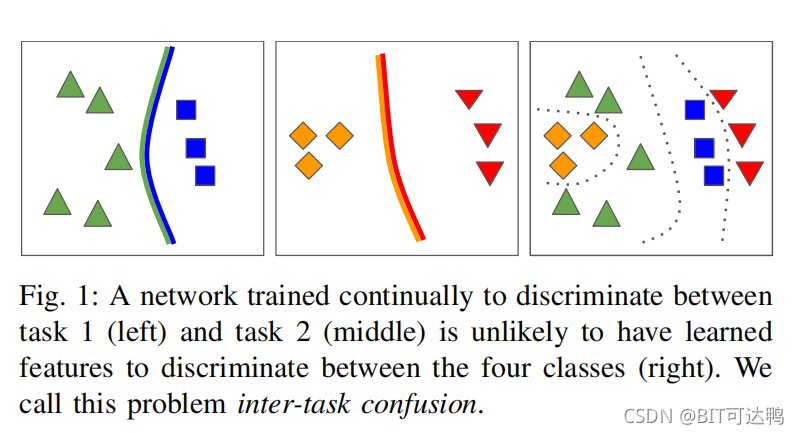
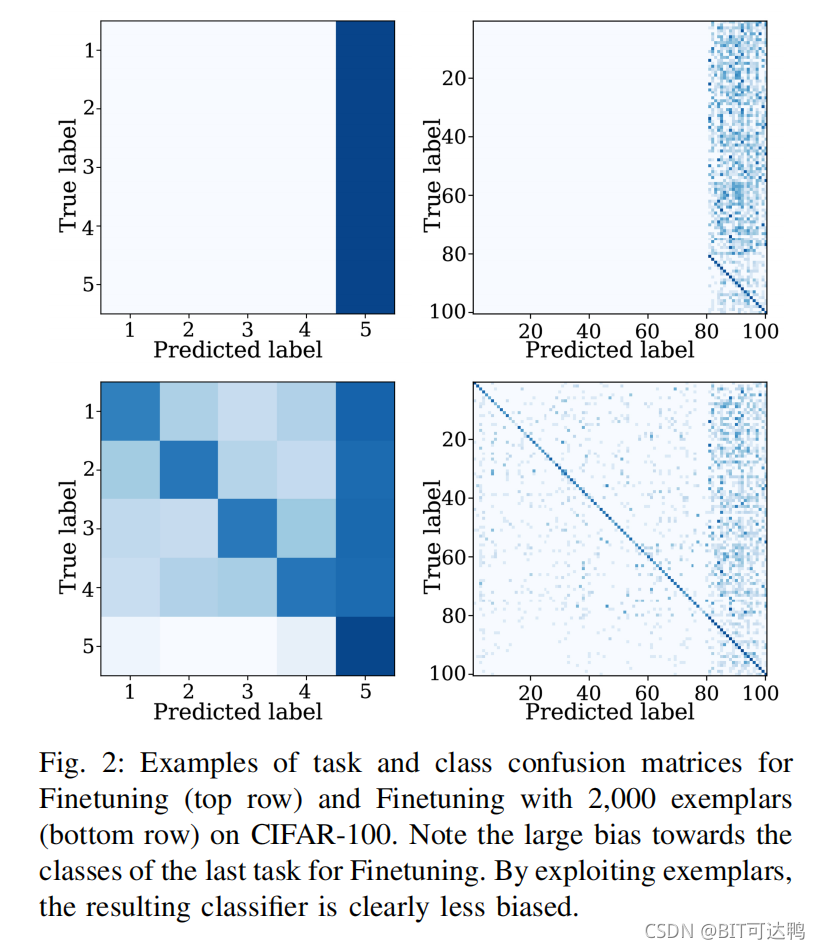
遗忘的前两个来源与网络漂移有关,并在任务增量学习文献中得到了广泛的考虑。
而基于正则化的方法要么专注于防止重要权重的漂移,要么专注于防止激活值的漂移。
最后两点是特定于类增量学习的,因为他们在推理时无法访问任务 id。
类增量学习的研究大多集中在减少任务不平衡,从而解决了任务近期偏差。为了防止任务间混淆和学习区分所有类的最佳表示,常用排练(rehearsal)或伪排练(pseudo-rehearsal)。
研究方法:
在本节中,我们将描述解决上述类增量学习挑战的几种方法。我们将它们主要分为三大类:基于规则化的方法、基于排练的方法和基于偏差校正的方法。首先,我们通过阐明和激励类增量学习方法在实验评估中应该考虑的属性来讨论本调查的范围。
实验评估范围:
关于 IL 的文献数量广泛且不断增长,近年来已经提出了一些关于类增量学习的定义和解释。为了将本调查的范围缩小到一组有用的可比方法,我们考虑了类增量学习方法的一些设置,包括:
- 增量(Incremental): 可以从从非平稳分布中提取的数据流中进行训练的方法;
- 任务可转移(Task transferable): 类增量学习者能够利用以前类的知识来改进新类的学习(正向迁移),并利用新数据来提高以前任务的性能(向后迁移);
- 任务无关(Task-agnostic): 增量学习者能够以任务无关的方式预测所有以前学习过的任务的类(即,不求助于提供可能的类);
- 离线(Offline): 数据在数据为独立同分布的训练环节中呈现,可以在进行下一个任务之前进行多次处理的方法;
- 固定网络结构(Fixed network architecture): 对所有任务使用固定结构的方法,无需为新任务添加大量参数;
- 白板(Tabula rasa): 从头开始训练的增量学习者,不需要对大型标记数据集进行预训练。这一特性消除了在训练前过程中看到的类分布所引入的潜在偏差,以及从这些知识中衍生出的任何利用;
- 成熟(Mature): 适用于复杂图像分类问题的方法;
- 无示例(Exemplar-free): 不需要存储来自以前任务中的图像数据的方法,这是应保护隐私的方法的一个重要特征(可选);
属性1和属性2是 IL 方法的内在特征,属性3区分了类增量学习和任务增量学习,而属性4-7是我们用来选择评估方法的特征。
我们的评估(属性8)考虑了需要图像样本的方法以及那些不需要的方法,因此可以应用于有更严格的隐私考虑的系统。
在数据隐私和安全对许多用户来说是基础,并受到越来越多的立法控制下,不需要任何数据存储的方法受到越来越多的关注。
Regularization approaches:
有几种方法使用正则化项和分类损失来减少灾难性遗忘。一些人关注网络中每个参数的权重和估计一个重要度量,而另一些人则关注记忆特征表示的重要性。
这些方法中的大多数是在 task-IL 的背景下开发的,但是由于它们对 class-IL 也很重要,我们将简要地讨论它们,特别是特征表示的正则化在 class-IL 中被广泛应用。
最后,我们将描述最近专门为 class-IL 开发的几种正则化技术。
Weight regularization:
第一类方法侧重于预防与先前任务相关的重量漂移。在学习了每一项任务后,他们通过估计网络中每个参数(假设它们是独立的)的优先重要性来实现这一点。当训练新任务时,每个参数的重要性被用来惩罚对它们的改变。
即除了交叉熵分类损失外,还引入了一个额外的损失:
L r e g ( θ t ) = 1 2 ∑ i = 1 ∣ θ t − 1 ∣ Ω i ( θ i t − 1 − θ i t ) 2 \mathcal{L}_{\mathrm{reg}}\left(\theta^{t}\right)=\frac{1}{2} \sum_{i=1}^{\left|\theta^{t-1}\right|} \Omega_{i}\left(\theta_{i}^{t-1}-\theta_{i}^{t}\right)^{2} Lreg(θt)=21i=1∑∣θt−1∣Ωi(θit−1−θit)2
其中 θ i t \theta_{i}^{t} θit 是当前训练的网络的权重 i i i, θ i t − 1 \theta_{i}^{t-1} θit−1 是在任务 t − 1 t-1 t−1 训练后的网络的权重 i i i, ∣ θ t − 1 ∣ \left|\theta^{t-1}\right| ∣∣θt−1∣∣ 是权重的数量, Ω i \Omega_{i} Ωi 保存每个网络权重的重要性值。
Kirkpatrick 等人提出了弹性权值巩固(Elastic Weight Consolidation,简称 EWC),其中 Ω i \Omega_{i} Ωi 被计算为经验费雪信息矩阵(Fisher Information Matrix)的对角线近似。然而,这捕捉到了每个任务学习后最小的模型重要性,而忽略了这些参数在权重空间中沿学习轨迹的影响。
X. Liu 等人通过将参数空间旋转到一个能够更好地逼近费雪信息矩阵的参数空间来改进 EWC。然而,该模型在训练过程中需要使用固定的参数进行扩展,这并不会增加网络的容量,但会导致计算和内存成本。
相比之下,路径积分方法(PathInt)沿着整个学习轨迹在线积累每个参数的变化。正如作者所指出的,批量更新权重可能会导致高估重要性,而从预先训练过的模型开始可能会导致低估重要性。
为了解决这个问题,记忆感知突触(MAS)还提出通过积累学习函数的灵敏度(梯度的大小)来在线计算 Ω i \Omega_{i} Ωi。
黎曼行走(RWalk)算法则通过融合费雪信息矩阵近似和在线路径积分来计算每个参数的重要性。此外,RWalk还使用范例来进一步改进结果。
Data regularization:
第二类基于规则化的方法旨在防止激活漂移,并基于知识蒸馏传递知识,它最初的设计目的是从一个更大的教师网络中学习一个更紧凑的学生网络, Li 等人提出使用该技术来防止在学习新任务时过多的漂移。他们的方法称为“不忘记学习”(LwF),基于以下损失实现:
L dis ( x ; θ t ) = ∑ k = 1 N t − 1 π k t − 1 ( x ) log π k t ( x ) \mathcal{L}_{\text {dis }}\left(\mathbf{x} ; \theta^{t}\right)=\sum_{k=1}^{N^{t-1}} \pi_{k}^{t-1}(\mathbf{x}) \log \pi_{k}^{t}(\mathbf{x}) Ldis (x;θt)=k=1∑Nt−1πkt−1(x)logπkt(x)
其中 π k t ( x ) \pi_{k}^{t}(\mathbf{x}) πkt(x) 是模型温度规范的 logits:
π k ( x ) = e o k ( x ) / T ∑ l = 1 N t − 1 e o l ( x ) / T \pi_{k}(\mathbf{x})=\frac{e^{\mathbf{o}_{k}(\mathbf{x}) / T}}{\sum_{l=1}^{N^{t-1}} e^{\mathbf{o}_{l}(\mathbf{x}) / T}} πk(x)=∑l=1Nt−1eol(x)/Teok(x)/T
其中温度项 T T T 用来帮助解决出现正确类的概率过高的问题。
该损失已经成为了许多类增量学习的关键成分。但是一些研究观察到,当任务之间的域移小时,损失尤其有效,然而,当域移大时,其效能显著降低。
Jung 等人提出了一种非常类似的方法,即较少遗忘学习(LFL)。
LFL 通过冻结最后一层并惩罚分类器层前激活之间的差异来保存先前的知识。然而,由于当域转移太大时,这可能会引入更大的问题,因此其他方法也引入了修改来处理它。
基于编码器的终身学习通过优化一个不完全的自动编码器来扩展LwF,该自动编码器将特征投影到一个维度更小的流形上。每个任务要学习一个自动编码器,这使得增长呈线性关系,尽管自动编码器与总模型大小相比很小。
Recent developments in regularization:
在最近的类增量学习研究中,提出了几种新的正则化技术。
Zagoruyko 和 Komodakis 建议利用教师网络的注意力来指导学生网络,不需要记忆学习(LwM)则将这种技术应用于类增量学习。其主要思想是,训练新任务的网络在训练新任务时所使用的注意力不应改变。这有助于决定某个类标签的特性预计将保持不变。
这是由注意力蒸馏损失所实现的:
L A D ( x ; θ t ) = ∥ Q t − 1 ( x ) ∥ Q t − 1 ( x ) ∥ 2 − Q t ( x ) ∥ Q t ( x ) ∥ 2 ∥ 1 \mathcal{L}_{A D}\left(\mathbf{x} ; \theta^{t}\right)=\left\|\frac{Q^{t-1}(\mathbf{x})}{\left\|Q^{t-1}(\mathbf{x})\right\|_{2}}-\frac{Q^{t}(\mathbf{x})}{\left\|Q^{t}(\mathbf{x})\right\|_{2}}\right\|_{1} LAD(x;θt)=∥∥∥∥∥Qt−1(x)∥2Qt−1(x)−∥Qt(x)∥2Qt(x)∥∥∥∥1
其中,注意图 Q Q Q 为:
Q t ( x ) = Grad-CAM ( x , θ t , c ) Q t − 1 ( x ) = Grad-CAM ( x , θ t − 1 , c ) \begin{aligned} Q^{t}(\mathbf{x}) &=\operatorname{Grad-CAM}\left(\mathbf{x}, \theta^{t}, c\right) \\ Q^{t-1}(\mathbf{x}) &=\operatorname{Grad-CAM}\left(\mathbf{x}, \theta^{t-1}, c\right) \end{aligned} Qt(x)Qt−1(x)=Grad-CAM(x,θt,c)=Grad-CAM(x,θt−1,c)
Q Q Q 由Grad-CAM算法生成。Grad-CAM计算关于目标类 c c c 的梯度,以生成一个粗糙的定位映射,用来指示对预测有贡献的图像区域。
这里我们无法使用目标类别标签,因为这个标签在训练 θ t − 1 \theta^{t-1} θt−1 时并不存在,因此作者提出使用预测的最高置信度的之前的类别来计算注意力图:
c = argmax h ( x ; θ t − 1 ) c=\operatorname{argmax} \mathrm{h}\left(\mathbf{x} ; \theta^{\mathrm{t}-1}\right) c=argmaxh(x;θt−1)
另一种基于LwF的最新方法是域模型整合(DMC)。这是基于旧类别与新类别之间存在不对称:新类有明确有力的监督,而对旧类的监督较弱,并且旧类通过知识蒸馏进行沟通。
为了消除这种不对称性,他们建议对在旧类训练过的 θ t − 1 \theta^{t-1} θt−1 模型以及在新类训练过的 θ t \theta^{t} θt 施加双重蒸馏损失,这允许该模型忘记之前的任务:
L D D ( u ; θ ) = 1 N t ∑ k = 1 N t ( o k ( u ) − o ∘ k ( u ) ) 2 \mathcal{L}_{D D}(\mathbf{u} ; \theta)=\frac{1}{N^{t}} \sum_{k=1}^{N^{t}}\left(\mathbf{o}_{k}(\mathbf{u})-\stackrel{\circ}{\mathbf{o}}_{k}(\mathbf{u})\right)^{2} LDD(u;θ)=Nt1k=1∑Nt(ok(u)−o∘k(u))2
其中 o ∘ k ( u ) \stackrel{\circ}{\mathbf{o}}_{k}(\mathbf{u}) o∘k(u) 标准化的 logits:
o ∘ k ( u ) = { o k t − 1 ( u ) − 1 N t − 1 ∑ l = 1 N t − 1 o l t − 1 ( u ) if 1 ⩽ k ⩽ N t − 1 o k t ( u ) − 1 N t ∑ l = 1 N t o l t ( u ) if N t − 1 < k ⩽ N t \stackrel{\circ}{\mathbf{o}}_{k}(\mathbf{u})=\left\{\begin{array}{ll} \mathbf{o}_{k}^{t-1}(\mathbf{u})-\frac{1}{N^{t-1}} \sum_{l=1}^{N^{t-1}} \mathbf{o}_{l}^{t-1}(\mathbf{u}) & \text { if } 1 \leqslant k \leqslant N^{t-1} \\ \mathbf{o}_{k}^{t}(\mathbf{u})-\frac{1}{N^{t}} \sum_{l=1}^{N^{t}} \mathbf{o}_{l}^{t}(\mathbf{u}) & \text { if } N^{t-1}<k \leqslant N^{t} \end{array}\right. o∘k(u)={okt−1(u)−Nt−11∑l=1Nt−1olt−1(u)okt(u)−Nt1∑l=1Ntolt(u) if 1⩽k⩽Nt−1 if Nt−1<k⩽Nt
其中 o l t − 1 ( u ) \mathbf{o}_{l}^{t-1}(\mathbf{u}) olt−1(u) 表示在之前的任务训练的模型输出的 logits, o l t ( u ) \mathbf{o}_{l}^{t}(\mathbf{u}) olt(u) 则表示在新类上训练的模型输出的 logits。
由于该算法无法访问以前任务的数据,因此他们建议使用辅助数据 u \mathbf{u} u,这些数据 u \mathbf{u} u 可以是来自类似域的任何未标记数据。
最后,Hou 等人提出的较少被遗忘的约束(less-forget constraint)。他们的方法是LwF的一个变体,并且他们不建议正则化网络预测,而是建议对先前网络和当前网络的 ℓ 2 \ell_{2} ℓ2 归一化 logits 之间的余弦相似性进行正则化:
L l f ( x ; θ ) = 1 − ⟨ o t − 1 ( x ) , o t ( x ) ⟩ ∥ o t − 1 ( x ) ∥ 2 ∥ o t ( x ) ∥ 2 \mathcal{L}_{l f}(\mathbf{x} ; \theta)=1-\frac{\left\langle\mathbf{o}^{t-1}(\mathbf{x}), \mathbf{o}^{t}(\mathbf{x})\right\rangle}{\left\|\mathbf{o}^{t-1}(\mathbf{x})\right\|_{2}\left\|\mathbf{o}^{t}(\mathbf{x})\right\|_{2}} Llf(x;θ)=1−∥ot−1(x)∥2∥ot(x)∥2⟨ot−1(x),ot(x)⟩
其中 ⟨ ⋅ , ⋅ ⟩ \langle\cdot, \cdot\rangle ⟨⋅,⋅⟩ 是向量之间的内积。
这种正则化对任务不平衡不那么敏感,因为该比较是在归一化向量之间进行的。作者表明,这种损失减少了对新类别的偏见。
Rehearsal approaches:
排练方法保留少量的范例或生成合成图像(或特征)。
通过重放来自以前任务的存储或生成的数据,排练方法的目的是防止忘记以前的任务。
大多数预演方法将范例的使用来处理任务间混淆与处理灾难性遗忘的方法相结合。类分类器的样本排练的使用首先是在增量分类器和表示学习(iCaRL)中提出的。这种技术已经应用于大多数类增量学习方法中。
在本节中,我们将重点关注在应用范例时需要采取的选择。
Memory types:
在模型已经适应了新的任务后,样本记忆必须在训练课程结束时进行扩展。
如果内存在所有任务(固定内存)中都具有固定的最大大小,则必须首先删除一些范例,以为新的范例腾出空间。这将确保内存容量保持不变,并且容量也保持不变。
学习到的任务和类越多,每个类用来排练的表现就越少。在学习了一定数量的任务后,可以扩展内存以更好地适应新的分布。
然而,以前移除的样本将会丢失,因此决定何时扩展是一个很重要的问题。如果允许内存增长(增长内存),则只需要添加来自当前任务的新样本。
这迫使类在跨所有任务的排练期间具有稳定的表示,但代价是内存的线性增加,这可能不适用于某些应用程序。在这两种情况下,每个类的范例数量都被强制执行为相同的,以确保所有类的表示都相等。
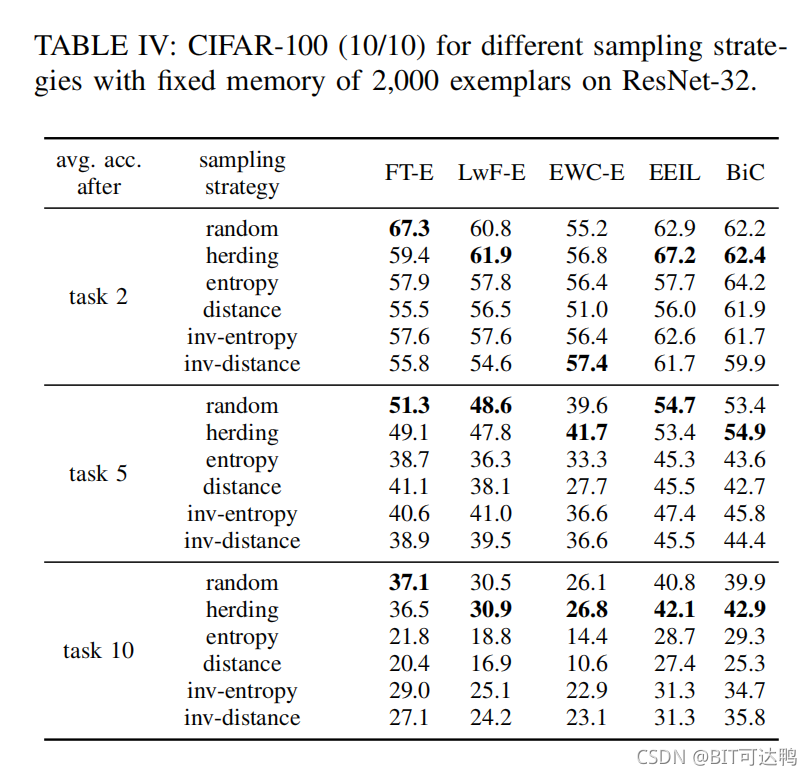
Sampling strategies:
选择样本添加到内存中的最简单的方法是从可用的数据中随机抽样,这已经被证明是非常有效的,而且没有太大的计算成本。
iCaRL提出基于相应的特征空间表示来选择样本。即提取所有样本的表示,并计算每个类的平均值。
该方法会迭代地为每个类选择范例。在每一步中,选择一个样本,以便当添加到其类的样本中时,得到的样本均值最接近真实的类均值。
添加范例的顺序很重要,并在需要删除一些样本时加以考虑。虽然这种迭代选择过程通常优于随机选择过程,但它增加了计算成本。
RWalk提出了另外两种抽样策略:
- 第一个方法计算softmax输出的熵,并选择具有较高熵的样本。这将强制选择在所有类中具有更多分布分数的样本;
- 类似地,第二个样本根据样本与决策边界的距离来选择样本,假设特征空间和决策边界变化不太大。对于一个给定的样本 ( x i , y i ) (\mathbf{x}_{i}, \mathbf{y}_{i}) (xi,yi),计算到决策边界的伪距离是由 f ( x i ; ϕ ) T V y i f\left(\mathbf{x}_{i} ; \phi\right)^{T} V_{\mathbf{y}_{i}} f(xi;ϕ)TVyi 给出的;
对于这些抽样策略(随机策略除外),选择样本的顺序按重要性递减的顺序记录。
如果使用了固定的内存,并且必须释放一些内存来为新的范例腾出空间,那么重要性较低的范例是最先删除的范例。
Task balancing:
在训练新任务时进行排练时,新类与前类的权重是由损失两部分之间的权衡以及每个训练步骤中每个类的样本数量来定义的。
大多数方法从新数据和排练范例之间的联合存储池中对训练批进行采样,这意味着批次显然被新样本过多表示,并依赖于交叉熵损失和其他防止遗忘的损失之间的权衡。
相比之下,“End-to-end incremental learning” 中建议进行一个更平衡的训练,即批次平均分布在新的类和以前的类之间。这似乎对补偿训练过程中的任务不平衡有相当有益的效果。
Combining rehearsal and data regularization:
有几种方法结合范例使用“不忘学习”(Learning without Forgetting)的蒸馏损失来处理激活漂移。然而,Beloudah和Popescu做了重要的观察,即当使用范例时,这个蒸馏术语实际上会损害性能。
我们将在我们的结果中证实这一点,然而,我们将表明,在某些情况下,权重正规化和范例排练的组合可能是有益的。
Bias-correction approaches:
偏差校正方法旨在解决任务最近偏差的问题,任务最近偏差是指增量学习的网络在最近学习的任务中偏向于类的趋势。
这主要是由于在训练结束时,网络在最后一个任务中看到了较多对应类的样本,但没有来自早期任务(或排练时很少)的样本。
正如 Hou 等人所观察到的一个直接结果,新类的分类器范数比以前的类要大,并且分类器偏向于最近的类。
这种效应如图3所示,其中分类器的偏差较低和减少的范数使得网络不太可能选择之前的任何类。
在本节中,我们将讨论解决这个问题的几种方法。
前面提到的iCaRL方法结合了样本记忆和不忘记的学习,使用了训练期间的分类器层和交叉熵损失。为了防止任务性偏差,他们在推理时不使用分类器。相反,他们计算特征表示中的样本的类均值,然后应用最接近的样本均值进行分类。由于这个过程独立于最后一层的权重和偏差,该方法被证明不太容易出现任务-近期偏差。
Castro等人提出了一种简单而有效的防止任务-近期偏差的方法,在他们的方法中使用的端到端增量学习(EEIL)。他们建议在每次训练结束时引入一个额外的阶段,称为平衡训练。在这个阶段,从所有类中使用相同数量的范例,用于有限数量的迭代。为了避免忘记新的类,它们只针对当前任务中的类在分类层上引入了蒸馏损失。当平衡训练不能完全代表分布时,其代价可能是过拟合。
Wu等人提出了另一种简单而有效的预防任务性偏差的方法,他们称他们的方法称为偏差修正(BiC)。它们增加了另一层,专门用于纠正网络中的任务偏差。
训练分为两个阶段。
在第一阶段,他们用交叉熵损失和蒸馏损失来训练新的任务。 然后,他们使用很小部分训练数据的分割来作为第二阶段的验证集。他们建议在 logits 之上学习一个线性变换, o k \mathbf{o}_{k} ok,以补偿任务最近的偏差。转换后的 logits 如下:
q k = α s o k + β s , c k ∈ C s \mathbf{q}_{k}=\alpha_{s} \mathbf{o}_{k}+\beta_{s}, \quad c_{k} \in C^{s} qk=αsok+βs,ck∈Cs
其中 α s \alpha_{s} αs 和 β s \beta_{s} βs 是补偿任务 s s s 中偏差的参数。对于每个任务只有两个参数在那个任务中对所有类共享(初始化为 α 1 = 1 \alpha_{1}=1 α1=1 和 β 1 = 0 \beta_{1}=0 β1=0)。
在第二阶段,除当前任务 α t \alpha_{t} αt 和 β t \beta_{t} βt 的参数外,网络中的所有参数都被冻结。使用备用验证集,在转换后的对数 q k \mathbf{q}_{k} qk 上使用标准的softmax进行优化。最后,它们只对 β \beta β 参数应用权重衰减,而不是对 α \alpha α 参数应用。
如前所述,Hou 等人也观察到了任务-近期偏差。在他们的方法中,通过重平衡(LUCIR)增量地学习一个统一的分类器,他们建议用余弦归一化层替换标准的 softmax 层 σ \sigma σ,即:
L cos ( x ; θ t ) = ∑ k = 1 N t y k log exp ( η ⟨ f ( x ) ∥ f ( x ) ∥ , V k ∥ V k ∥ ⟩ ) ∑ i = 1 N t exp ( η ⟨ f ( x ) ∥ f ( x ) ∥ , V i ∥ V i ∥ ⟩ ) \mathcal{L}_{\cos }\left(\mathbf{x} ; \theta^{t}\right)=\sum_{k=1}^{N^{t}} y_{k} \log \frac{\exp \left(\eta\left\langle\frac{f(\mathbf{x})}{\|f(\mathbf{x})\|}, \frac{V_{k}}{\left\|V_{k}\right\|}\right\rangle\right)}{\sum_{i=1}^{N^{t}} \exp \left(\eta\left\langle\frac{f(\mathbf{x})}{\|f(\mathbf{x})\|}, \frac{V_{i}}{\left\|V_{i}\right\|}\right\rangle\right)} Lcos(x;θt)=k=1∑Ntyklog∑i=1Ntexp(η⟨∥f(x)∥f(x),∥Vi∥Vi⟩)exp(η⟨∥f(x)∥f(x),∥Vk∥Vk⟩)
其中 f ( x ) f(\mathbf{x}) f(x) 是特征提取器的输出, ⟨ ⋅ , ⋅ ⟩ \langle\cdot, \cdot\rangle ⟨⋅,⋅⟩ 是内积, V k V_{k} Vk 是与 k k k 类相关的分类器权值(也称为类嵌入), η \eta η 是一个可学习的参数,它控制着概率分布的峰值性。
Hou 等人还解决了任务间混淆的问题。为了防止新类占据与以前任务中的类相似的位置,它们应用了边际排名损失。这种损失将当前嵌入远离 K K K 个最相似的类的嵌入,即:
L m r ( x ) = ∑ k = 1 K max ( m − ⟨ f ( x ) ∥ f ( x ) ∥ , V y ∥ V y ∥ ⟩ + ⟨ f ( x ) ∥ f ( x ) ∥ , V k ∥ V k ∥ ⟩ , 0 ) \mathcal{L}_{m r}(\mathbf{x})=\sum_{k=1}^{K} \max \left(m-\left\langle\frac{f(\mathbf{x})}{\|f(\mathbf{x})\|}, \frac{V_{y}}{\left\|V_{y}\right\|}\right\rangle+\left\langle\frac{f(\mathbf{x})}{\|f(\mathbf{x})\|}, \frac{V_{k}}{\left\|V_{k}\right\|}\right\rangle, 0\right) Lmr(x)=k=1∑Kmax(m−⟨∥f(x)∥f(x),∥Vy∥Vy⟩+⟨∥f(x)∥f(x),∥Vk∥Vk⟩,0)
其中 V y ^ \hat{V_{y}} Vy^ 指的是 x \mathbf{x} x 的真是累嵌入, V k ^ \hat{V_{k}} Vk^ 则是最近类的嵌入, m m m 是 margin。
最后,Belouadah和Popescu提出了另一种处理任务近期偏差的方法,其方法称为双记忆类IL(IL2M)。他们的方法与BiC相似,因为他们提出了校正网络预测的建议。然而,当BiC通过添加一个额外的层来学习纠正预测时,IL2M基于以前任务中保存的类预测的确定性统计数据进行修正。
定义 m = arg max y ^ ( x ) m=\arg \max \hat{\mathbf{y}}(\mathbf{x}) m=argmaxy^(x),他们计算前几类k的修正预测如下:
y ^ k r ( x ) = { y ^ k ( x ) × y ˉ k p y ˉ k t × y ˉ t y ˉ p if m ∈ C t y ^ k ( x ) otherwise \hat{y}_{k}^{r}(\mathbf{x})=\left\{\begin{array}{ll} \hat{y}_{k}(\mathbf{x}) \times \frac{\bar{y}_{k}^{p}}{\bar{y}_{k}^{t}} \times \frac{\bar{y}^{t}}{\bar{y}^{p}} & \text { if } m \in C^{t} \\ \hat{y}_{k}(\mathbf{x}) & \text { otherwise } \end{array}\right. y^kr(x)={y^k(x)×yˉktyˉkp×yˉpyˉty^k(x) if m∈Ct otherwise
其中 y ˉ k p \bar{y}_{k}^{p} yˉkp( p p p 指的是 past)是是训练首先学习 c k c_{k} ck 类的任务( c k ∈ C p c_{k}\in C^{p} ck∈Cp)后,所有图像的预测 y ^ k \hat{y}_{k} y^k 的平均值。 y ˉ p \bar{y}^{p} yˉp 是对该任务中所有类的预测的平均值。 y ˉ k p \bar{y}_{k}^{p} yˉkp 和 y ˉ p \bar{y}^{p} yˉp 在它们对应的训练阶段结束后,都直接存储。
类似的, y ˉ t \bar{y}^{t} yˉt 是对新任务中所有类的预测的平均值。可以看出,只有当预测的类是一个新的类( m ∈ C t m\in C^{t} m∈Ct)时,才会应用校正。如果预测的类是一个旧的类,作者认为不需要修正,因为预测不受任务不平衡的影响。
Relation between class-incremental method:
在前几节中,我们讨论了通过增量学习方法来减轻灾难性遗忘的主要方法。
我们在图4中总结了所讨论的方法之间的关系。从朴素的微调方法开始。在图中,我们展示了我们在第二节中比较的所有方法。
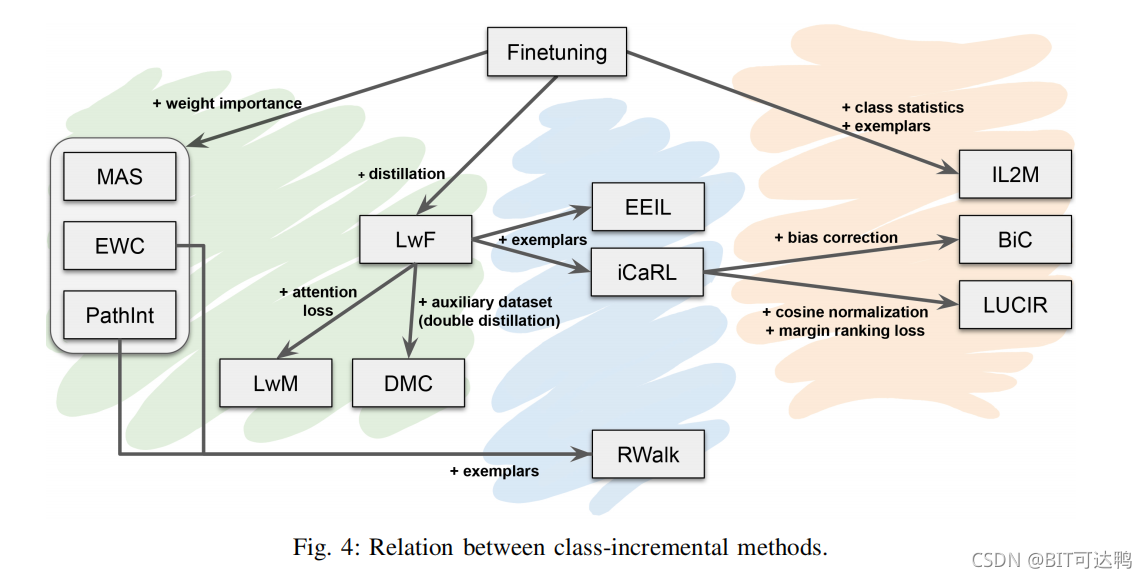
该图区分了使用范例保留知识的方法(蓝色、橙色)和无范例的方法(绿色)。
最值得注意的是,不忘记学习(LwF)对整个班级增量学习领域的巨大影响是显而易见的。然而,我们预计,最近的发现表明,当与范例结合时,微调可以优于LwF,可以在一定程度上减少其持续的影响。
权重正则化方法经常应用于任务IL设置,而对于类IL的使用明显较少。它们也可以用范例进行简单的扩展,我们将其结果纳入我们的实验评估中。
实验设置:
Code framework:
为了对不同的方法进行公平的比较,我们实现了一个通用的和可扩展的框架。数据集被划分为相同的分区,数据在每个任务开始时以相同的顺序排队。
所有与随机性相关的库调用都被同步并设置为相同的种子,这样所有方法的初始条件都是相同的。在训练过程中,没有来自之前任务的数据(不包括样本记忆)的数据,因此需要在完成任务的训练阶段之前选择任何基于稳定性-可塑性的权衡。
所有的方法都是使用原始作者的实现(如果可用的话)来实现的,我们将其适应于在下面提出的不同的实验设置(即不同的数据集和网络)下工作。
该代码的当前版本包括几种基线和以下方法的实现:EWC、MAS、PathInt、RWalk、LwM、DMC、LwF、iCaRL、EEIL、BiC、LUCIR和IL2M。该框架包括使用范例的功能来扩展大多数无范例的方法。该框架便于在各种网络架构中使用这些方法,并允许运行我们在本文中执行的各种实验场景。
Datasets:
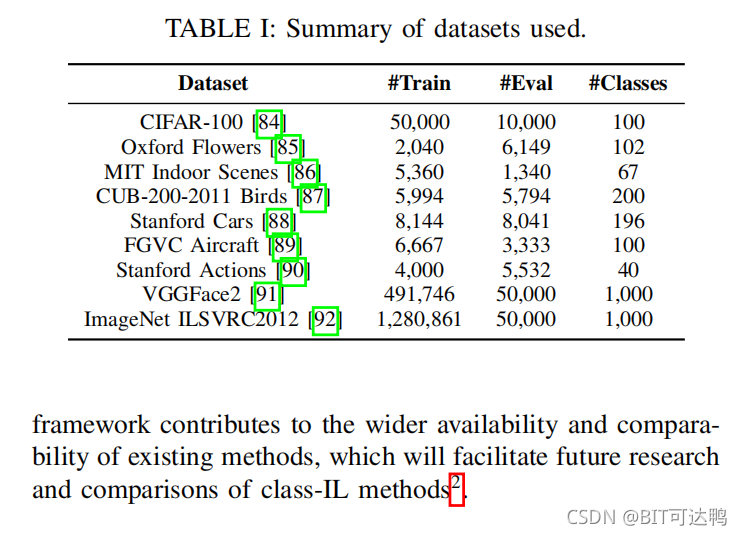
我们研究了IL方法进行图像分类对9个不同数据集的影响,这些数据集的统计数据汇总见表1。
Network architectures:
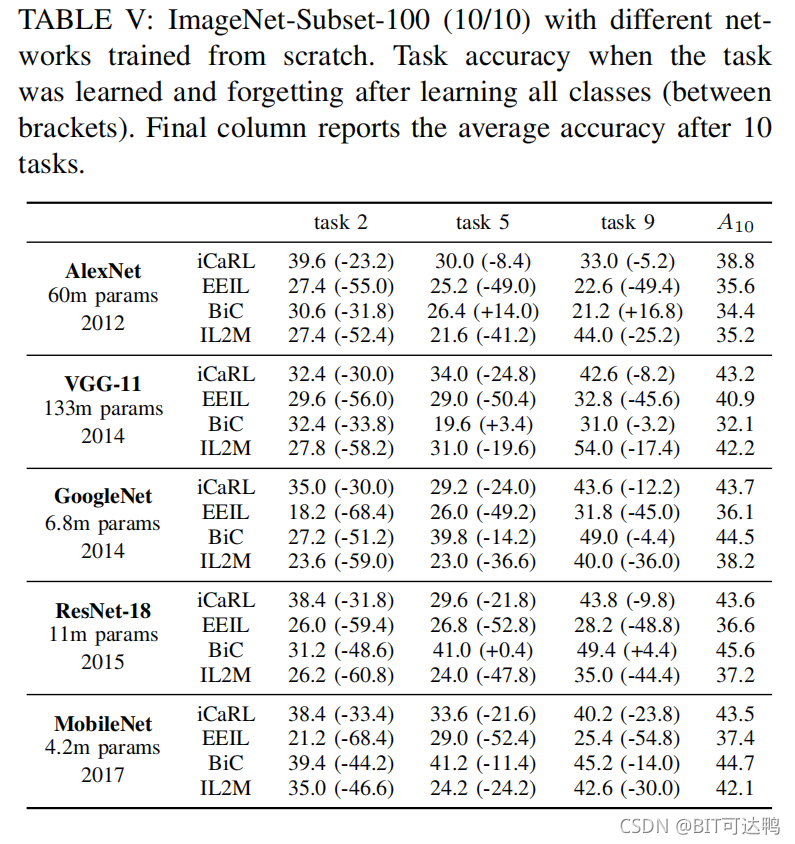
ResNet-32和ResNet-18在文献中通常分别用于CIFAR-100和分辨率更大的(输入大小约为224ˆ224ˆ3)的数据集。然而,在类增量学习中使用其他网络并不常见。在这项工作中,我们还在不同的网络上进行了实验,并评估了它们对性能的影响。
具体来说,我们使用了AlexNet、ResNet-18、VGG-11、GoogleNet和MobileNets。我们在不同的场景下使用不同的网络,并在ImageNet子集上进行了更广泛的比较。
Metrics:
在增量学习中, a t , k ∈ [ 0 , 1 ] a_{t,k}\in[0,1] at,k∈[0,1] 表示在学习任务 t t t 之后,任务 k k k 的准确率,其中 k ≤ t k\le t k≤t,它提供了关于增量过程的细粒度信息。
为了比较整体的增量学习过程,任务 t t t 后的平均精度定义为 A t = 1 t ∑ i = 1 t a t , i A_{t}=\frac{1}{t} \sum_{i=1}^{t} a_{t, i} At=t1∑i=1tat,i。
该度量通常用于比较具有单一值的不同方法的性能。必须注意的是,当任务有不同数量的类时,就需要使用一个加权版本。此外,虽然由于平均精度是一个单一的值,因此可以很容易地进行比较,但它也可以隐藏许多见解。
学习的任务越多,可以隐藏的信息就越多。为了解决这个问题,需要更多的指标来关注IL的选定关键方面,如遗忘度(forgetting)和不妥协度(intransigence)。
遗忘度估计模型在当前任务 t t t 中忘记了前一个任务 k k k 的程度,并被定义为:
f t , k = max i ∈ { 1 , … , t − 1 } a i , k − a t , k f_{t, k}=\max _{i \in\{1, \ldots, t-1\}} a_{i, k}-a_{t, k} ft,k=i∈{1,…,t−1}maxai,k−at,k
与准确性一样,这种测量方法可以对迄今为止学习到的所有任务进行平均: F t = 1 t − 1 ∑ i = 1 t − 1 f i t F_{t}=\frac{1}{t-1} \sum_{i=1}^{t-1} f_{i}^{t} Ft=t−11∑i=1t−1fit。
F t F_{t} Ft 值越低,在增量学习过程中发生的遗忘就越少。
同样地,不妥协度也量化了模型无法学习新任务的能力。两者都可以被认为是有助于理解稳定性-可塑性困境的补充措施。即在第一个任务后从未经过训练的模型的边界情况将不会忘记遗忘,但将无法学习新任务。
第 t t t 个任务的不妥协度计算为: I t = a t ∗ − a t , t I_{t}=a_{t}^{*}-a_{t, t} It=at∗−at,t
其中, a t ∗ a_{t}^{*} at∗ 是对所有数据进行联合训练的任务 t t t 的参考模型的准确性。 I t ∈ [ − 1 , 1 ] I_{t}\in[-1, 1] It∈[−1,1] 越低,完成该任务的模型就越好。
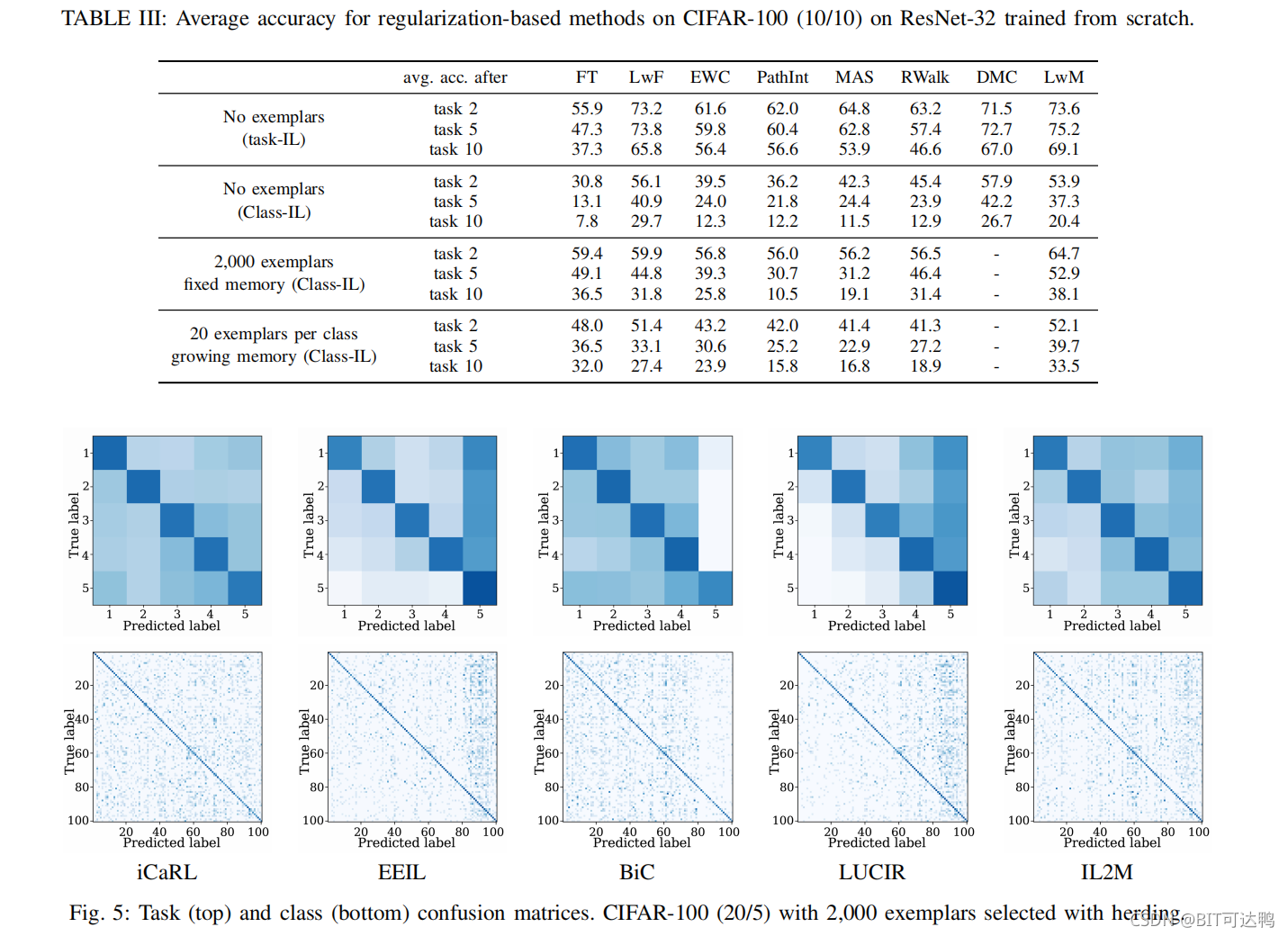
为了更深入地了解分类器的性能,可以使用一个混淆矩阵,它给出了每对类之间的误分类信息。尽管它不是一个单一的值度量,但它经常被用来总结一个分类器在许多增量任务中的行为。
实验结果:


















 2785
2785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











